
Author : Lili Chen, Kevin Lu, Aravind Rajeswaran, Kimin Lee, Aditya Grover, Michael Laskin, Pieter Abbeel, Aravind Srinivas, Igor Mordatch
Paper Link : https://arxiv.org/abs/2106.01345
Website : https://sites.google.com/berkeley.edu/decision-transformer
Hugging face: https://huggingface.co/blog/decision-transformers

- 바로 이전 포스팅인 Trajectory Transformer의 발표 딱 하루전에 먼저 발표된 논문.
(기본 개념이 거의 같은 관계로 이 논문은 정리보다 요약으로 대신하며, 많은부분 두 논문을 비교하고자 함) - Trajectory Transformer가 GPT아키텍처로 RL의 transitions들을 sequence modeling을 하여, 이전 trajectory가 input으로 들어갈때 미래의 trajectory $\tau$를 output으로 하는 모델이라면
- Decision Transformer는 input은 마찬가지로 trajectory이지만 output은 action $a$를 output으로 하는 모델이라는 차이가 있음.
- Trajectory Transformer와 마찬가지로 offline RL에서의 활용을 주로 삼고 있으나, Trajectory Transformer는 transformer 아키텍처를 planning을 위한 model로 쓰기때문에 model-based offline RL인 반면
- Decision Transformer는 transformer 아키텍처가 바로 action을 내뱉기 때문에 model-free offline RL.
- Decision Transformer가 추구하는 Offline RL의 예시를 그림으로 잘 설명해주는데, 아래와같이 그래프 navigation task에 대한 랜덤한 trajectory 데이터들이 주어져있을 때, 이 경로들을 stitching하여 새로운 최단 경로를 찾아내는것.

- 여기서 주의해야할 점이 있는데 바로 마지막 generation path에서 노란색 선 옆에 쓰인 return값이 -3이라는것으로, 데이터셋에 있는 return을 그대로 stitching하는 수준이지
- 이걸 마치 "두 스텝 이전이니 -2로 return을 생성해야 하는군" 처럼 모델이 이해한다던가 하는 데이터셋 이상의 trajectory를 생성하는건 아니라는 것. (DL유투버 Yannic Kilcher가 -2여야 할것같다고 영상에서 잘못 설명하기도)
- 이렇다 보니, 적절한 action을 생성하기 위해 의도적으로 return을 매번 감소시켜 입력해줘야하는 등 조금은 억지스러운 Transformer 아키텍처의 활용이 필요.
- 이런 점에선 Beam Search 알고리즘을 써서 Conservation과 Reward Maximization을 동시에 하는 Trajectory Transformer가 더 자연스러운 sequence model의 활용이지 않을까 싶음.
- 반면 Trajectory Transformer보다 실험을 매우 다양하게 했다는 장점이 있음
- Atari를 통해 high-dim과 long-term credit assignment의 성능을 확인

- D4RL 벤치마크를 통해 continuous control에서의 성능을 확인


- 이 실험은 Trajectory Transformer에서도 했는데다 두 논문에서의 대조군인 CQL성능이 거의 비슷해서 두 논문의 성능을 간접적으로 비교 가능함.

- 두 논문에서 차이가 가장 나는 부분은 replay buffer의 데이터인 "Medium-Replay(Decision Transformer) = mixed(Trajectory Transformer)"인데, Decision Transformer는 대체로 데이터셋의 최고성능보다 크게 뛰어난 성능을 못내는반면 Trajectory Transformer는 그 이상의 성능을 내는 모습을 보여줌.
- 실제로 Decision Transformer에서 return을 조절해가며 얼마나 잘 복원되는지를 분석한 결과, 아래와 같이 데이터의 분포를 있는 그대로 잘 학습했으나 데이터셋 최고성능 이상의 return을 조건으로 주었을땐 대부분의 환경에서 데이터셋의 성능을 upper limitation으로 갖는것을 확인함.

