
Author : Bernie Wang, Simon Xu, Kurt Keutzer, Yang Gao, Bichen Wu
Paper Link : https://arxiv.org/abs/2103.06386
- Context-based Meta-RL이 training task의 넓은 distribution에 반해 상대적으로 적은 정보로만 학습된다는 단점에서, Context Encoder의 학습에 Contrastive Learning을 추가함.
- Overview Figure

- Algorithm Figure

- Result Figure on MuJoCo

- Off-line Meta-RL인 PEARL보다 사실 성능은 크게 차이나지 않는편. (Average 1.3배, Median 1.14배)
- Meta-World환경에서도 PEARL과 비교를 했는데, 50개 Task 중에서 44개에서 성능이 높지만, 크게 차이나진 않은편. (Average 4.3배, Median 1.4배; 즉 몇몇 특정 task에서 훨씬 잘한 케이스)
- 하지만 이 논문에서 의미있는 부분은 embedding된 task representation 부분
- Meta-world의 Push-v1 환경에서, 서로 다른 위치에 물건을 옮기는 10개의 task에 대한 PEARL과 Contrastive Learning을 추가한 알고리즘 각각의 representation space를 비교.

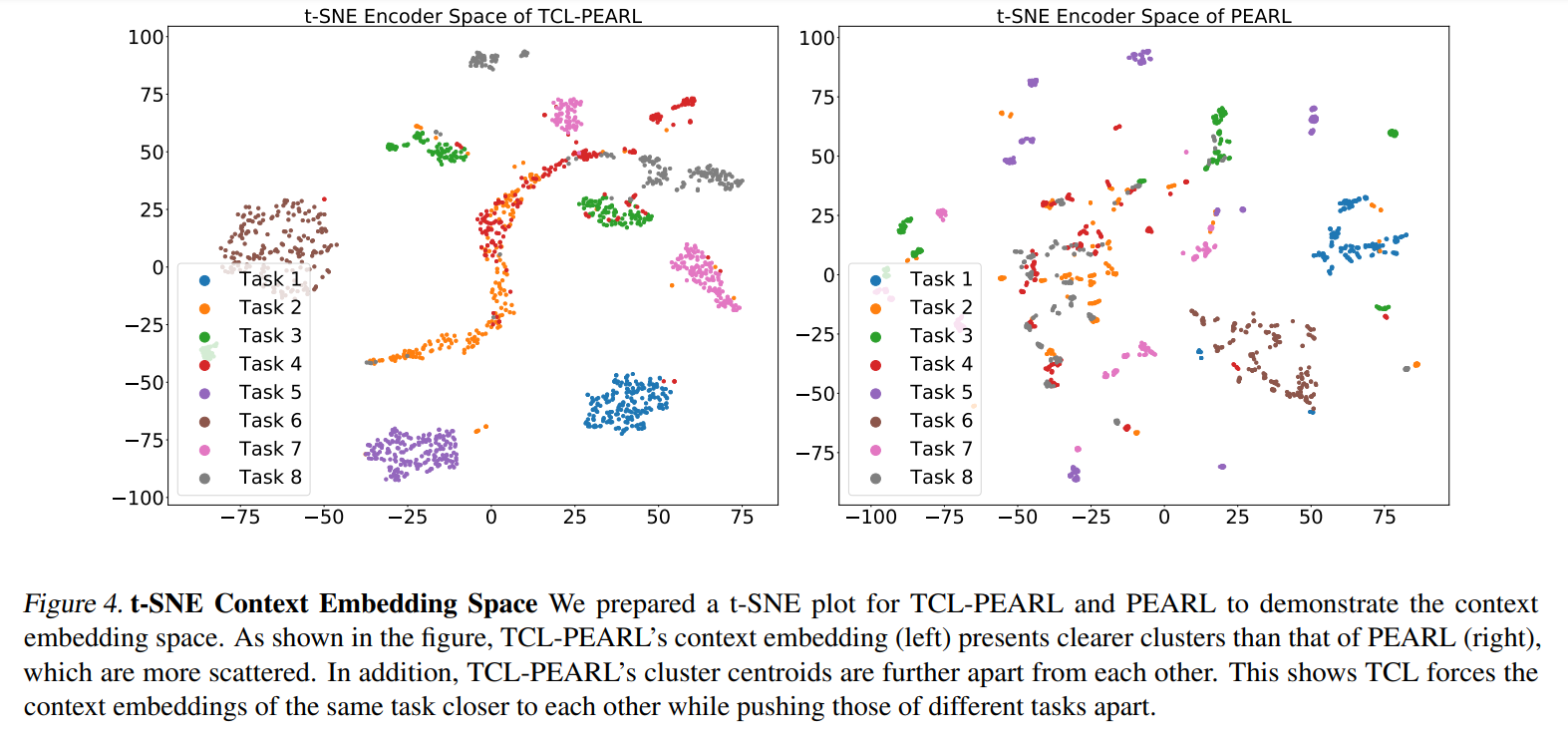
- 각 task마다 200번을 rollout한뒤 샘플된 trajectroy를 t-SNE를 사용하여 2차원 시각화 한 결과 Contrastive Learning을 적용한 알고리즘에서 보다 명확하게 clustring이 된것을 확인할 수 있음.
논문에 대한 나의 의견
개인적으로 context-based Meta-RL은 agent의 행동에 잠재적으로 내포된 goal을 Explainable하게 시각화 할수 있다는 점이 큰 장점이라 생각한다. 이 논문에서 사용한 Contrastive Learning은 이러한 장점을 더 극대화 할수 있는 방법을 제시한것이라 볼 수 있으며, 성능은 크게 좋아지지 않았지만 신뢰도가 중요한 field에 적용할 경우 충분히 의미가 있을것 같다.