
Author: Julián N. Acosta, Guido J. Falcone, Pranav Rajpurkar & Eric J. Topol
Paper Link: https://www.nature.com/articles/s41591-022-01981-2
최신 foundation model들 까지 고려한 Eric Topol교수님의 의료 데이터에서의 multimoality에 대한 리뷰 페이퍼.

Author: Julián N. Acosta, Guido J. Falcone, Pranav Rajpurkar & Eric J. Topol
Paper Link: https://www.nature.com/articles/s41591-022-01981-2
최신 foundation model들 까지 고려한 Eric Topol교수님의 의료 데이터에서의 multimoality에 대한 리뷰 페이퍼.

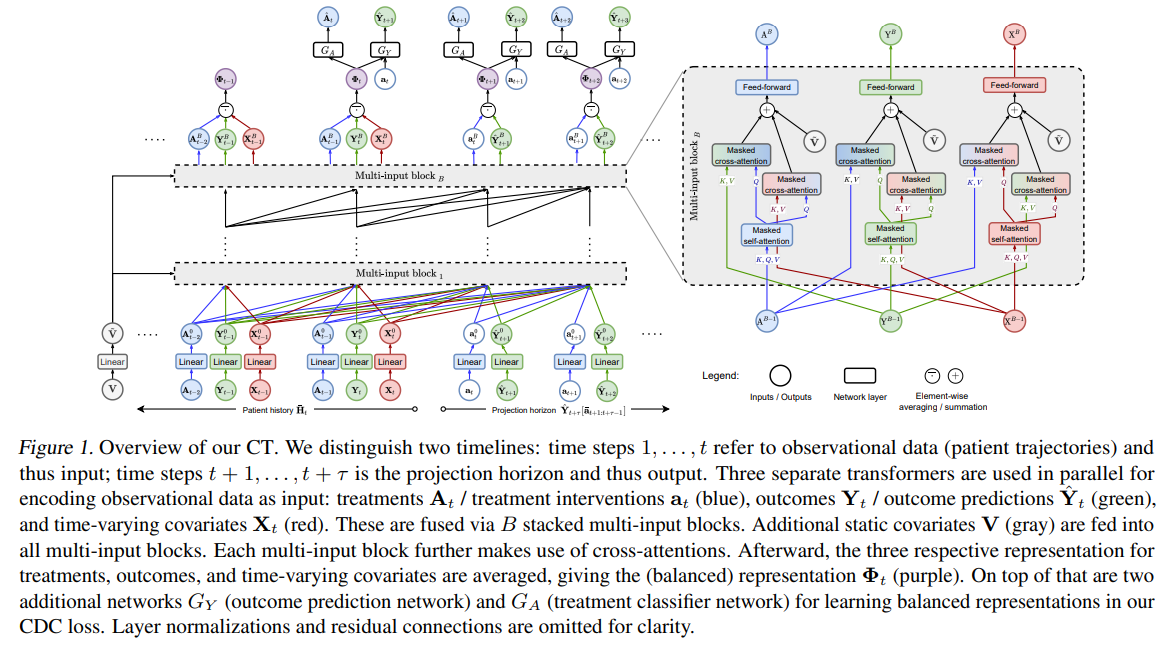
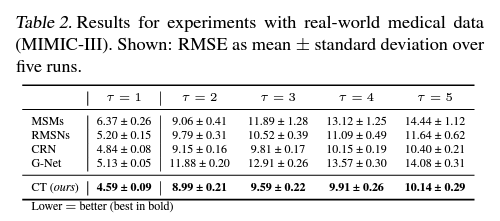
