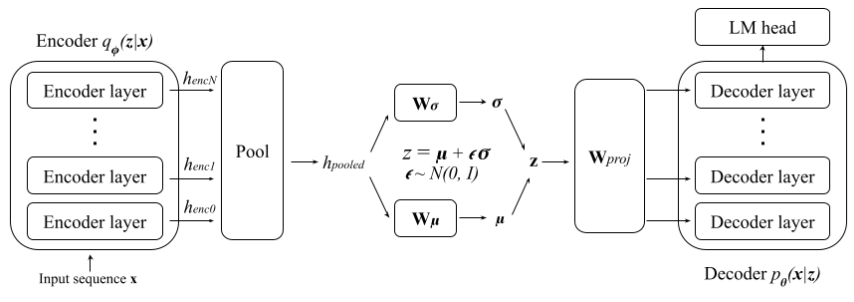
A Transformer-Based Variational Autoencoder for Sentence Generation (IJCNN 2019) Paper: https://ieeexplore.ieee.org/document/8852155 - Domain: Natural language generation
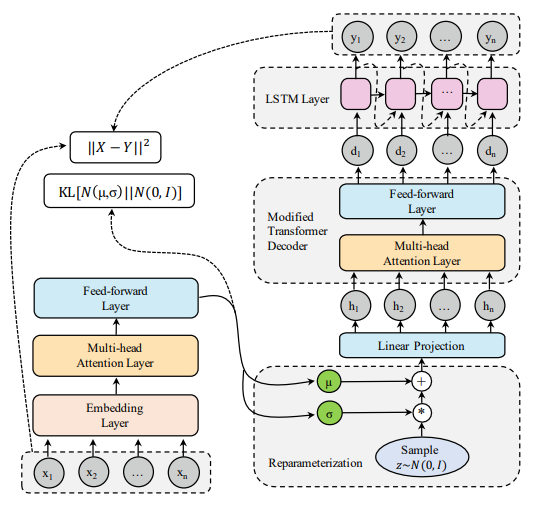
- RNN기반 VAE의 long-term input에 대한 posterior collapse와 같은 문제를 해결하고자함 - Encoder는 기존 transformer와 구조는 같고 출력이 Gaussian distribution - Test조건에선 decoder와 샘플링 파트만 사용한다고 가정하여 cross-attention 레이어는 제거하고 마지막에 autoregressive LSTM generator를 추가
Transformer VAE: A Hierarchical Model for Structure-aware and Interpretable Music Representation Learning (ICASSP 2020) Paper: https://ieeexplore.ieee.org/document/9054554 Related blog: https://mip-frontiers.eu/2020/08/20/transformer-vae.html - Domain: Music generation
- Structure awareness와 interpretability를 모두 만족하는 음악생성모델을 만들고자 함 - Encoder는 기존 transformer와 구조는 같고 네트워크 출력으로 입력 토큰 개수 만큼의 Gaussian distribution - Decoder역시 기존의 transformer구조와 같이 autoregressive한 구조이며, cross-atention을 encoder에서 샘플된 입력 길이 만큼의 latent varible과 수행
T-CVAE: Transformer-Based Conditioned Variational Autoencoder for Story Completion (IJCAI 2019) Paper:https://www.ijcai.org/proceedings/2019/727 Code:https://github.com/sodawater/T-CVAE - Domain: Story completion
- 문단의 맥락을 파악하여 빈 문장을 적절하게 생성하고자 함 - Encoder와 decoder의 입력이 같은 distrubution set이어서 layer를 공유함 - Encoder는 [나머지 문장; 생성중인 문장]을 self-attention하여 latent variable을 추론하고, decoder는 생성중인 문장을 [encoder 각 레이어 output; decoder의 output]에 cross-attention - generator는 deocoder의 output을 condition으로하면서 샘플된 z를사용하여 빈 문장을 autoregressive하게 reconstruction
Variational Transformer Networks for Layout Generation (CVPR 2021) Paper: https://arxiv.org/abs/2104.02416 Blog: https://ai.googleblog.com/2021/06/using-variational-transformer-networks.html - Domain: Layout design - 그럴듯한 레이아웃을 가능한 다양하게 생성하고자 함 - self-attention레이어가 주어진 레이아웃 내부의 element사이의 관계를 파악하며 representation distribution에 압축 - VAE에 Transformer의 attention mechanism을 추가하여 생성 레이아웃의 context이해와 다양성을 동시에 추구 - BERT의 auxiliary token과 같은 역할로서 encoder output을 bottleneck으로 사용 후 샘플된 z를 autoregressive decoder의 첫번째 입력으로 넣어줌 - Decoder는 cross-attention이 빠져 상대적으로 덜 expressive한 구조이지만 그 덕분에 posterior collapse는 줄어듬
