
Author : Luisa Zintgraf*, Kyriacos Shiarlis, Maximilian Igl, Sebastian Schulze, Yarin Gal, Katja Hofmann, Shimon Whiteson
Paper Link : arxiv.org/abs/1910.08348
JMLR Paper(2021) : https://jmlr.org/papers/v22/21-0657.html
Talk in ICLR2020: iclr.cc/virtual_2020/poster_Hkl9JlBYvr.html
Talk in NeurIPS2020 Workshop: slideslive.com/38938211
0. Abstract
- 처음보는 환경에서 RL의 return을 최대화 하는데는 exploration과 exploitation의 trade off가 중요함
- Bayes-optimal policy는 현재 환경의 state를 고려할뿐만 아니라 현재 놓여진 환경의 불확실성까지도 고려하여 최적의 trade off를 선택함
- 하지만 Bayes-optimal policy를 계산하는 것은 작은 테스크에서만 가능하고 전체 테스크에 대해 계산하는것은 intractable함
- 본 연구에서는 처음보는 환경에서 action을 선택할때, 적절한 inference를 하면서도 실시간으로 task의 불확실성도 다루도록 meta-learning을 하는 Variational Bayes-Adaptive Deep RL (variBAD) 알고리즘을 제안함
1. Introduction
- Bayes-optimal policy는 현재 환경의 state를 고려할뿐만 아니라 현재 놓여진 환경의 불확실성까지도 고려하여, 처음보는 환경에서 최적의 exploration과 exploitation사이의 trade off를 선택함
- Bayes-optimal policy는 Bayes-adaptive Markov decision processes (BAMDPs) 프레임워크로 계산할 수 있으며, 환경에 대한 belief distribution을 가지고 이 불확실성을 낮추는 한편 return 최대화라는 RL의 목적에는 저해되지 않는 exploration을 함
- Bayse-optimal policy의 성능은 해당 환경을 완전히 알고 있을때의 최적 policy에 bound 됨
- 하지만 Bayes-optimal policy는 작은 task에서만 계산이 가능하며, 그외의 경우엔 intractable함
- 이에 대한 tractable한 대안으로는 posterior sampling (또는 Tompson sampling) 이 있음
- poterior sampling은 주기적으로 현재 MDP에 대한 가정(posterior)을 샘플링한 다음 이 가정을 전제로한 최적의 policy를 취함. 이 환경에 대한 가정은 다음 샘플링까지 유지됨
- 하지만 이러한 posterior sampling에 의한 exploration은 매우 비효율적이므로 Bayes-optimal과는 크게 차이남.
- 이 차이는 아래의 목표지점이 숨겨진 grid world 예시를 통해 볼 수 있음

- (a) 목적지는 x이나 모르는 영역을 의미하는 회색 중 한곳에 해당
- (b) Bayes-Optimal 의 경우에는 에이전트가 아직 불활실성이 있는곳을 탐색하며 구조적인 행동을 취함
- 목적지를 모르는 상태에서 목적지가 있을거라고 생각하는 모든칸에 동일한 확률 (회색의 명도) 를 부여
- 한편 (c) Posterior Sampling의 경우에는 목적지에 대한 가정을 샘플링 (빨간색 칸) 하고, 여기를 가기위한 최적의 행동을 취함. 그리고 데이터를 바탕으로 posterior를 업데이트한 뒤 다시금 샘플링 반복함.
- 이는 샘플링에 따라서 이미 지나온 길을 중복으로 가는 등, 불확실성이 최적으로 줄어들지 않는 비효율적인 탐색임
- (d)는 본 연구가 제안하는 알고리즘의 탐색과정으로, 1개 에피소드당 15번의 step을 간다고 할때 (e)의 비교에서 Bayes-Optimal에 근접하는 효율을 보여줌
- 본 연구에서는 이러한 처음보는 (하지만 서로 어느정도는 기존 환경들과 공통점이 있는) 환경에 대한 효율적인 탐색 문제를 Bayesian RL, variational inference, 그리고 meta-learing으로 해결하고자 하며, 제안한 알고리즘을 variational Bayes-Adaptive Deep RL (variBAD) 이라고 명칭함.
2. Background
- 기본적인 RL에 대한 내용은 생략
2.1. Traning Setup
- 일반적인 meta-learing의 셋업과 같이 MPDs의 분포 $p(M)$을 가정하고 meta-training동안은 이 분포에서 MDP $M_i \sim p(M) $ 을 샘플링함
- 이때 $M_i = (S, A, R_i, T_i, T_{i,0}, \gamma, H)$, 이며 $i$는 각 task를 의미
- Meta-training 동안엔 각 task에서 batch 데이터가 반복적으로 샘플링 되며, 이후 수집된 데이터를 통해 전체 tasks에 대해 에이전트가 더 높은 성능을 내도록 학습하는 learning to learn 과정이 진행
- Meta-test 동안엔 새로운 task에 대해서 agent가 적응하는 모든 과정에 대한 평균적인 retrun을 평가기준으로 삼음
- 이러한 meta-framework가 잘 동작하려면 다음의 두 가지가 필요함
1. 현재 task와 관련된 task들로 부터 얻은 prior 지식의 활용
2. Exploration과 eploitation의 trade off를 위해 행동을 선택할때 task의 불확실성을 추론
2.2. Bayesian Reinforcement Learning
- Bayes-optimal policy는 Bayes-adaptive Markov decision processes (BAMDPs) 프레임워크로 계산할 수 있으며, 환경에 대한 belief distribution을 가지고 이 불확실성을 낮추는 한편 return 최대화라는 RL의 목적에는 저해되지 않는 exploration을 함
- RL의 베이지안 형태에서는, reward와 transition이 prior $b_0 = p(R,T)$에 따라 분포 해 있다고 가정
- 또한 reward와 transition을 모르므로, 에이전트는 지금까지 한 경험 $\tau_{:t}=\left\{s_0, a_0, r_1, s_1, a_1, \cdots, s_t\right\}$ 에 대한 posterior인 belief $b_t(R,T)=p(R,T|\tau_{:t})$를 유지함
- decision making을 할때 이러한 task에 대한 불확실성을 고려하게 하려면, belief space를 state space에 추가함. 즉, task belief가 포함된 새로운 state space인 hyper state를 정의 $s_{t}^{+} \in S^+= S \times B$
- 이를 기존 RL objective 에 적용한, BAMDP framework의 RL objective는 다음과 같음.