Author: Valentyn Melnychuk, Dennis Frauen, Stefan Feuerriegel
Paper Link: https://arxiv.org/abs/2204.07258
Code: https://github.com/Valentyn1997/CausalTransformer
ICML slide: https://icml.cc/media/icml-2022/Slides/17693.pdf
ICML presentation: https://slideslive.ch/38983812/causal-transformer-for-estimating-counterfactual-outcomes?ref=recommended
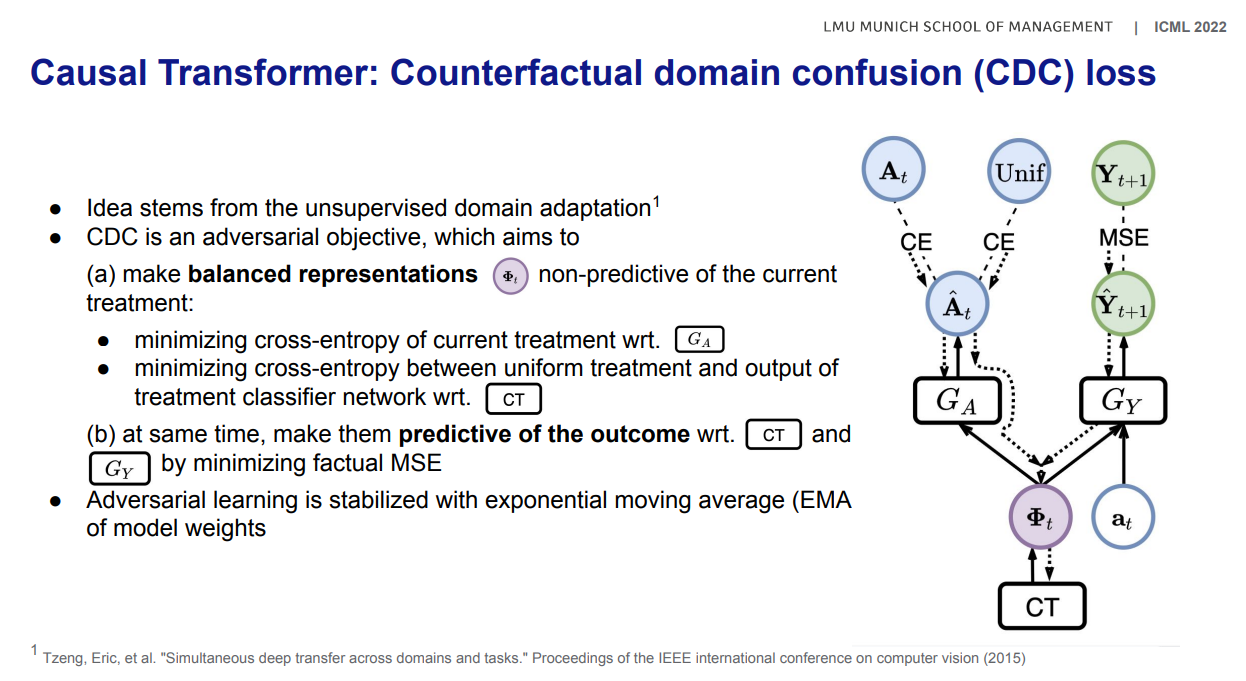
[Domain confusion loss]
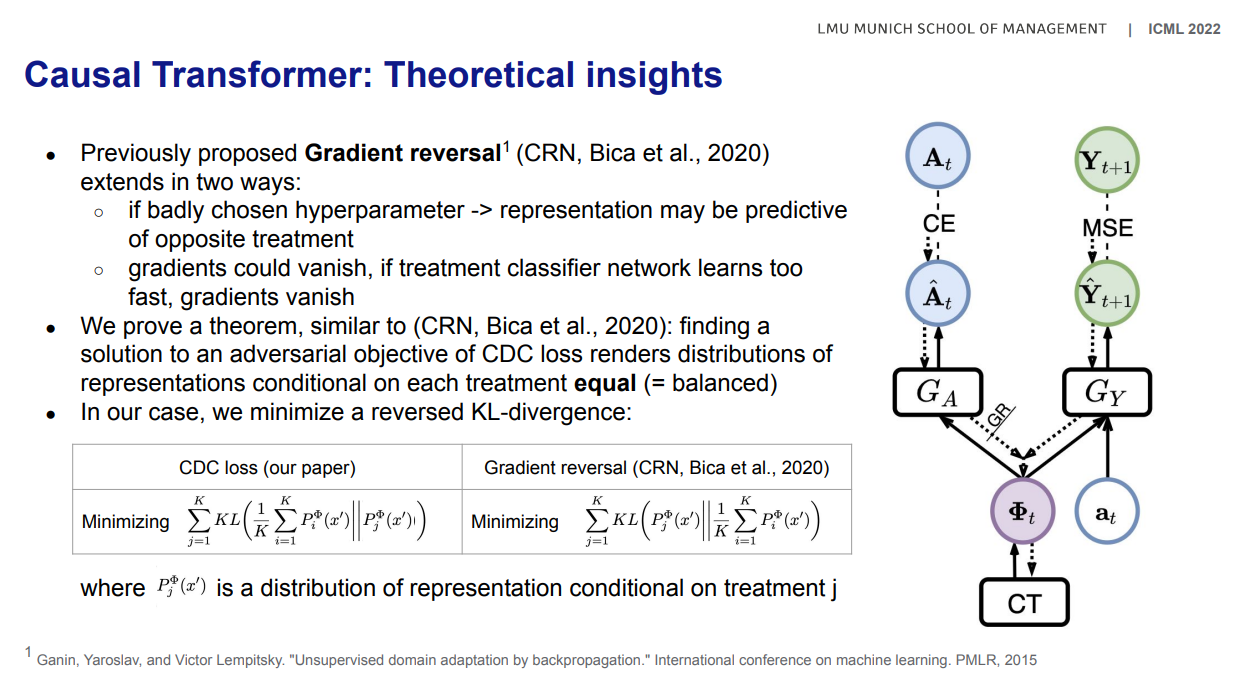
[Gradient reversal]


네이버의 초거대 인공지능 하이퍼클로바를 이용하여 의료분야에 적용해보는경진대회에서 최우수상을 수상하였습니다.

