Author : Lavender Yao Jiang, Xujin Chris Liu, Nima Pour Nejatian, Mustafa Nasir Moin, Duo Wang, Anas Abidin, Kevin Eaton, Howard Antony Riina, Ilya Laufer, Paawan Punjabi, Madeline Miceli, Nora C. Kim, Cordelia Orillac, Zane Schnurman, Christopher Livia, Hannah Weiss, David Kurland, Sean Neifert, Yosef Dastagirzada, Douglas Kondziolka, Alexander T. M. Cheung, Grace Yang, Ming Cao, Mona Flores, Anthony B. Costa, Yindalon Aphinyanaphongs, Kyunghyun Cho & Eric Karl Oermann Paper Link : https://www.nature.com/articles/s41586-023-06160-y Code: https://github.com/nyuolab/NYUTron, https://github.com/nyuolab/i2b2_2012_preprocessing
스탠포드 대학교 HAI(Human-Centered Artificial Intelligence) 연구소의 의료분야에서 Clinical Foundation Models에 대한 분석 논문을 발표하였습니다.
"The Shaky Foundations of Clinical Foundation Models: A Survey of Large Language Models and Foundation Models for EMRs"; Michael Wornow et al. (https://arxiv.org/abs/2303.12961)
논문에서는 Foundation model이 갖는 여섯 가지 이점을 정리하였는데, 이 중 '6. Novel human-AI interface'의 대표 사례로서최근 저희가 고려대 안산병원 내분비내과 이다영•김난희 교수님과 함께 수행한'Clinical Decision Transformer (CDT)'연구를 언급했네요. 특히, FEMR (Foundation model for Electronic Medical Records) 에서는 유일한 사례입니다.
Dexcom 센서는 학위기간 동안 많이 써봤는데 Abbott 센서는 처음 써보네요. 2주동안 Abbott freestyle libre 센서를 달고, 건강관리 목적 + 다이어트 목적으로 혈당관리를 해보려고 합니다.