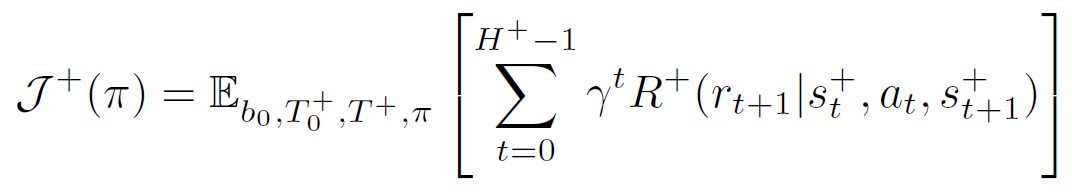
- 이 objective를 최대화 하는것이 Bayes-optimal policy이며, 자동으로 exploration과 exploitation을 조절해줌
- 즉, 불확실성을 낮추면서도 return을 최대화 하는 행동을 취함
- 하지만 이 최적화 문제를 푸는것은 intracterbla한데, 주요 원인은 다음과 같음
1. 처음보는 MDP의 reward 와 transition모델을 모름
2. Posterior의 계산은 주로 interactable함
3. Posterior를 잘 도출하더라도 belief space상에서의 planning 역시 주로 interactable함 - 이를 해결하기위해 저자는 reward와 transition, 처음보는 MDP에서 어떻게 inference를 할지, 그리고 task belief를 online return을 최대화 하는데 어떻게 활용할지를 동시에 meta-learn하는 방법을 제안
- Inference기반으로서 planning없이 end-to-end로 동작하는 접근방법을 제안함
3. VariBAD: Bayes-Adaptive Deep RL via Meta-Learning
- 여기선 이 paper의 핵심 concept인 variBAD를 설명하고자함
- 먼저 처음보는, 즉 모르는 MDP의 reward와 transition을 표현하기위 해서 stochastic latent variable $m_i$를 사용하여 다음과 같이 쓸 수 있음
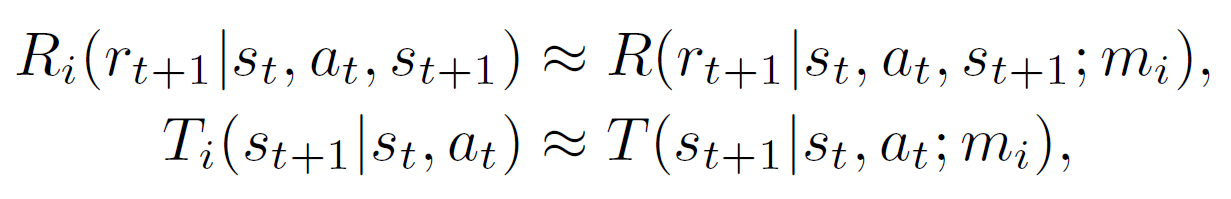
- 이전 챕터에서 문제로서 언급한 바와같이 이러한 unknown MDP는 reward와 transtion 모델 그리고 index를 모르므로, 여기선 대신 $\tau_{:t}^{(i)}=(s_0, a_0, r_1, s_1, a_1, r_2 \cdots, s_{t-1}, a_{t-1}, r_t, s_t)$ 의 에이전트가 time step $t$까지 경험한 context를 바탕으로 $m_i$를 infer함
- 즉, posterior distribution $p(m_i|\tau_{:t}^{(i)}$를 infer하는 방법으로 posterior가 intractable한 문제를 다룸과 동시에 unknown MDP의 reward와 transition을 infer된 stochastic latent variable로 parameterize 함
- Posterior $q_\phi(m|\tau_{:t})$는 latent variable을 embedding하는 encoder의 역할로서 RNN 아키텍처를 가지며decoder를 붙여 학습함.
- 이때 representation learning이 잘 되도록 decoder는 이전 state와 action이 들어왔을때 reward와 transition (dynamics) 을 잘 복원하도록 아키텍처를 구성함.
- 또한 policy는 task의 불확실성을 의미하는 posterior에 근거하여 현재환경에서의 행동을 선택함
- VariBAD 아키텍쳐를 그림으로 나타내면 다음과 같음

3.1. Approximate Inference
- 처음보는 MDP의 transition과 reward를 모르며 모든 task에 대한 marginalising을 하는것은 불가능하므로 posterior를 정확히 계산하는것은 intractable함
- 따라서 위에서 언급한 encoder-decoder구조를 사용한 posterior의 근사가 필요하며, 이는 VAE에서 사용한 접근법과 같음 (VAE는 유재준 박사님의 포스팅이나, 이기창님의 포스팅 참고)