| DMJ 논문 Best paper of the year 선정 (0) | 2021.07.02 |
|---|
스탠포드 첼시핀 교수님의 CS330강의가 공개되면서 부터, 동료들과 함께 집필을 시작한 메타러닝 첫 한국어 도서집필 프로젝트입니다. 최종 편집본이 오늘 나왔는데 총 282쪽이네요.
출판은 위키북스를 통해 진행했으며, 책의 검수에는 고려대학교 인공지능학과의 최성준 교수님께서 연구/교육/업무로 정말 바쁘신 와중에 시간을 내어주셨습니다. 나중에 최종 출판이 되면 다시한번 감사드리겠지만, 최종 편집을 하려 PDF를 열때마다 부족한 저희에게 시간을 할애해 주신 최성준 교수님께 매번 감사하는 마음이 들었습니다.
표지의 동물은 오리너구리로 포유류이면서도 조류와 같이 알을 낳는 등 여러 동물들의 특성을 모두 가지고 있는데, 실제 유전적으로도 포유류, 조류, 파충류가 혼합되어 있다고 합니다. 환경에 맞춰 다양하게 퍼져나가는 진화가지를 내포한듯한 이러한 특징이 마치 메타러닝과 비슷하다고 생각하여 이번 메타러닝 책의 표지로서 오리너구리를 택하게 되었습니다.

마지막으로 귀여운 실제 오리너구리 사진 보시겠습니다.