같은 음식을 먹어도 사람마다 혈당반응이 다르며, 동일한 음식 동일한 사람에서도 상황에 따라 혈당반응이 다르게 나타납니다. 스트레스에도 반응은 크게 달라지며, 수면량, 컨디션, 식사시간, 음식조합, 섭취순서에 따라서도 달라집니다. 때문에, 내 몸에 맞는 혈당관리는 상당한 human feedback을 필요로합니다. 당대사가 원활한 건강한 사람에게도 혈당관리는 쉽지않은 일이며, 당뇨병환자분이나 당뇨전단계인 분들껜 이 과정이 몇배는 더 어렵습니다.
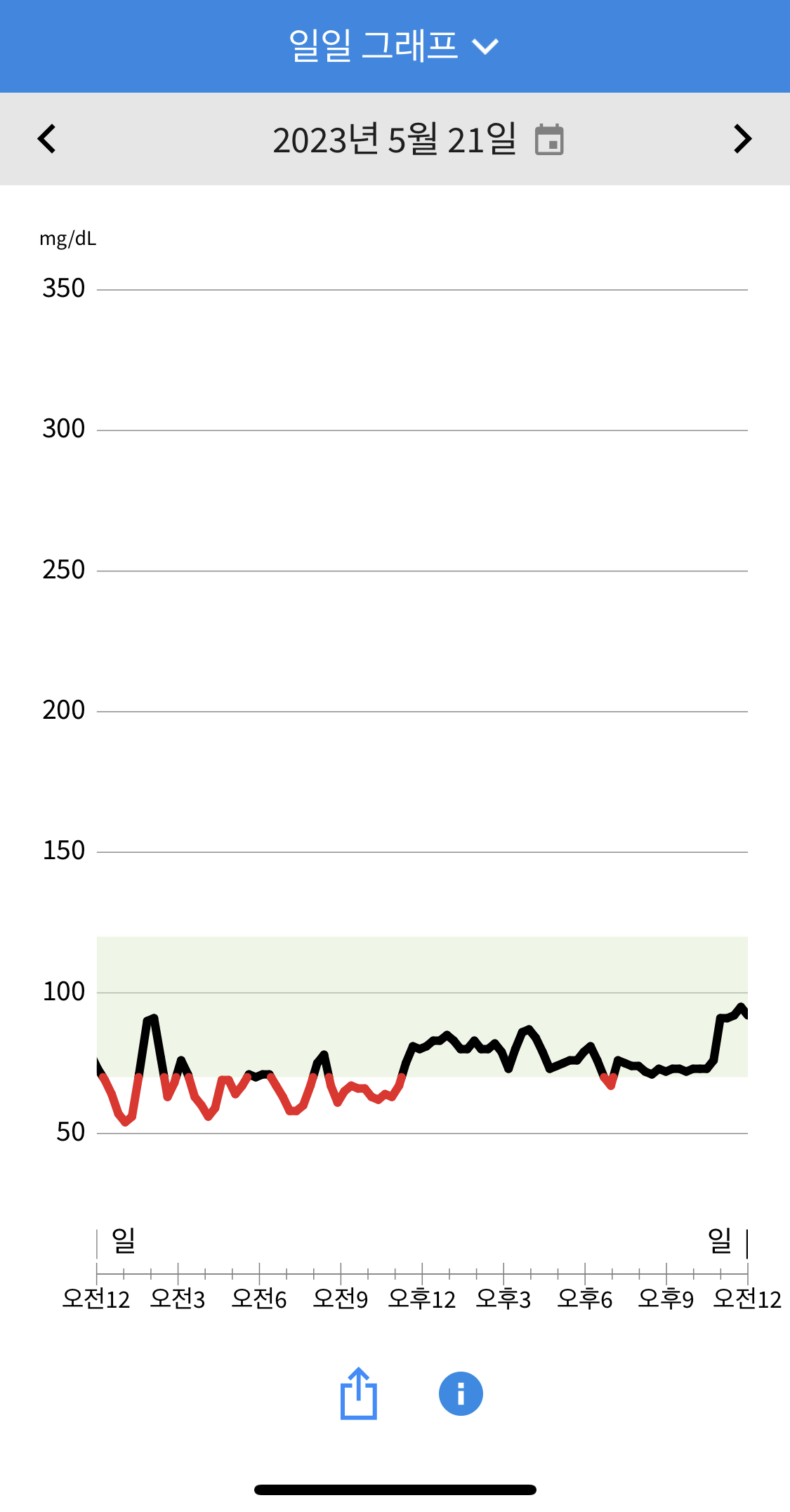
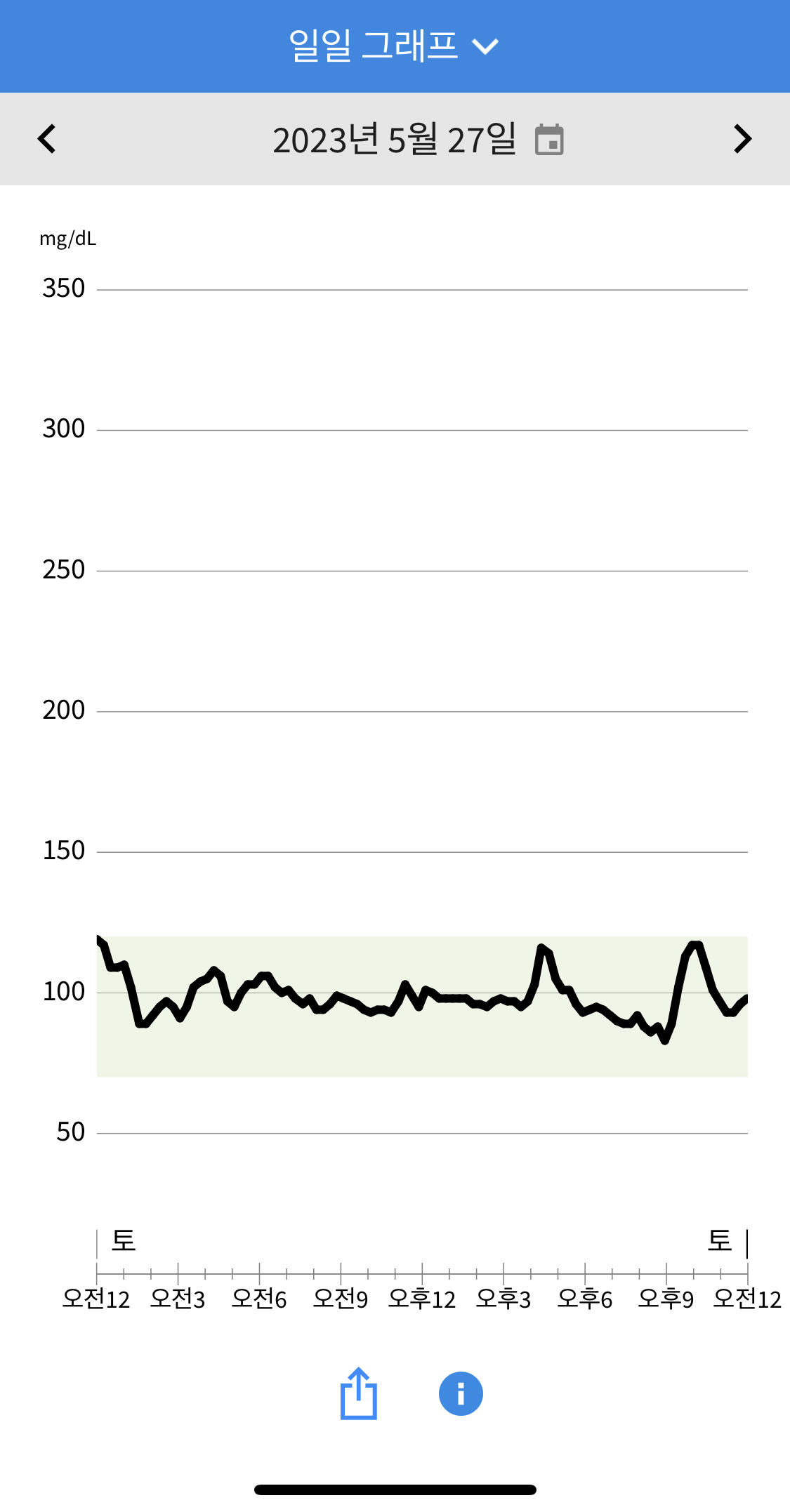
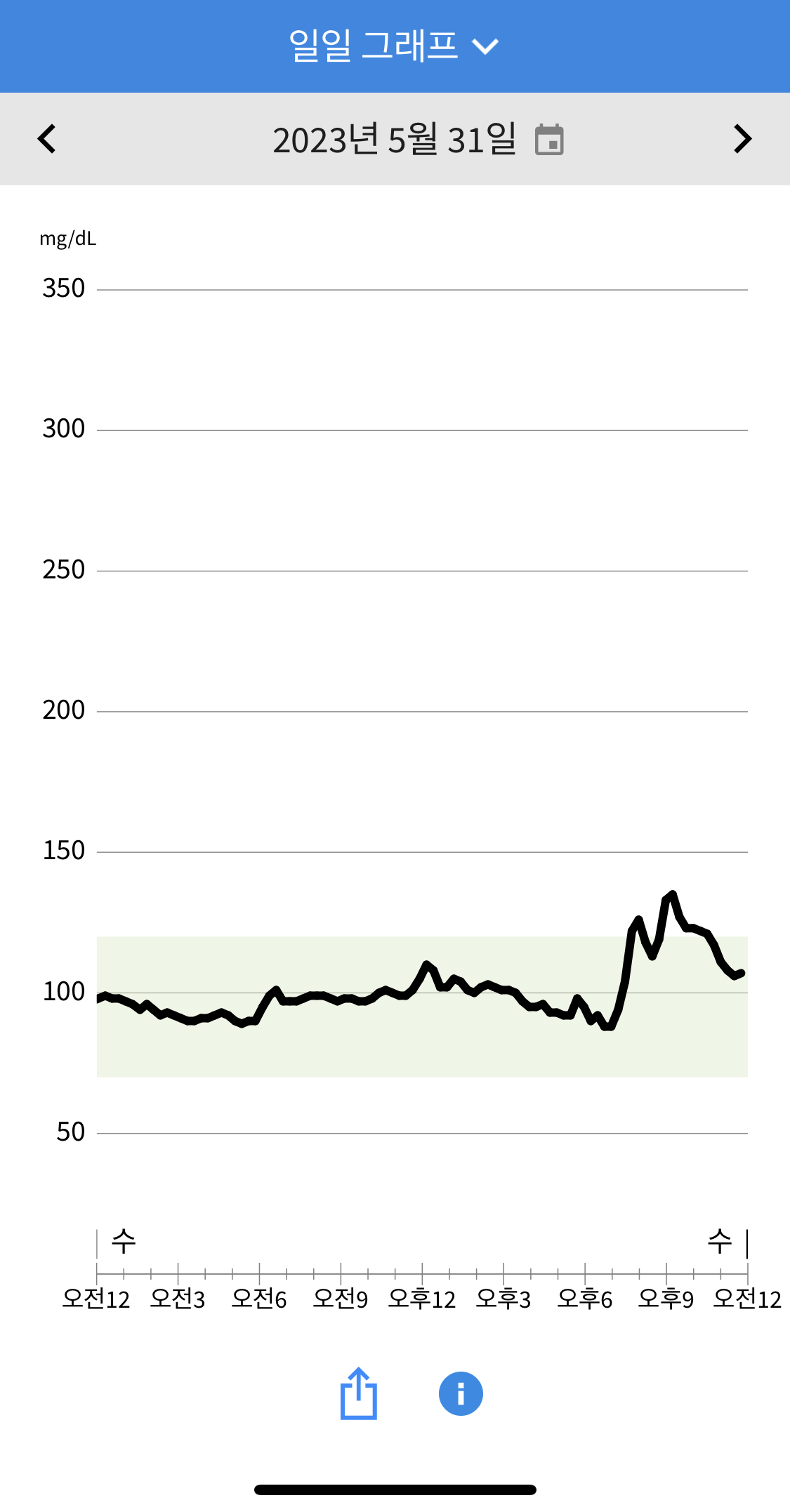
1일차 센서 착용 1~2일동안은 부정확하며, libre의 경우 대체로 혈당값이 낮게 측정되었습니다. 점심으로 (마랴상궈/계란볶음밥/즈마장/제로콜라) 를 먹었으나, 유의하게 측정되진 않은것 같습니다. 