- $\theta$로 parameterized된 MDP의 dynamics 모델 $p_\theta(\tau_{:H^+}|a_{:H^+-1})$ 즉 decoder와 $\Phi$로 parameterized된 inference network $q_\Phi(m|\tau_{:t})$ 즉 encoder가 조합된 구조는 매 time step $t$마다 실시간으로 latent task $m_i$를 infer하는것이 가능하도록 함
- VAE의 ELBO objective형식으로 recontruction loss와 KL regulation loss를 구현해 보면, 복원하려는것이 행동선택에 따른 trajectory이므로 아래와 같음. 정확힌 dynamics를 복원하는것이므로 이때 $\tau$는 dynamics의 입력변수에 해당하는 행동정보는 포함하지 않음
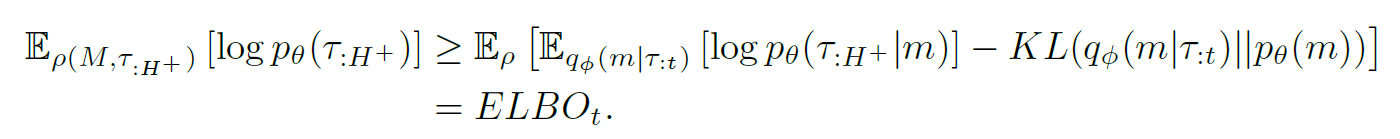
- 여기서 기존의 VAE와는 사뭇 다른 부분은 informational bottleneck 부분인데, 단순히 prior를 정규분포로 두던 VAE와는 달리 task를 포함한 hyper state에서는 처음 prior는 동일하게 $q_\Phi(m) = \mathcal{N}(0,I)$으로 주지만 이후부턴 이전 posterior인 $q_\Phi(m|\tau_{:t-1})$를 prior로 줌. 이는 posterior inference distribution이 task에 따라 adaptation되도록 하기위함
- 또한 주목할 부분은 latent variable $m$이 추론되기위해 encoder가 사용한 정보는 과거의 정보이지만 $m$을 토대로 decoder가 복원하려는 정보는 과거와 미래를 포함한 전체 trajectory $\tau_{:H^+}$ 라는 점
- 즉, 단순히 과거의 데이터를 representation하는것이 아닌, 과거의 데이터로부터 가보지 않은 state 또한 잘 추론 할 수 있도록 학습하는것으로, 이를통해 더 좋은 exploration을 위한 representation을 학습함
- ELBO에서 reconstruction term은 구체적으로 다음과 같이 풀어쓸 수 있음
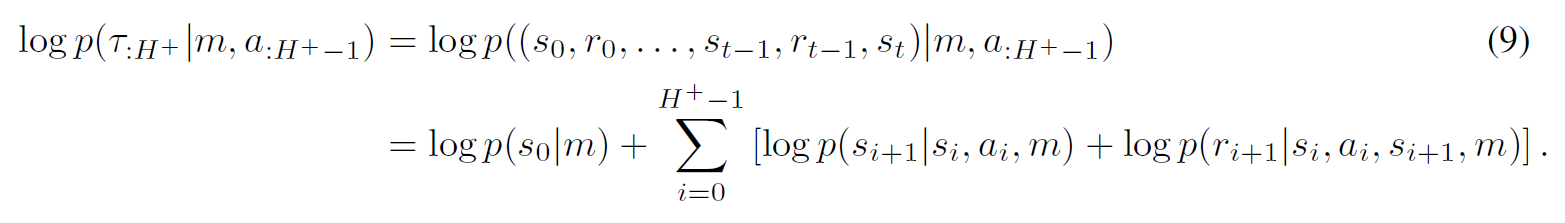
- 이는 기존 VAE처럼 단순히 latent variable로부터 state와 reward를 복원하는 형태가 아닌, decoder에 이전 state와 action을 넣었을때 다음 state와 reward를 복원하는 interaction을 decoder가 학습하는것으로 dynamics 및 MDP를 inductive bias로 주어 representation learning하는 구조가 됨
3.2. Training Objective
- 위에서 언급한 아키텍처는 DNN으로 구현되며, 다음과 같음
1. $\Phi$를 파라메터로 갖는 encoder 역할의 posterior inference network $q_\Phi(m|\tau_{:t})$
2. $\theta$를 파라메터로 갖는 decoder 역할의 근사 환경모델 transition $T^{'}=p_\theta^T(s_{i+1}|s_i,a_i;m)$ 과 reward $R^{'}=p_\theta^R(r_{i+1}|s_t,a_t,s_{i+1};m)$
3. $\Phi$에 의존하여 $\psi$를 파라메터로 갖는 policy $\pi_\psi(a_t|s_t,q_\Phi(m|\tau_{:t}))$ - Posterior는 distribution의 파라메터로 표현 가능 (e.g., $q$가 가우시안일 경우 평균과 표준편차)
- 이를 종합하여 알고리즘의 최종 objective는 다음을 최대화 하는 것
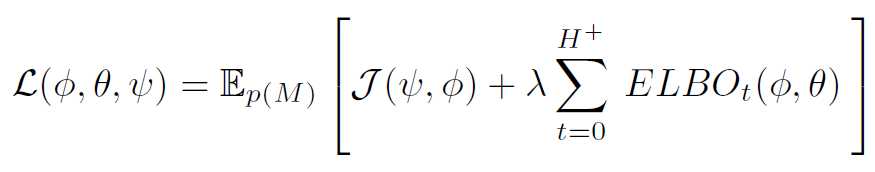