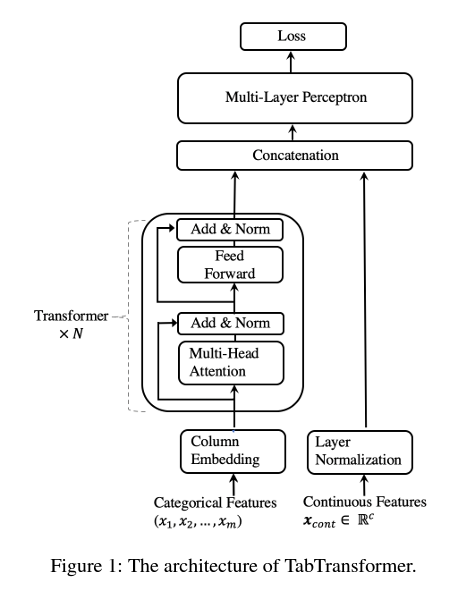
TabTransformer: Tabular Data Modeling Using Contextual Embeddings (Xin Huang, arXiv 2022)
Paper Link: https://arxiv.org/abs/2012.06678
Talk: https://www.youtube.com/watch?v=-ZdHhyQsvRc
AWS Code: https://github.com/awslabs/autogluon/tree/master/tabular/src/autogluon/tabular/models/tab_transformer
Other Repo 1: https://github.com/lucidrains/tab-transformer-pytorch
Other Repo 2: https://github.com/timeseriesAI/tsai/blob/main/tsai/models/TabTransformer.py
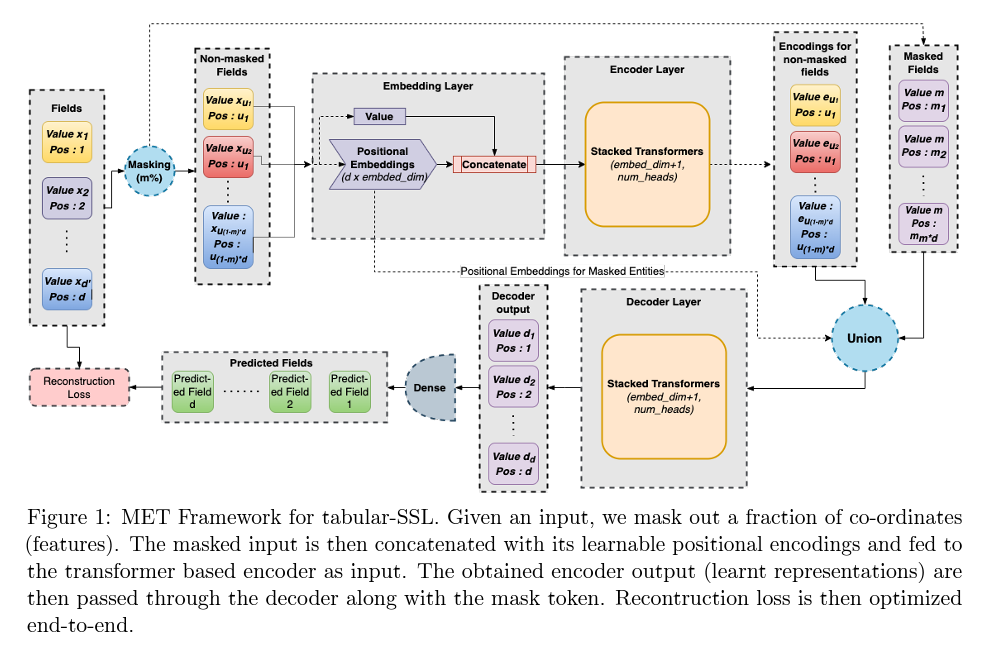