Attention-based generative models for de novo molecular design (Chemical Science 2021) Paper:https://pubs.rsc.org/en/content/articlelanding/2021/SC/D1SC01050F Code:https://github.com/oriondollar/TransVAE - Domain: Molecular design - 분자 구조 생성에 있어서 RNN, RNN+Attention, TransformerVAE의 장단점을 비교하고자 함 - Encoder는 기존 transformer와 구조는 같고 출력부분에 Convolution bottleneck을 추가해 Gaussian distribution을 추론 - Decoder역시 기존의 transformer구조와 같이 autoregressive한 구조이며, cross-atention을 encoder에서 샘플된 입력 길이 만큼의 latent varible과 수행 - RNN + Attention 이 TransformerVAE보다 OOD에 더 잘 대응하는 반면, TransformerVAE가 더 interpretable 함
Transformer-based Conditional Variational Autoencoder for Controllable Story Generation (Arxiv 2021) Paper: https://arxiv.org/abs/2101.00828 Code: https://github.com/fangleai/TransformerCVAE - Domain: Story generation
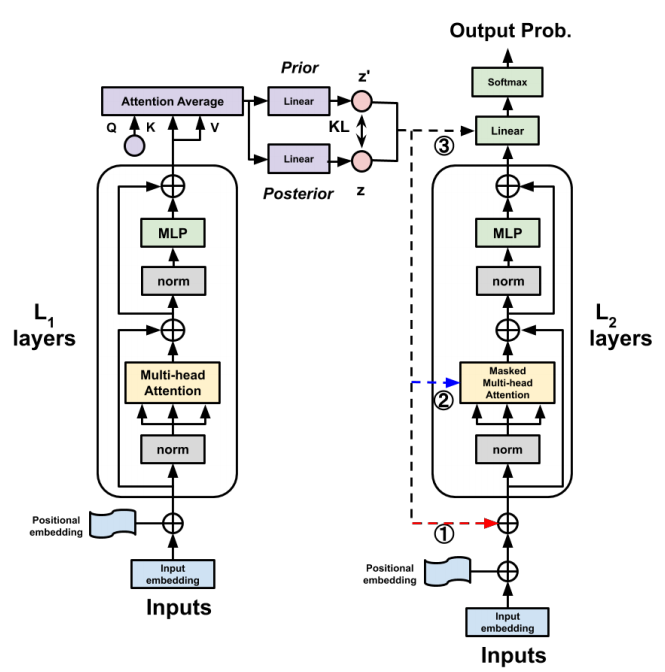
- Encoder는 unmasked/bi-directional self-attention 구조이며 출력부분에 attention-average block과 bottleneck을 추가해 Gaussian distribution을 추론 - Decoder는 GPT-2의 autoregressive한 구조이며, encoder에서 샘플된 latent variable을 1. input, 2. pseudo self-attention, 3. softmax에 전달하는 구조를 각각 시도 - Pre-trained model을 사용하여 posterior collapse 줄이려 시도
Finetuning Pretrained Transformers into Variational Autoencoders (Workshop on EMNLP 2021) Paper:https://arxiv.org/abs/2108.02446 Code:https://github.com/seongminp/transformers-into-vaes - Domain: Language modeling
- Posterior collapse를 보다 효과적으로 줄이고자 함 - Pretrained-T5 모델을 VAE에 사용하되 decoder는 self-attention없이 encoder에서 샘플된 z와 cross-attention만을 진행하여 decoder의 expressive power를 제한 - KL loss를 0으로 두고 학습한 후 full VAE를 학습하는 두 단계로 진행
Sequence 데이터에 대한 latent space를 형성하고자 하면서도 더 나은 context의 이해를 위해 attention을 사용하려는 시도에 대한 논문들을 훑어보았다.
대부분 크게 다르지 않았지만, decoder 부분 self-attention의 expressive power가 오히려 sequential VAE의 posterior collapse를 악화시킬수도 있기에 위 연구들 중에서는 이를 피하기위한 고민을 한 논문들과 context representation이 실제로 얼마나 잘 학습되었는지를 보여주는 논문들이 다른 연구들보다 상대적으로 의미있는것 같다.