- 위 expectation은 Monte Carlo 샘플로 근사가 되며, $ELBO$는 VAE에서도 사용된 reparameterisation trick으로서 역전파를 통한 학습이 가능
- 위에서 언급한 바와 같이 $ELBO$의 범위는 모든 가능한 context length $t$이고, 이렇게 함으로써 variBAD는 episode 중에 실시간 online adaptation이 가능해지며 데이터가 쌓일수록 환경에 대한 uncertainty가 줄어듬
- 실제 구현에서는 $H^+$가 너무 클 수 있으므로 고정된 상수 만큼의 subsampling을 사용함
- 위 objective는 end-to-end로 학습되며 $\lambda$는 Reinforcement Leraning ojbective와 Represention Learning objective사이의 weight 파라메터임
- Policy가 posterior$\Phi$에 의존하는 만큼 RL loss는 encoder로도 타고 들어갈 수 있지만 별 효용이 있진 않으므로 실제 구현에선 역전파를 끊어주는것이 학습속도 측면에서 더욱 효율적이면서도 loss간 trade off 문제를 피할 수 있고 loss간 gradient가 간섭되는것도 예방할 수 있음
- 때문에 이후 실험에선 VAE와 policy를 서로 다른 optimizer와 learning rate를 사용함
- 또한 RL과 VAE를 다른 buffer를 사용하여 학습하는데, 이는 여기서 사용되는 RL알고리즘이 on-policy라 최근 데이터를 사용해야하는 반면 VAE는 전체 데이터를 사용하기 때문
- Meta-test에선 랜덤하게 test task가 샘플되며 학습된 encoder와 policy가 gradient step없이 forward pass로만 adaptation 함
4. Related Work
- 기존 meta-RL에는 여러 방법이 있는데, $\textrm{RL}^2$와 같은 blackbox 방법 역시 RNN을 사용한다는 공통점이 있지만, variBAD는 decoder가 붙어 단순히 hidden black box가 아니라 의도한 uncertainty 정보를 latent variable에 담기위한 representation learning이라는 차이점이 있음
- 이 외에도 MAML과 같은 gradient step 방식의 meta-RL 알고리즘들과 비교해보면, 이 방법들은 feedforward policy만을 사용해 모델이 더 가볍다는 장점이 있으나 RNN 모듈을 사용하는 $\textrm{RL}^2$ 나 variBAD 는 구조적으론 복잡하지만 online adaptation이 가능하다는 큰 장점이 있음
- Task embedding의 측면에서 다양한 기존 접근방식의 연구들이 있으나, variBAD는 task uncertainty를 unsupervised하게 representation learning한다는 것과 이를 policy가 의존함에따라 exploration과 exploitation의 trade off가 자동으로 된다는 차이점이 있으며 이러한 자동화된 trade off는 Bayes-optimal에 부합함
- Bayesian RL의 측면에서 poterior나 prior를 활용한 연구가 여럿 있으나, variBAD의 차별점은 posterior를 업데이트 하는 방법 즉, inference과정을 meta-learn하는것임
- BAMDPs는 POMDPs이 특수 케이스로 hidden state가 transition과 reward function을 내포하고 있으며 에이전트가 이에대한 belief를 고려하는것을 말함. 단, 일반적인 POMPDs는 hiddent state가 매 step 실시간으로 변할 수 있지만 BAMDP의 hidden task state는 task마다 고정됨