MET: Masked Encoding for Tabular Data (Kushal Majmundar, Arxiv 2022)
Paper Link: https://arxiv.org/abs/2206.08564
Tabular Transformers for Modeling Multivariate Time Series (Inkit Padhi, ICASSP 2021)
Paper Link: https://arxiv.org/abs/2011.01843
Code: https://github.com/IBM/TabFormer

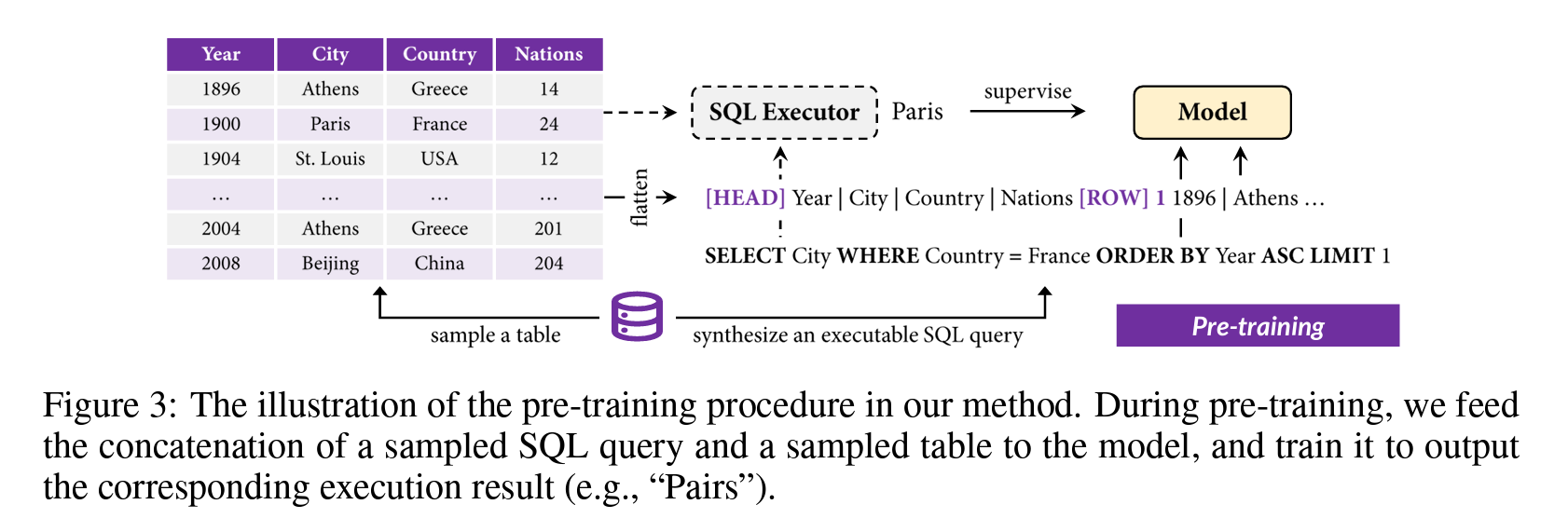
TAPEX: Table Pre-training via Learning a Neural SQL Executor (Qian Liu, ICLR 2022)
Paper Link: https://arxiv.org/abs/2107.07653
Code: https://github.com/microsoft/Table-Pretraining
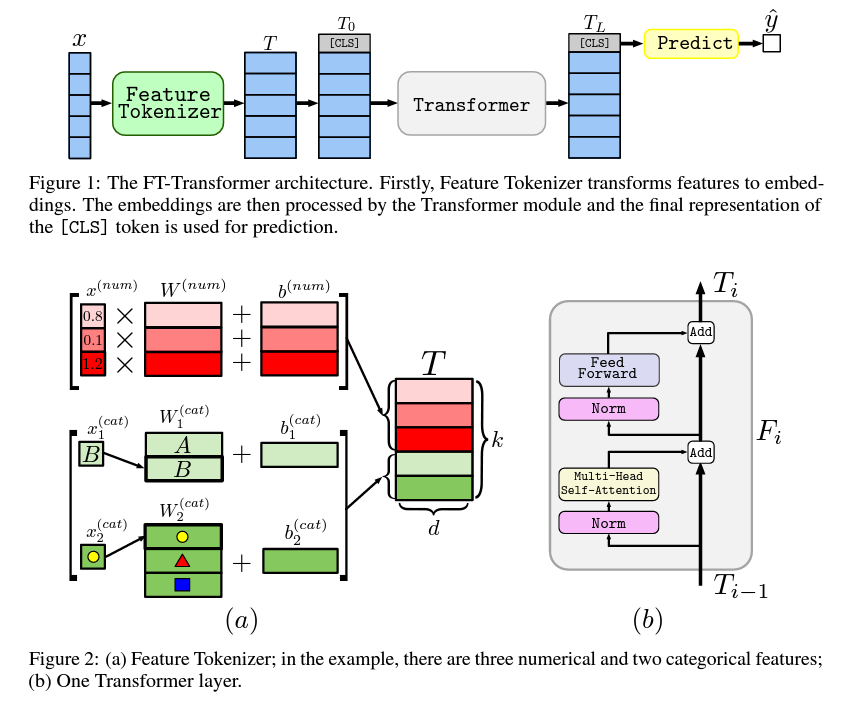
Revisiting Deep Learning Models for Tabular Data (Yura Gorishniy, NeurIPS 2021)
