
Author : Anonymous authors
Paper Link : https://openreview.net/forum?id=H7Edu1_IZgR
- 기존 memory based meta-RL의 대표 알고리즘인 RL2에서 RNN을 Transformer로 대체한 버전의 알고리즘
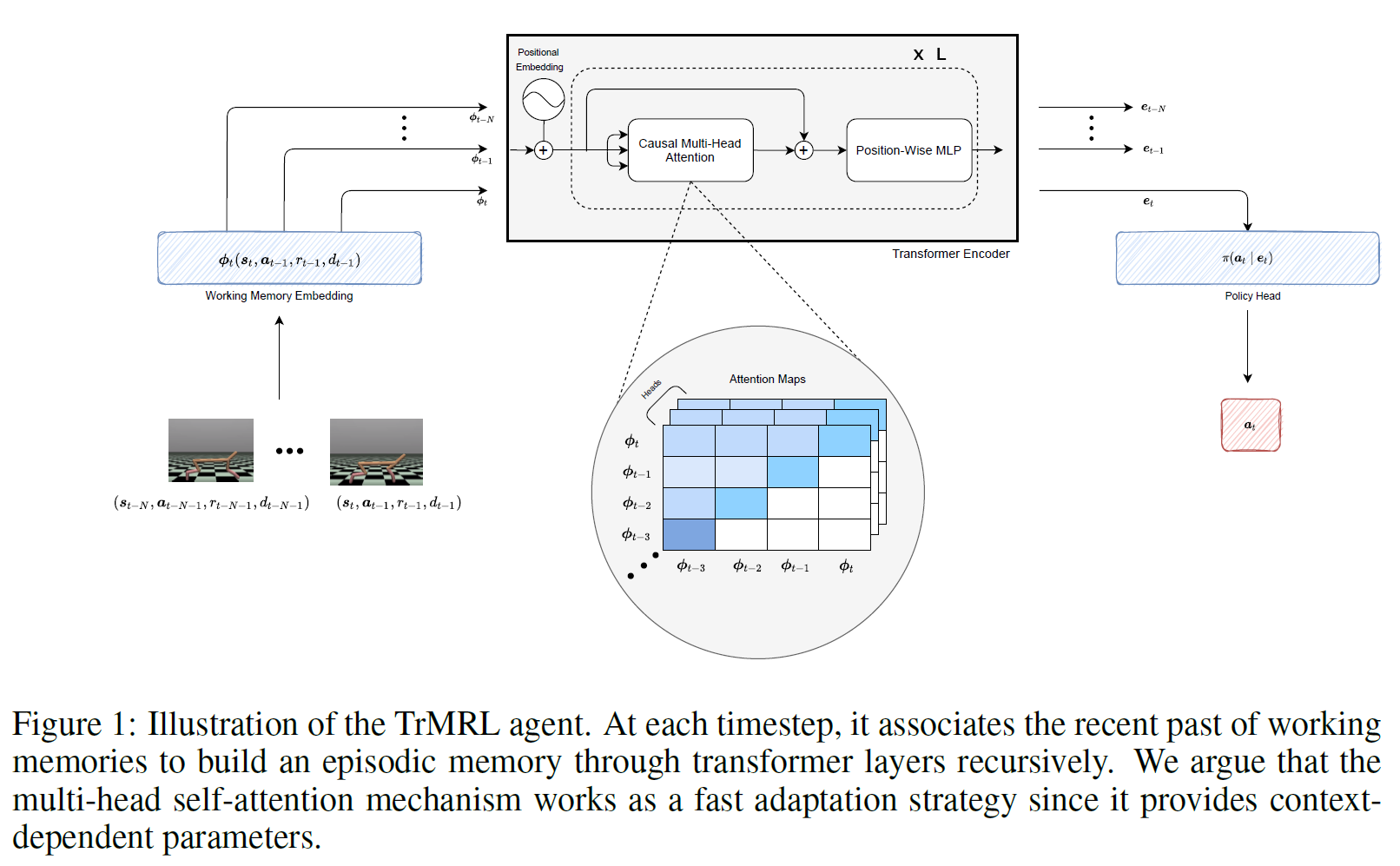
- Transformer의 구조가 왜 meta-learning에 부합하는지 신경과학적으로 해석함
- 한 transition의 embedding은 감각에서 들어오는 신경과학에서의 working memory로 보고, 이 들에 attention mechanism을 적용한 것을 신경과학에서의 reinstatement mechanism와 같다고 하며 Transformer 각 step의 output이 episodic memory에 해당한다고 해석
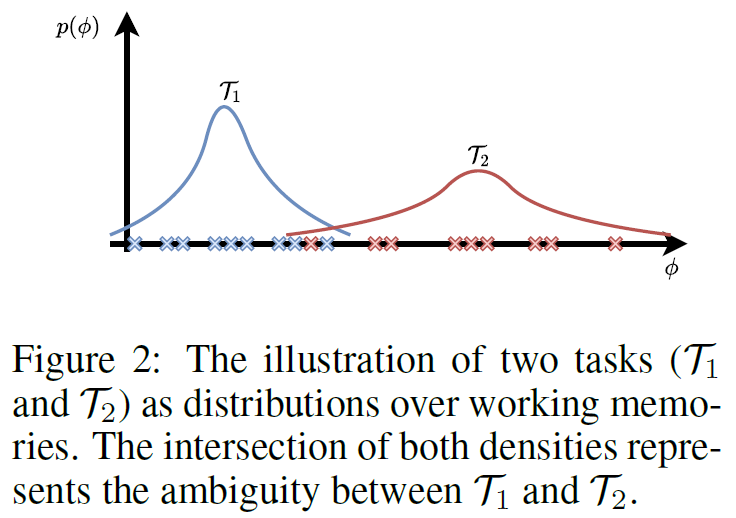
- 즉, 이러한 working memory들이 episodic memory로 합쳐지고 무엇보다 이게 task 분포를 proxy한다고 가설
- RNN보다 Transformer의 sequential representation 능력이 좋기 때문에, MetaWorld에서 RL2의 상위호완 성능을 보여줌