5. Experiment
- 실험은 두가지 환경에서 진행되며 Gridworld에서는 variBAD가 structured exploration을 하는지를, 그리고 MuJoCo에서는 fast adaptation, 즉 첫번째 rollout에서 task에 잘 adaptation을 하는지를 증명하고자 함
- 아래 실험들에서 variBAD는 A2C알고리즘을 사용함
5.1. Gridworld
- 5x5 gridworld에서 랜덤하게 목적지가 선택되며 에이전트엔 알려주지 않아 탐색이 필요함
- 에이전트는 매 에피소드마다 왼쪽 하단에서 시작하여 15 step 을 움직이고 다시 위치가 리셋 됨 '
- 학습의 목표는 에이전트가 4개 에피소드 안에 목적지에 도착하는 것
- 즉, MDP는 horizon은 $H=15$ 이나 meta-task에 대한 BAMDP의 horizon은 $H^+=4 \times H=15$가 됨
- 에이전트는 골이 아닌 칸을 지날땐 -0.1의 reward를 받으며 목적지칸에 도착하면 +1을 받음
- latent variable의 dimension은 5로 gaussian posterior를 사용하면 mean과 s.d. 각각의 10이 됨

- 위 (a)의 실험 결과에서 보면, infer된 posterior belief를 approximated reward function에 입력으로 주어 각 칸이 목적지일 belief를 흰색-파란색으로 시각화 했으며 흰색은 확률이 0을 파란색이 진해질수록 목적지일 확률이 커지는것으로 보면 됨
- step을 움직임에따라 지나간 칸의 확률은 0이 되고 남은 칸들의 확률은 올라가는것을 볼 수 있음에따라 variBAD가 belief를 실시간으로 embedding하도록 잘 학습된것을 확인할 수 있음
- 또한 belief가 바뀜에 따라 에이전트가 방문하지 않은 곳을 선택하는 모습에서 structured exploration이 잘 학습된것을 볼 수 있음
- 위 (b)에서는 belief의 변화에 따른 gridworld 각 칸의 예상 reward가 1일 확률을 시각화 했으며 (c)에서는 latent variable, 즉 belief disbribution을 시각화 함
- 에이전트가 데이터를 탐색과 경험을 할수록 각 칸이 목적지일 확률이 하나 둘 0이 되는것을 볼 수 있으며, 약 20step이후엔 목적지에 해당하는 칸의 확률이 1에 수렴하는것을 볼 수 있음
- 마찬가지로 에이전트가 목적지를 찾음에 따라 그 이후엔 belief distrubution의 평균이 더이상 변하지 않고 표준편차는 대부분 0에 수렴하는것을 볼 수 있음
- 결론적으로, variBAD알고리즘이 처음보는 환경에 대한 exploration과 exploitation을 trade off하는 Bayes-optimal policy와 거의 유사하게 행동하는것을 볼 수 있음
5.2. Sparse 2D Navigation
- 반지름1인 반원을 따라 램덤하게 목적지가 생기며, 목적지로부터 0.2거리 안에 들어갈 경우 sparse한 보상을 받는 navigation 환경
- Bayes-optimal behavior은 반원을 따라 탐색을 하는것

- PEARL과 비교하면 variBAD가 meta-test에서 훨씬 빠르게 목적지에 도착했으며 RL2와 비교하면 training (3 epi)보다 더 길게 rollout을 했을 경우에서 훨씬 안정적인 움직임을 보여줌
- PEARL은 posterial sampling을 하기때문에 각 episode내에서는 고정된 belief로인해 비효율적인 반복행동을 취하는 반면, variBAD는 한개의 episode 내에서도 belief를 업데이트 해가며 전략적인 탐색을하는 bayes-optimal에 가까운 모습을 줌