Paper Link: https://arxiv.org/abs/2106.11959v2
Code: https://github.com/Yura52/tabular-dl-revisiting-models
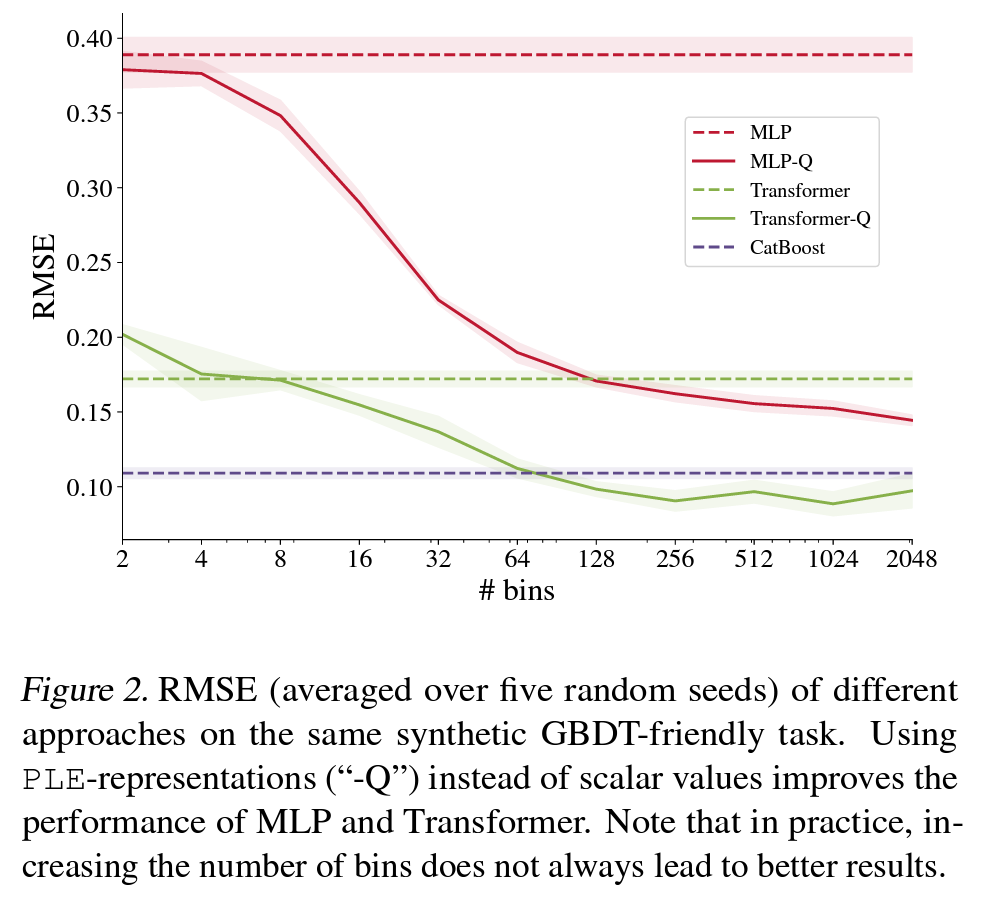
On Embeddings for Numerical Features in Tabular Deep Learning (Yura Gorishniy, arXiv 2022)
Paper Link: https://arxiv.org/abs/2203.05556v1
Code: https://github.com/Yura52/tabular-dl-num-embeddings
Revisiting Pretraining Objectives for Tabular Deep Learning (Ivan Rubachev, arXiv 2022)
Paper Link: https://arxiv.org/abs/2207.03208
Code: https://github.com/puhsu/tabular-dl-pretrain-objectives
그 외 깃헙 레포 리스트