
Author : Biwei Huang, Fan Feng, Chaochao Lu, Sara Magliacane, Kun Zhang
Paper Link : https://openreview.net/forum?id=8H5bpVwvt5
Rating: 8, 8, 6, 8
- PEARL, VariBAD와 같은 inference based meta-RL의 structured (graphical) representation 버전
- World-model의 multi-task/meta RL 버전
- 기존의 방법들이 implicit latent task varible을 inference하는 구조였다면, AdaRL은 이를 task간의 domain-shared latent state $s_t$와 domain-specific change factor $\theta_k$ 로 나누어 explicit한 inference를 함
- 이를 가능하도록 학습하기 위해 두 time step동안의 state dimension, action, reward 그리고 이들에 영향을 주는 domain specific parameters $\theta_k$사이의 상호관계 graph를 아래와 같이 가정
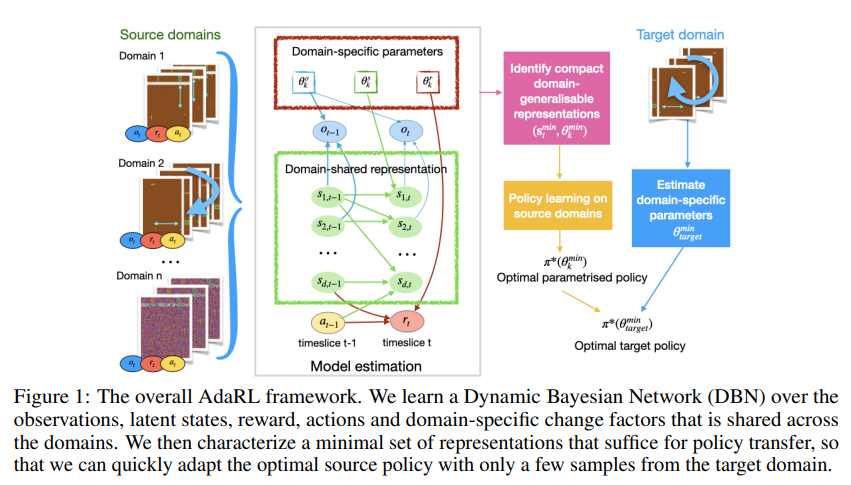
- 이 graphical관계를 수식으로 표현하면 다음과 같음

- 여기서 $c$는 그래프에서 각 요소 사이의 edge에 대한 mask parameter이며 이로 인해 최소한의 필요한 representation만 남음
- 이러한 latent variable를 inference하는 encoder와 각각의 edge들을 end-to-end 학습하기위해 VAE (MiSS-VAE; Multi-model Structured Sequential Variational Auto-Encoder)구조를 제안하여 사용

- 이렇게 구한 explicit한 compact latent variable만 있으면 policy를 학습하기에 충분하다는것을 appendix에서 증명
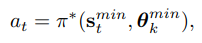
- 알고리즘의 검증은 Cartpole과 Atari Pong에서 진행
- explicit한 task representation덕분에 다양한 task의 variation에서 in/out of distribution 모두에서 기존 알고리즘들보다 비슷하거나 효율적인것을 확인

개인적인 생각
- explicit하게 task representation을 나누어 학습하는것이 좋다. graph를 사용하여 이를 학습가능하게 하는부분이 기발하다. 다만 리뷰어도 언급한 부분으로 이걸 저자가 interpretable이라고 부르기엔 이에대한 검증이 부족해 보인다.
- 지금까지 많은 Meta-RL 논문들이 reward 기반 multiple task에 좀더 집중을 하여 검증을 해왔기에, state dynamics(혹은 transition)이 달라지는 multiple task에 대한 접근은 상대적으로 실험이 부족한감이 없지않아 있었다. 반면 이 연구에선 기존 연구들과 달리 이러한 state dynamics의 변화에 따른 adaptation을 reward보다 더 중점적으로 다룬단 차별점이 있다. 다만 이는 저자의 말에 따르면 reward가 달라지는 task에선 20~50 step의 적은 sample만으론 adaptation이 어려워서가 이유이기도하다.
- 같은 맥락에서 리뷰어도 이야기를 한 부분인데, state dynamics에 잘 adaptation하는 알고리즘이라면 그 장점을 더 잘 보여줄 수 있게 locomotion과 같은 task에서도 검증을 했다면 어떨까 싶다.
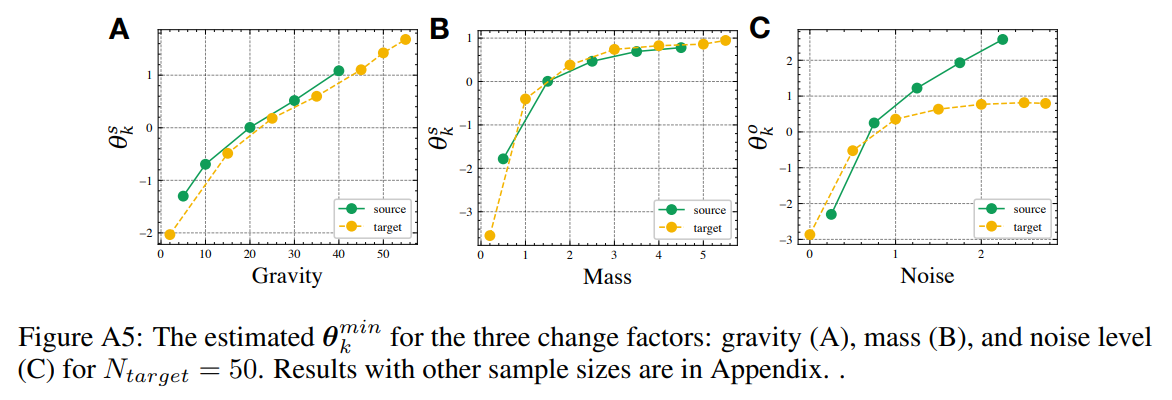
- 실제로 이렇게 structured latent estimation을 할 경우 단순히 baseline대비 성능이 좋다는 내용만 본문에 써둔게 아쉽다. 실제 추론된 $\theta_k$의 검증은 appendix에 있는데, 환경의 물리적 변화와의 연관성이 충분히 보이고 있어서 제안하는 structured self-supervised approach의 유효성을 어느정도 입증하고 있다.
- policy optimization이 필요없는 meta-adaptation을 강조하고 있는데, 이는 VariBAD나 PEARL과 같은 inference based meta-RL들에서 이미 보여준 부분이긴하다. 리뷰어도 언급한 부분인데 이 inference에 대한 설명이 본문에 안보여 Appendix를 읽기 전엔 이해가 다소 어렵다.
- domain index $k$를 input으로 사용하는 부분이 multi-task RL의 색깔이 있기때문에, meta-RL관점에서 이 알고리즘이 generalization이 잘 될지도 궁금하다.
- 알고리즘이 좀 복잡하다. 상당히 많은 notation이 본 paper와 appendix에 섞여 있어서 어렵긴 하나, 이론적 증명이 탄탄한것이 큰 장점이어서 높은 rating을 받은듯하다.
- 저자들이 causal reinforcement learning을 연구한 사람들이라 structural causal model의 개념을 도입한것 같다.