5.3. MuJoCo Continuous Control Meta-Learning Tasks
- 같은 meta-RL 알고리즘인 PEARL에서 사용된 MuJoCo locomotion task 4개에 대해서도 variBAD를 검증함
- AntDir과 HalfCheetahDir task는 에이전트로 하여금 forward와 backward 두개 방향을 달리도록하는 양방향의 두개 task를 가각 가지고 있음
- HalfCheetahVel task는 에이전트가 여러 속도로 달리는 환경이며, Walker task는 에이전트의 dynamics 파라메터가 랜덤으로 정해지는 환경임
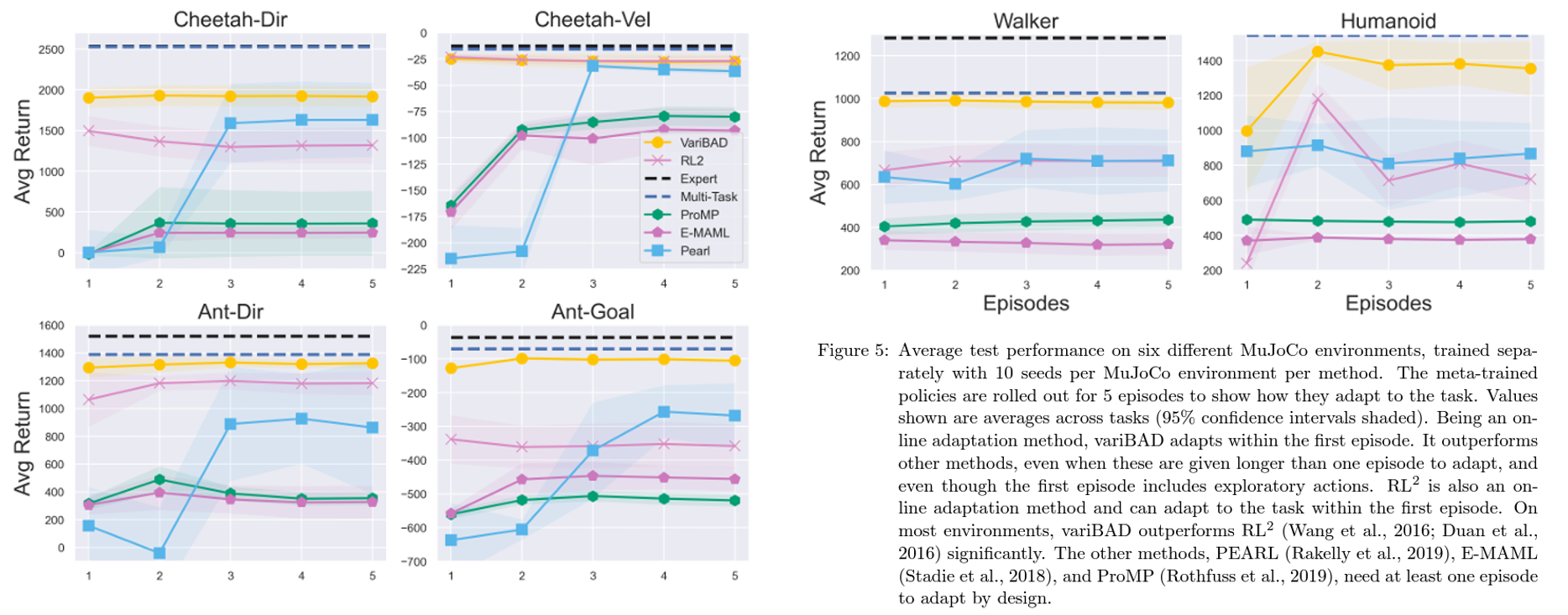
- 위 결과는 기존의 각 task에 대해 meta-test에서의 adaptation 퍼포먼스를 기존의 meta-RL 알고리즘들과 비교한것을 보여줌
- Expert은 PPO알고리즘으로 각각의 task에대해 model free 학습한 평균 결과이며, Multi-task는 task desctiption을 준 multi-task agent를 의미
- 모든 task에서 $\textrm{RL}^2$와 variBAD를 제외한 다른 알고리즘들은 첫번째 에피소드에서 낮은 성능을 보여주었으며, 이는 해당 알고리즘들이 variBAD나 $\textrm{RL}^2$와 같은 실시간 adaptation이 아닌 few step혹은 episode단위의 adaptation이기 때문임
- $\textrm{RL}^2$역시 첫 에피소드에서 variBAD보다 낮은 성능을 보여주었으며 adaptation에 따른 성능향상이 미미하고 RNN policy로인해 학습이 오래걸리며 성능이 불안정하다는 확실한 단점이 있음
- PEARL(포스팅)은 대표적인 posterior sampling알고리즘으로 약 세번째 에피소드부터 좋은 성능을 보여줌
- 결과적으로 variBAD는 단일 에피소드만으로도 충분한 빠른 adaptation을 보여주면서도 multi-task에 가까운 성능을 보여줌
- 단, MuJoCo에선 (dynamics가 변하는 Walker포함한 경우에도) transition decoder를 함께 사용하는것보다 reward decoder만 사용하는것이 더 좋은 성능을 보여주었으며 위 그래프는 단일 decoder를 사용해 학습한 결과임
5.4. Meta-World
- 좀더 다양한 task에 대한 generalization을 다루는 로봇팔 benchmark환경인 Meta-World ML1에서 성능 검증
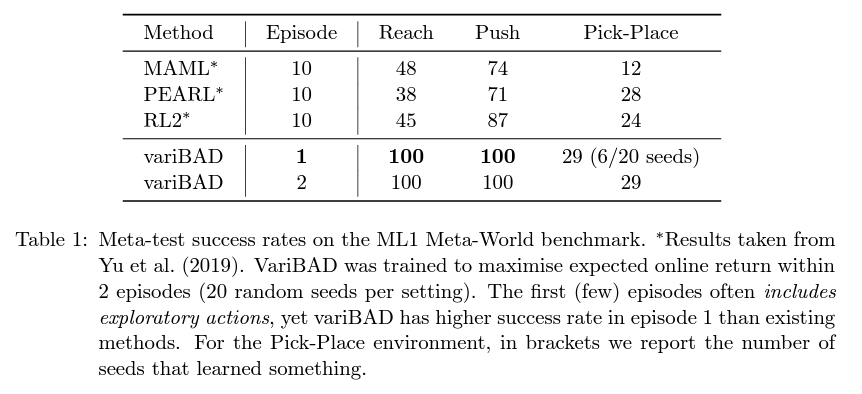
- Reach와 Push 문제를 모두 해결하면서 큰 차이로 기존 알고리즘들보다 빠르면서도(2 episode이내) 뛰어난 성능을 보여줌
- 어려운 문제인 Pick-Place에서는 PEARL과 유사한 성능을 보여주었는데, 이는 meta-training에서 탐색이 부족 (meta-exploration challenge)하여 생기는 한계로 저자는 추정
6. Empirical Analysis
6.1. Modelling Horizon
- VAE에서 reconstruction을 전체 다 하는 경우(variBAD)와 과거만 하는 경우, 미래만 하는경우, 그리고 1step미래만 하는 경우에 대해 결과를 비교분석함
- 이미 관측된 transition과 앞으로 관측할 transition의 분포를 모두 belief에 담고자한것이 variBAD에서 주장한 모델링의 이유
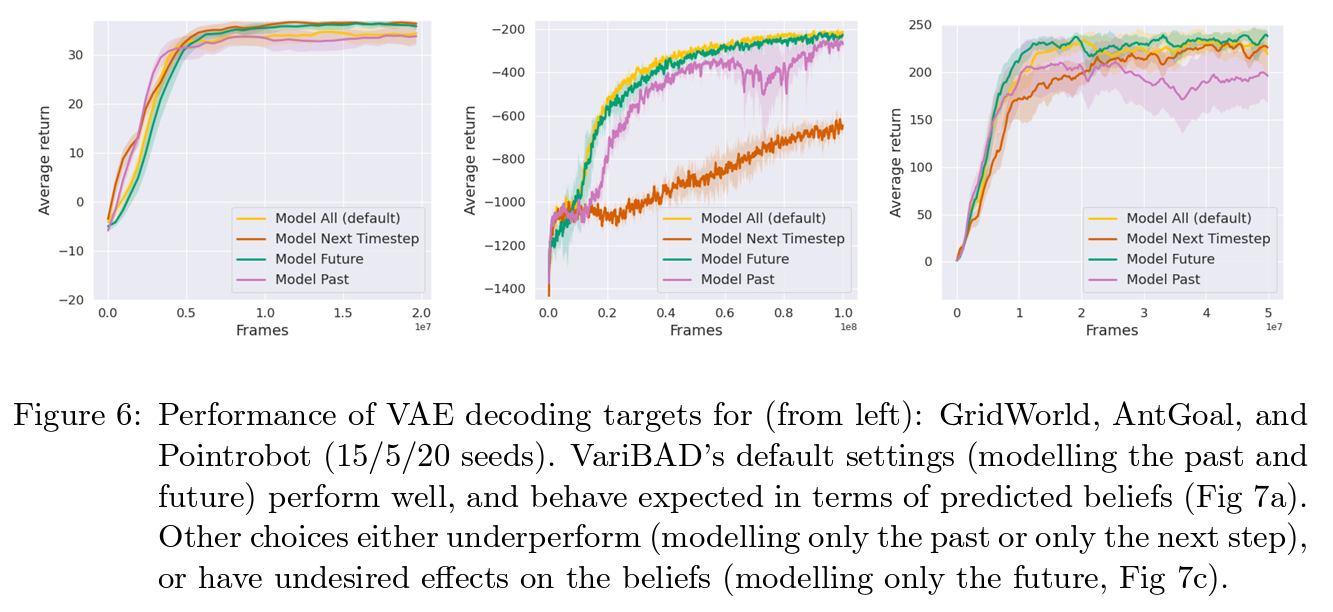
- 실험 결과 origial VAE와 같이 과거만 복원하는것은 suboptimal성능을 보여주었고, 다음 step만 복원하는것은 AntGoal에서 낮은 성능을 보여줌