저녁에는 (서브웨이 참치샐러드, 제로콜라) 를 먹었는데 마찬가지로 측정이 잘 안된듯합니다. 혈당 측정을 핑계로 남은 (마라샹궈/계란볶음밥/즈마장/제로콜라) 를 야식으로 먹었는데 혈당 반응이 측정되기 시작하였습니다.
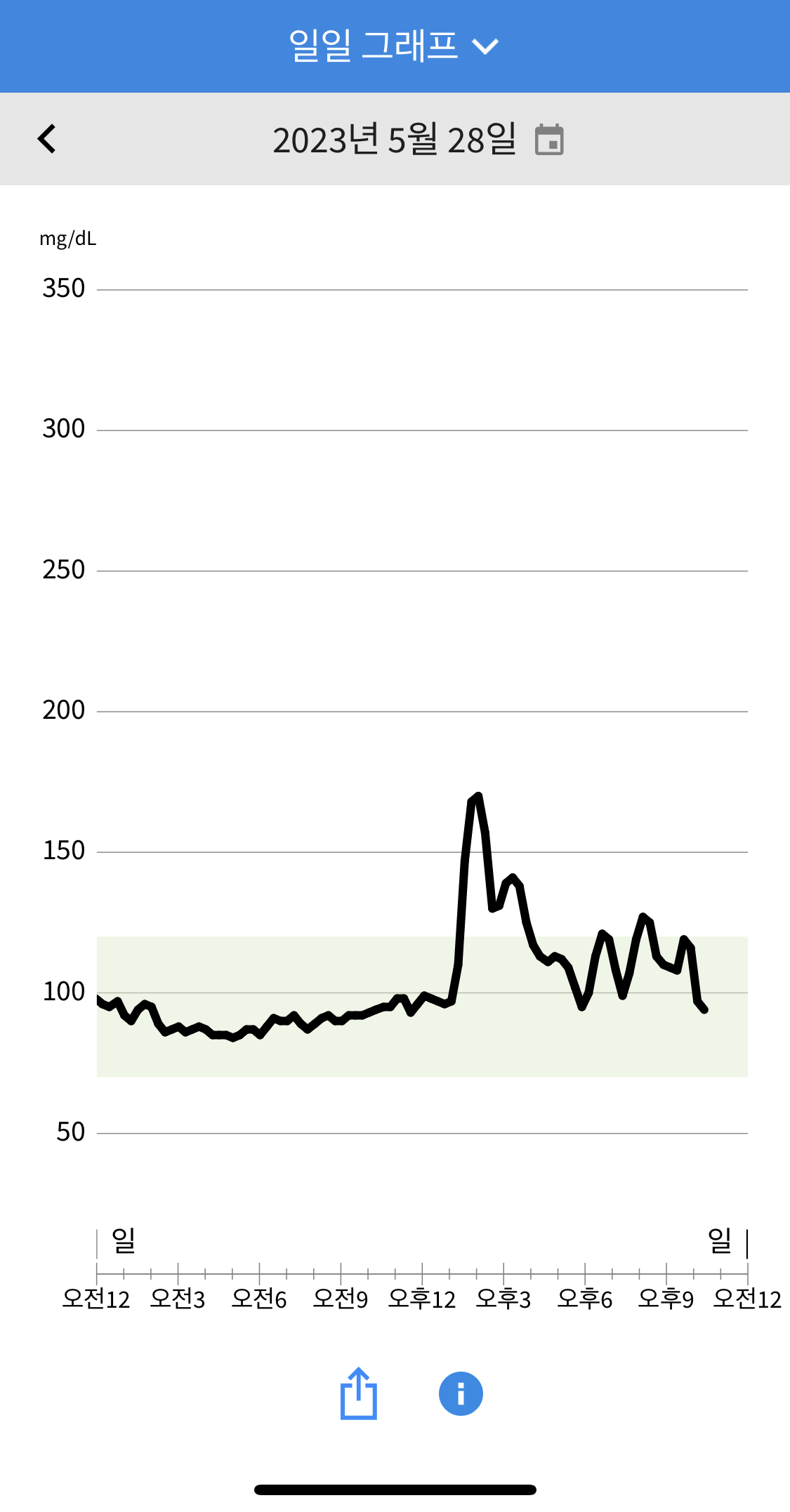
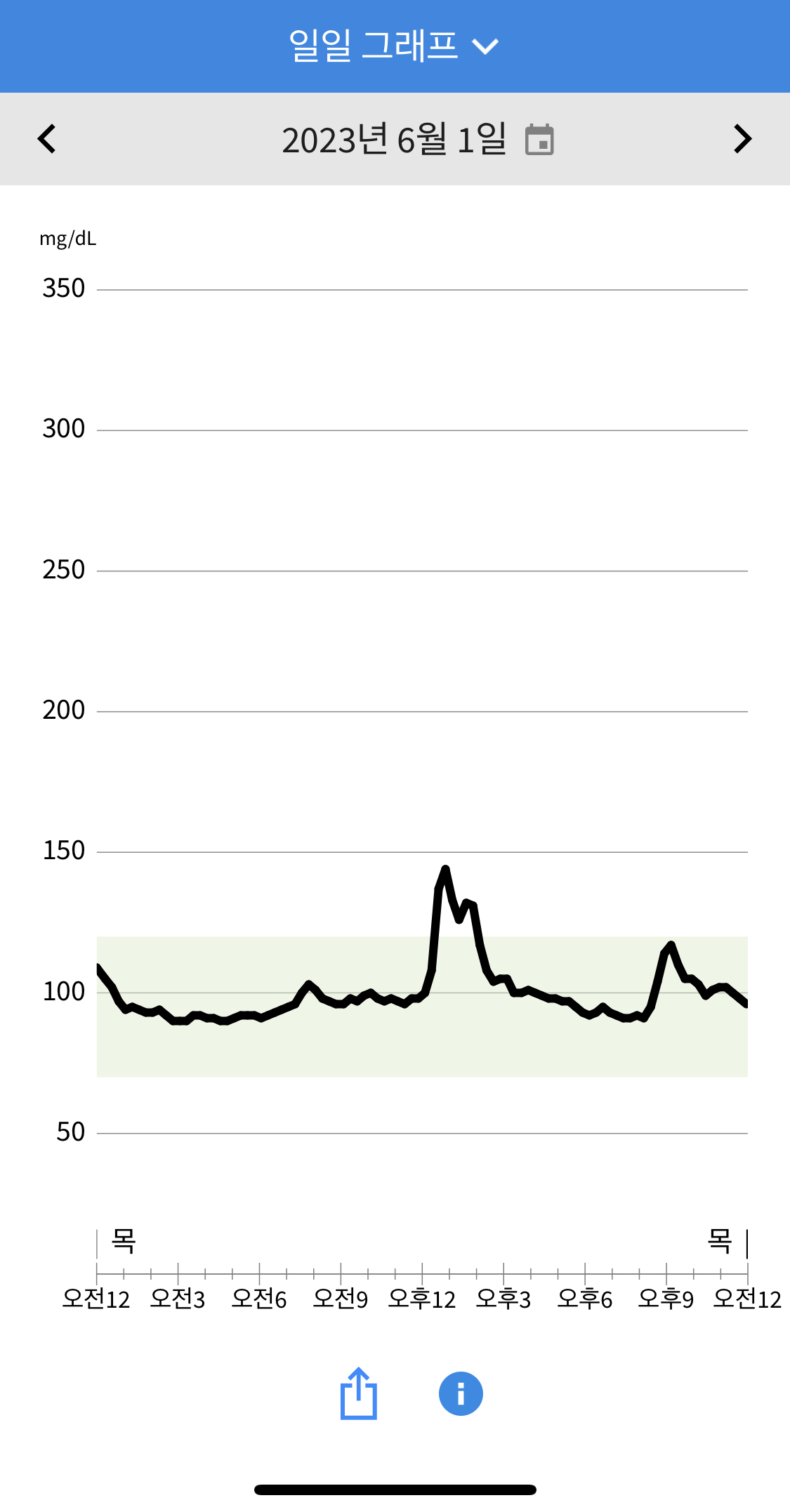
2일차 오전부터 어느정도 제대로 측정되기 시작했습니다. 출근을 해 (아메리카노)를 늘 마시는데, 혈당에 영향은 전혀 없습니다. 여러번 확인했기때문에 이후 부턴 아메리카노는 기록하지 않으려고 합니다. 점심으론 (닭가슴살 콥샐러드/오리엔탈 드레싱/제로콜라) 를 먹었고, 간식으로 (하루견과), 저녁으로는 (닭가슴살 바질샐러드/오리엔탈 드레싱/주말에먹고남은 핫윙)을 먹었습니다. 초록 음식을 먼저먹으면 혈당스파이크를 낮출 수 있기에 핫윙을 먹기에 앞서 샐러드를 먼저 먹었습니다.