- 새 step이 들어올때마다 Transformer의 input을 queue처럼 사용하기때문에, 사실상 RNN과 같이 쓸 수 있어 RL2, VariBAD와 같은 online adaptation이 가능한 알고리즘
- Episodic adaptation인 MAML이나 PEARL에 비하면 매우 빠른것이 장점

- OOD에서는 PEARL이나 MAML보다 TrMRL 및 RL2가 높은 성능을 보여주어 보다 효과적인 representation을 생성함

- Working memory가 각 Task에 대해 잘 분리 된다는것을 latent visualization으로 보여줌

개인적인 생각
- RL2에서 RNN을 Transformer로 바꾼것이 사실 이 연구의 알고리즘적인 contribution이다. 하지만 RNN을 Transformer로 대체하는건 사실 다른 분야에선 더 이상 contribution이 되지 못한다. (21.11.09 코멘트: 오늘 공개된 openreview 점수가 역시나 5533이다) 그래서 그런지 Transformer의 평범한 구조들에 대한 meta-learning측면의 신경과학적인 해석에 공을 상당히 들였다.
- Reward signal만으로 capacity가 큰 Transformer까지 end-to-end로 학습하는구조라 학습이 매우 어렵다. 특히 episodic memory중에서 1개로만 policy loss가 back prop 들어가는 구조라 충분히 학습이 되려나 싶었는데 나름 성능이 좋다고해서 신기하다. 하지만 역시나 학습이 불안정하다는걸 강조하며 Ad hoc으로 network initializaton이 쓰인다.
- 알고리즘과 환경의 특성상 "Metaworld가 아닌 Mujoco에선 PEARL이 더 performance가 좋을것 같은데 figure가 안보이네"라고 생각하며 읽었는데, 역시나 Appendix로 빼둔것이었고 PEARL이 압도적으로 잘된다. 논문을 쓰는 전략적인 측면에선 나름 알고리즘을 돋보일 수 있는 실험들 위주로 잘 배치한 것 같긴하지만 리뷰어들의 의견이 궁금하다. (21.11.09 코멘트: 오늘 공개된 openreview 점수가 역시나 5533이다)

- 이 논문에선 episodic memory가 task를 proxy한다고 가설을 세웠다. 하지만 정작 task를 구분하는 loss가 없어서 어찌될지 궁금한데, episodic memory의 latent space를 visualized한 결과를 안보여줬다. Reward기반의 task들이라 linear한 구분이 당연히 잘 될 수 밖에 없는 working memory의 latent space만 visualization해서 task구분이 되는듯하다고 써둔것이 아쉽다.
- OOD에 대한 해석에서 memory based 알고리즘이 optimization based나 context based 알고리즘보다 더 representation이 효과적이라고 했으나, 개인적으론 memory based 알고리즘 역시 (혹은, 특히나) generalization에 대한 loss가 딱히 없기 때문에 잘못된 해석인것 같다. 실제로 MAML, PEARL보다 높다 뿐이지 해당 halfcheetah에서의 score를 보면 제대로 동작한다고 보긴 어려워, RL2 및 TrMRL에 의해 형성되는 task latent space의 명확함이 오히려 떨어져서 생기는 현상이라고 생각된다.