- 미래만을 복원하는것은 성능상으로는 괜찮았지만 아래 Gridworld실험을 통해 이 역시 부족한 점이 있다는것을 확인

- GridWorld에서 과거만 복원하거나 다음 step만 복원하는것은 목적지에 도착하기 전까지 잘못된 belief를 학습 (Figure 7b,d)
- 미래를 복원하는것은 방문전인 state들에 대한 reward belief를 나쁘지 않게 학습하였지만, 이미 방문한 상태에 대에선 잘못된 belief를 보여줌 (Figure 7c)
6.2. KL Regularisation
- VAE에서 KL term을 origial VAE와 같이 고정된 normal distribution으로 할 경우, 이전 posterior를 piror로 하여 서로 닮도록 하는 경우 (variBAD), variBAD과 같이 이전 posterior를 prior로 활용하나 gradient는 끊어주는경우, KL term을 제거할 경우에 대해 비교분석함
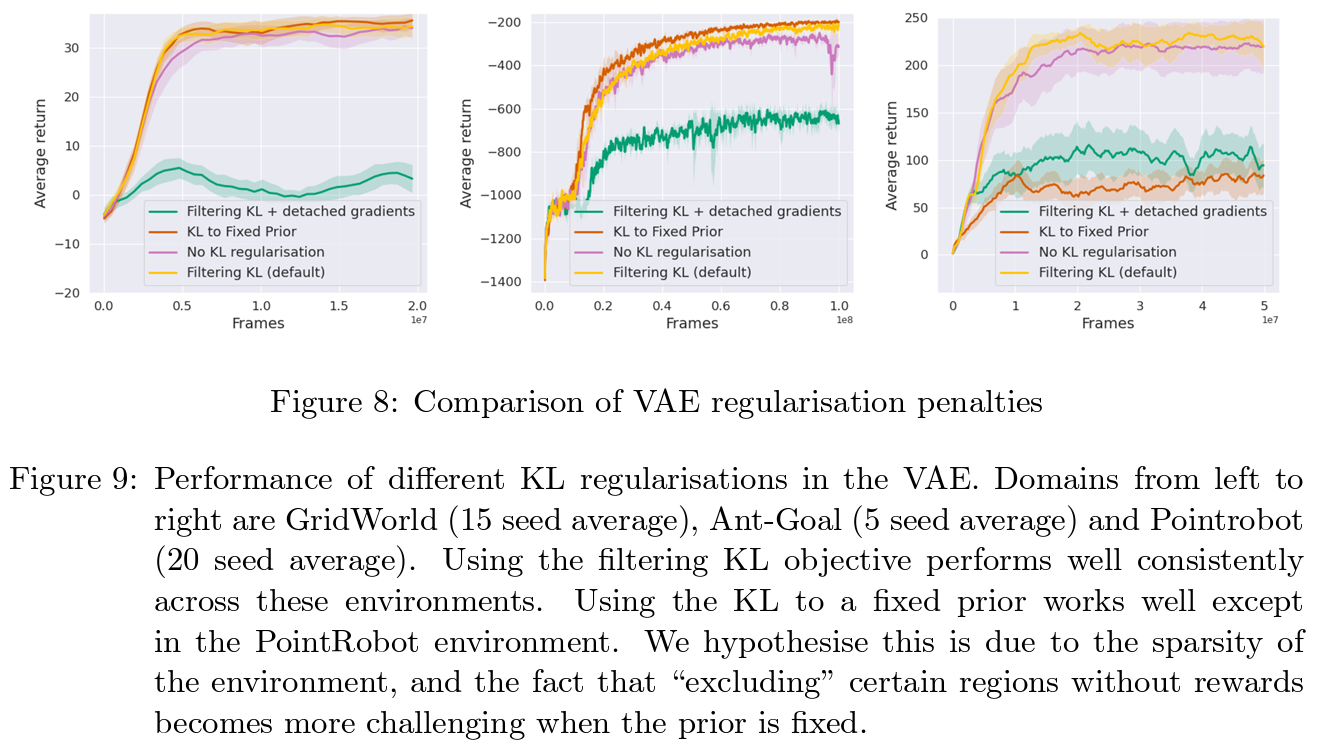
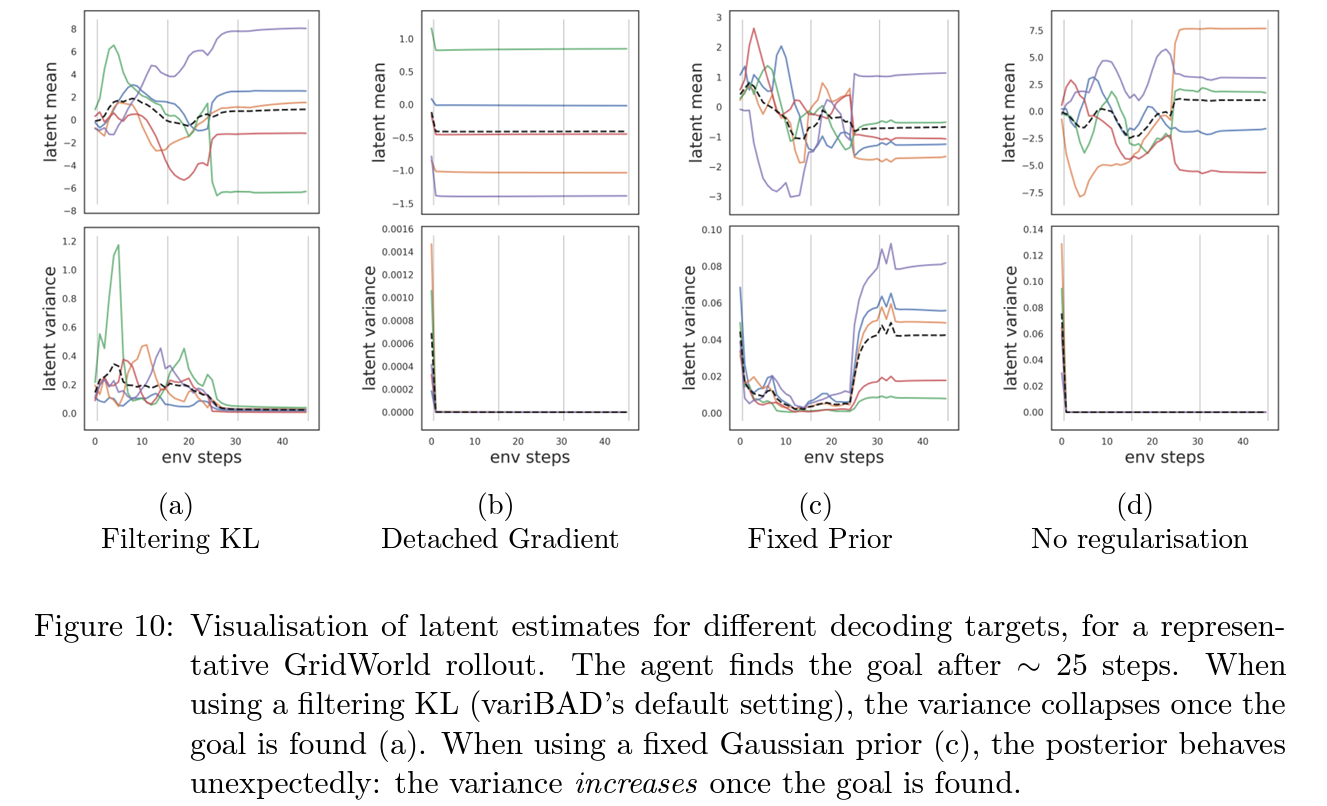
- 고정된 prior를 사용할 경우, 성능적으로는 dense reward에선 괜찮고 sparse reward에선 안좋았으나 variance를 분석해보면 normal distribution에 과잉 fitting되려하여 Gridworld에서 목표점에 도달직후 variance가 확 증가함
- KL을 사용하지 않을경우 variance가 학습이 전혀 되지 않음
- Grandient를 detach할 경우엔 성능면에서나 variance면에서나 모두 나쁜 결과를 보여줌
6.3. Belief Demensionality
- Latent dimension이 바뀜에 따라 성능이 어떻게 변하는지를 실험함
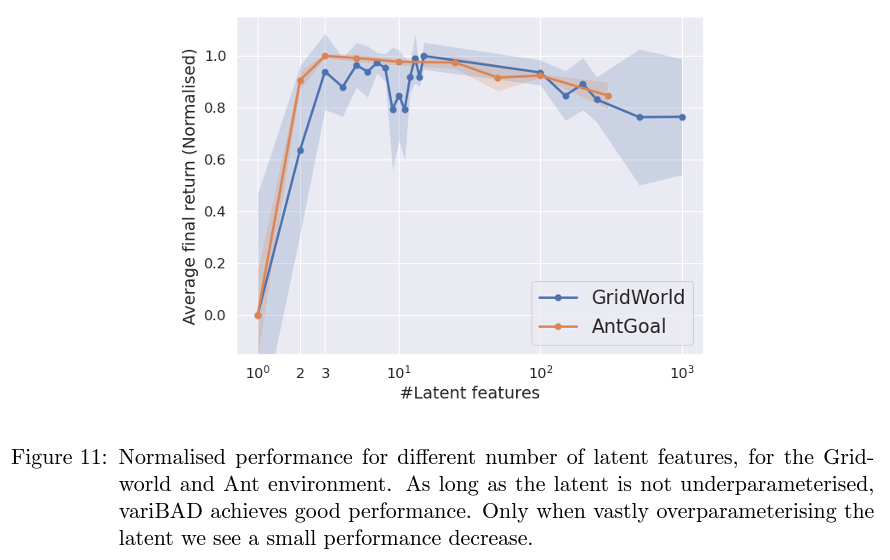
- 실험결과, 아주 작은 dimension으로 인한 underparameterised가 아닌 이상 latent dimension의 크기는 큰 영향을 주지 않았으나, 조금이지만 서서히 성능이 줄어들긴 함
7. Conclusion & Future Work
- 본 연구에서는 서로 연관된그리고 처음보는 task를 inference하는것을 meta-learn하는 접근을 통해, Bayes-optimal의 행동양상을 근사하는 deep RL 방법인 variBAD를 제안함
- Gridworld 실험에서는 bayes-optimal과 같은 exploration과 exploitation의 trade off성능을 보여주었으며, MuJoCo실험에서는 하나의 에피소드만에 성능을 내는 빠른 adaptation을 보여주어 이를 검증함
- 향후 가능한 연구로는 decoder구조를 사용하여 meta-model based RL이 있으며, distribution shift의 OOD 문제를 풀기위해 알고리즘을 개선해볼수도 있음
- 또한 PEARL에서와 같이 off-policy RL알고리즘에 variBAD를 적용해볼 수 있음
7. 개인적인 생각
- VariBAD는 PEARL과 매우 비슷한 아키텍처를 사용하고 있다. 단 PEARL이 belief를 episode동안엔 유지하고 있는것과는 달리 variBAD는 step마다 업데이트하는 차이가 있다. 이에 대해 저자는 RNN encoder를 사용하고 있어서 가능하다고 언급하는데, RNN의 사용이 시간에 따라 서로 연관된 temporal hidden state 표현이 가능하도록 만들기 때문이라고 한다. 재밌는건 PEARL역시 RNN을 사용하긴 했으나 성능적인 면에선 오히려 떨어진다고 하고, RNN도 correlation을 끊어주었을때 그나마 성능이 비슷해진다고 했다. 즉 PEARL은 RNN에 의한 data correlation이 task inference를 오히려 더 어렵게 만든다고 주장한다. 하지만 variBAD의 결과를 보면 크게 문제되지 않아보인다. encoder를 학습할때 decoder에다 전체 horizon을 다 넣어서 그런가 싶기도 한데, 이부분을 좀 더 자세히 비교하면 좋겠지만 PEARL의 github 구현에서는 아직도 RNN이 TBD 상태이다.