- 또한 과거의 context가 얼마나 중요한지를 확인함.
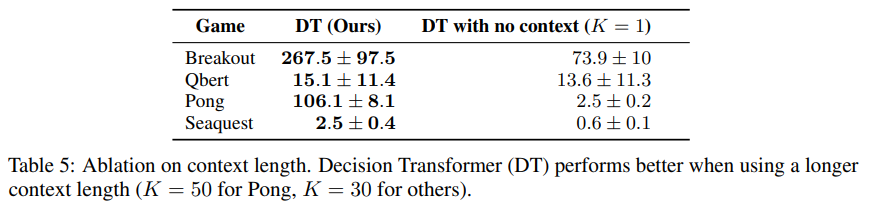
- Trajectory Transformer에선 Humanoid 환경에서 비슷한 실험을 했는데, long-term credit assignment가 상대적으로 안중요한 환경이어서인지 context의 길이가 크게 중요하지 않았음.
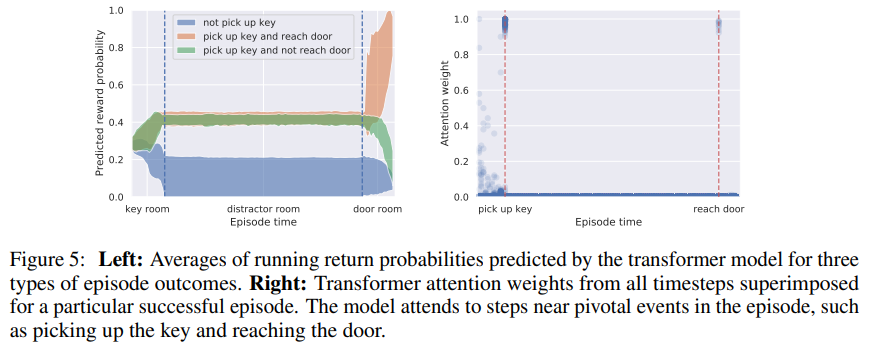
- Long-term credit assignment가 특히나 중요한 Key-to-Door 환경에서 실험을 해준 부분이 좋았는데, 아래와 같이 과거 context에 따라서 예측되는 reward가 크게 달라지는것을 볼 수 있으며, transformer 아키텍처의 장점인 attension map으로 이를 해석적으로 확인함.
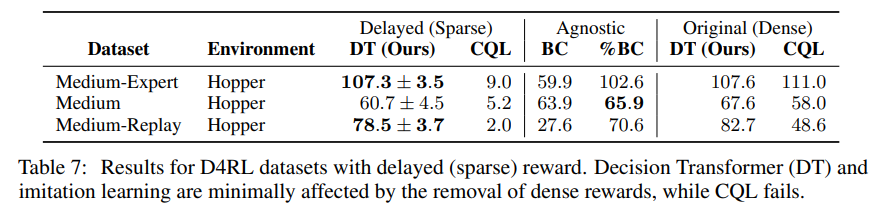
- 또한 sequence modeling 방식의 접근은 reward의 density가 상대적으로 덜 중요함에 따라 기존 bellman backup 및 policy gradient방식과 대비하여 sparse reward에서 큰 장점을 가지는것을 보여줌.
- 마지막으로 왜 pessimism이 필요 없는지에 대해선 Trajectory Transformer와 같이 value function을 approximate하는 과정에서 오는 오차가 없기 때문이라는 공통된 의견을 냄
개인적인 생각
- 위에서 중간중간 언급했다시피, 이렇게 데이터셋의 action을 생성하는 접근으론 stitching은 되겠지만 사실상 imitation learning에서 크게 벗어나지 않는 접근이 되어 데이터셋의 퀄리티에 영향을 받을수 밖에 없는것 같다.
- 때문에 transformer 아키텍처를 RL에 활용하는데엔, Trajectory Transformer 처럼, pre-trained language모델의 데이터에 대한 뛰어난 representation power에 집중하여 world model로서 잘 활용하고 발전시키는게 더 옳은 방향이 아닐까 싶다.
- 그럼에도 다양한 환경에서 실험을 하여 모델의 성질에 대해 구체적으로 분석을 한 점이 정말 좋았다.
- 또한 두 논문이 하루 차이로 나온것과 논문에서 하고자 하는 말이 거의 유사했다는 점이 재밌다.