- 또한 PEARL은 decoder가 Q-functon인데 반해 variBAD는 dynamics와 reward를 복원한다. 사실 dynamics를 복원하는건 PEARL에서도 사용했는데 성능이 별로라 그냥 Q를 사용했다고 했다. 하지만 variBAD도 MuJoCo실험에서는 dynamics의 복원보다 reward만 복원하는게 더 성능이 좋았다고 한다.
- PEARL이후에 PEARL의 저자는 variBAD와 같이 Hyper state를 사용하여 이미지 기반 meta-RL에 PEARL을 적용하는 논문인 MELD를 낸다. MELD에서는 이미지를 학습하기위해 Hyper state를 사용하는 SLAC의 아키텍처를 가져오는데, MELD와 SLAC는 실시간 hidden state의 업데이트를 위해 latent dynamics, 즉 temporal dependency를 갖도록 latent variable을 학습한다. 이러한 latent dynamics구조를 사용하면 RNN없이도 실시간 temporal hidden state의 표현이 가능해진다고 한다. 따라서 variBAD에서 처럼 latent dynamics에 RNN을 활용하지 않고 latent dynamics만 잘 학습하도록 하면 충분히 실시간 embedding이 되면서도 가벼운 encoder를 구현할수 있는것 같다. 하지만 이 SLAC아키텍쳐가 구현에 있어서 은근히 번거로운 부분이 있고 action에 대한 response delay가 큰 시스템에서는 잘 동작을 할지 의문이 들긴한다.
- Representation learning과 관련해서는 Chelsea Finn 교수님 연구실에서 나온 논문인 LILI가 생각난다. 최근 RL의 문제는 representation power에 있다는 의견이 많은데, 이 때문에 representation learning을 RL에 붙이려는 시도가 매우 활발하다. LILI는 이러한 representation learning을 multi-agent 문제에 적용하여, interation trajectory로부터 상대방의 의도를 latent variable에 담는 시도를 하는데, real-world RL 측면에서 재밌게 읽어서 저자에게 메일을 보냈다. LILI에서도 VariBAD와 마찬가지로 task의 MDP를 inductive bias로 주어 latent space를 학습하려는 시도를 했다.
- Inference 타입의 Meta-RL인 PEARL이나 variBAD역시 representation으로 meta-learning을 학습하는 구조인데, 사실 두 알고리즘 모두 어떻게 encoder와 decoder를 구성해야 latent task를 잘 학습할지 많은 시도를 한 흔적이 보인다. 하지만 아직은 이론과 실험과정에 사용한 조건이 사뭇 다른 등의 차이로 인해 명확하게 이론의 근거가 와닿지 않는 부분이 많다. 이 representation learning은 특히 지금 내가 연구하고있는 medical field에서도 잘 활용해볼 수 있을 것 같아 적용 중인데, 작게나마 결과를 볼 수 있었다. 앞으로 더 분석을 해보고 real world 실험에서도 잘 되면 medical-representation learning에 대해서 정리를 해볼까 싶다.