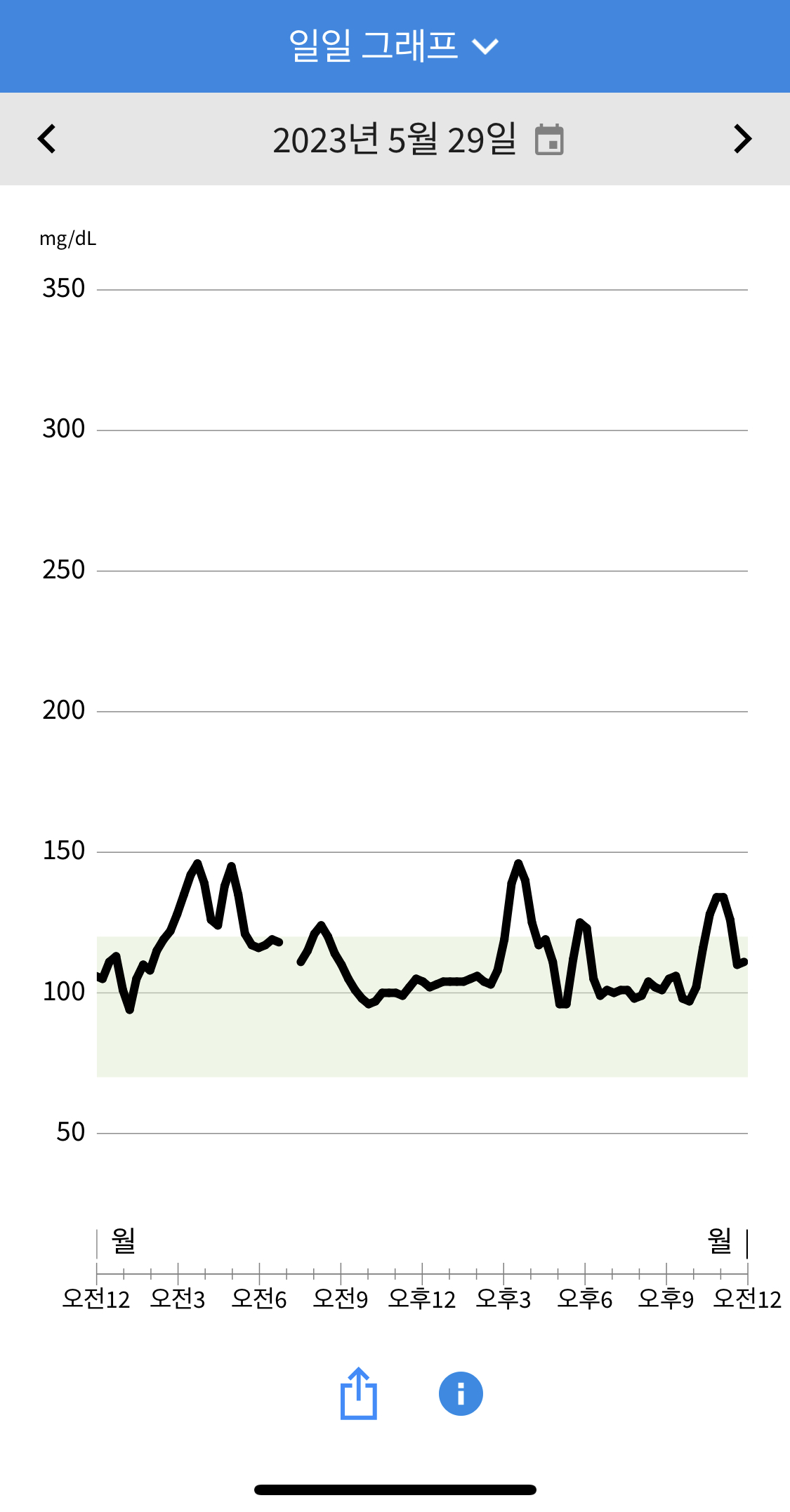
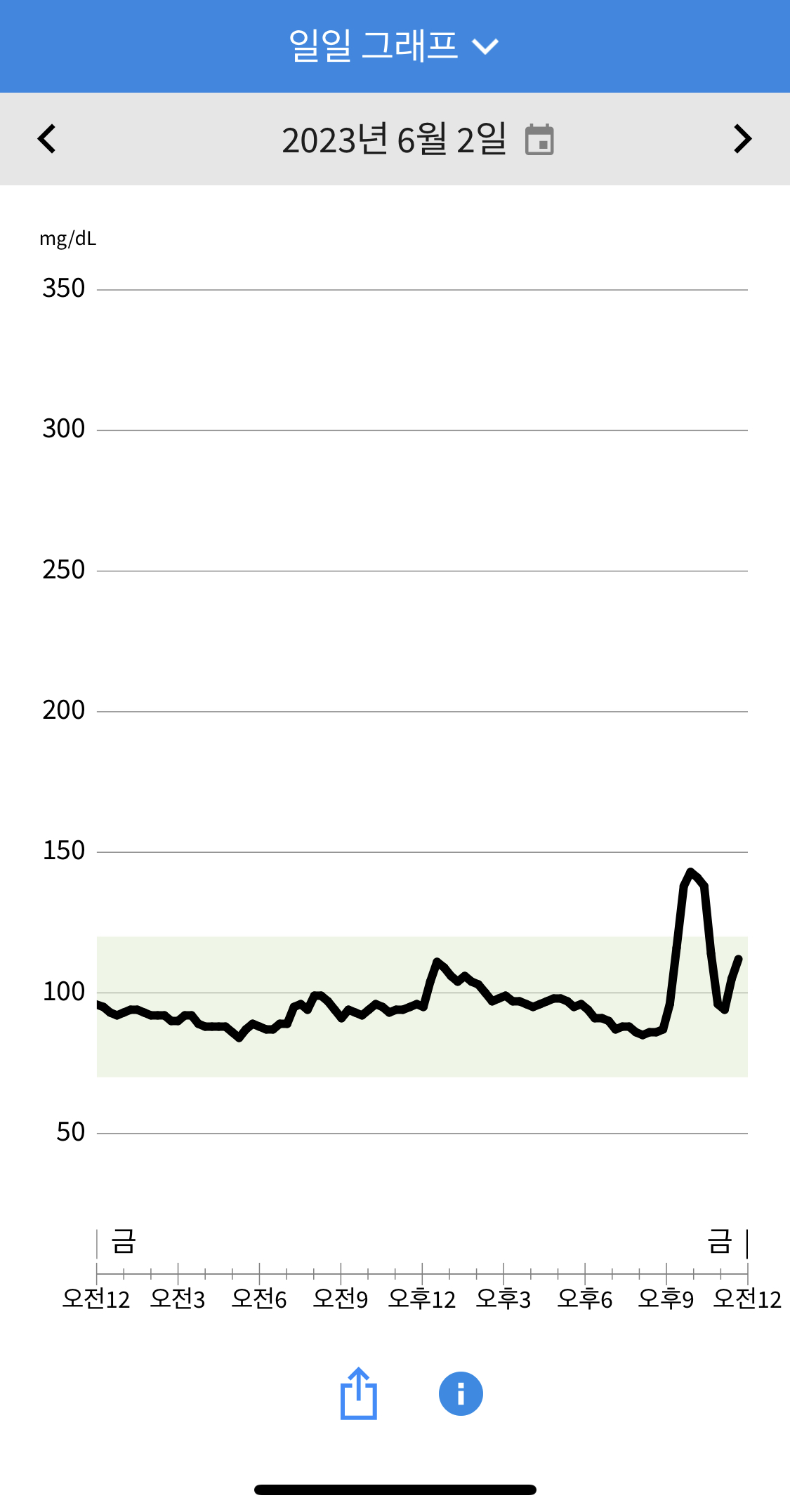
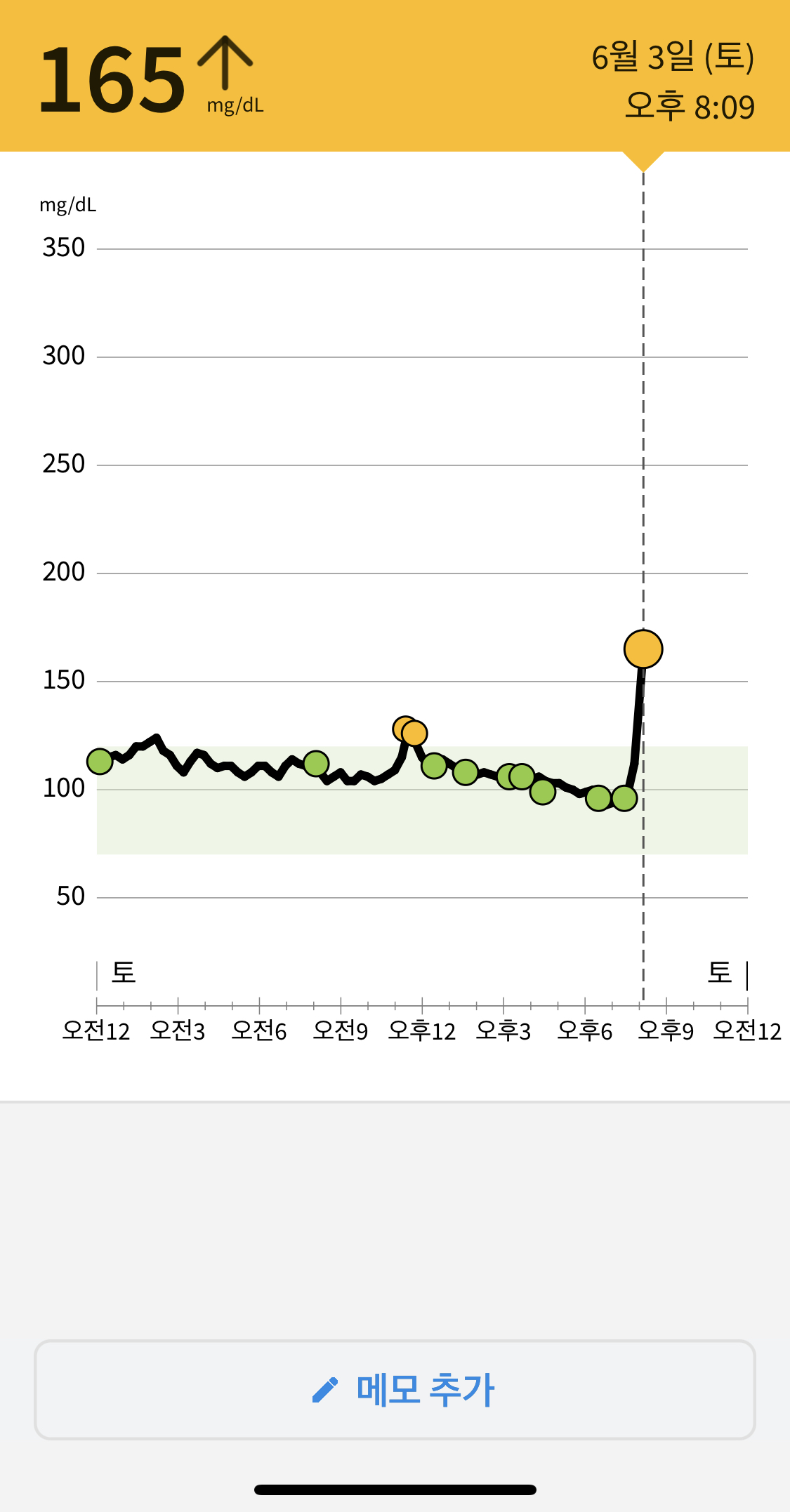
3일차 수면부족(4시간 미만)으로 아침에 피로가 심했고 몸이 찌뿌둥했습니다. 샤워를 하면서부터 아무것도 먹지 않았는데, 혈당이 오르기 시작했습니다. 점심으로 (불고기 샐러드/발사믹 드레싱/제로사이다)를 먹었는데 샐러드치곤 혈당이 많이 솟았습니다. 피로가 조금씩 풀려서인지 기저 혈당이 서서히 낮아졌습니다. 저녁엔 동료들과 회식이 있어는데 (크림 떡볶이)를 포함한 술안주를 먹어 나름 양조절을 했음에도 혈당이 치솟았습니다. 많이 마시진 않았지만 (생맥주) 때문인지 저녁엔 혈당이 기저보다 더 낮게 떨어졌습니다.
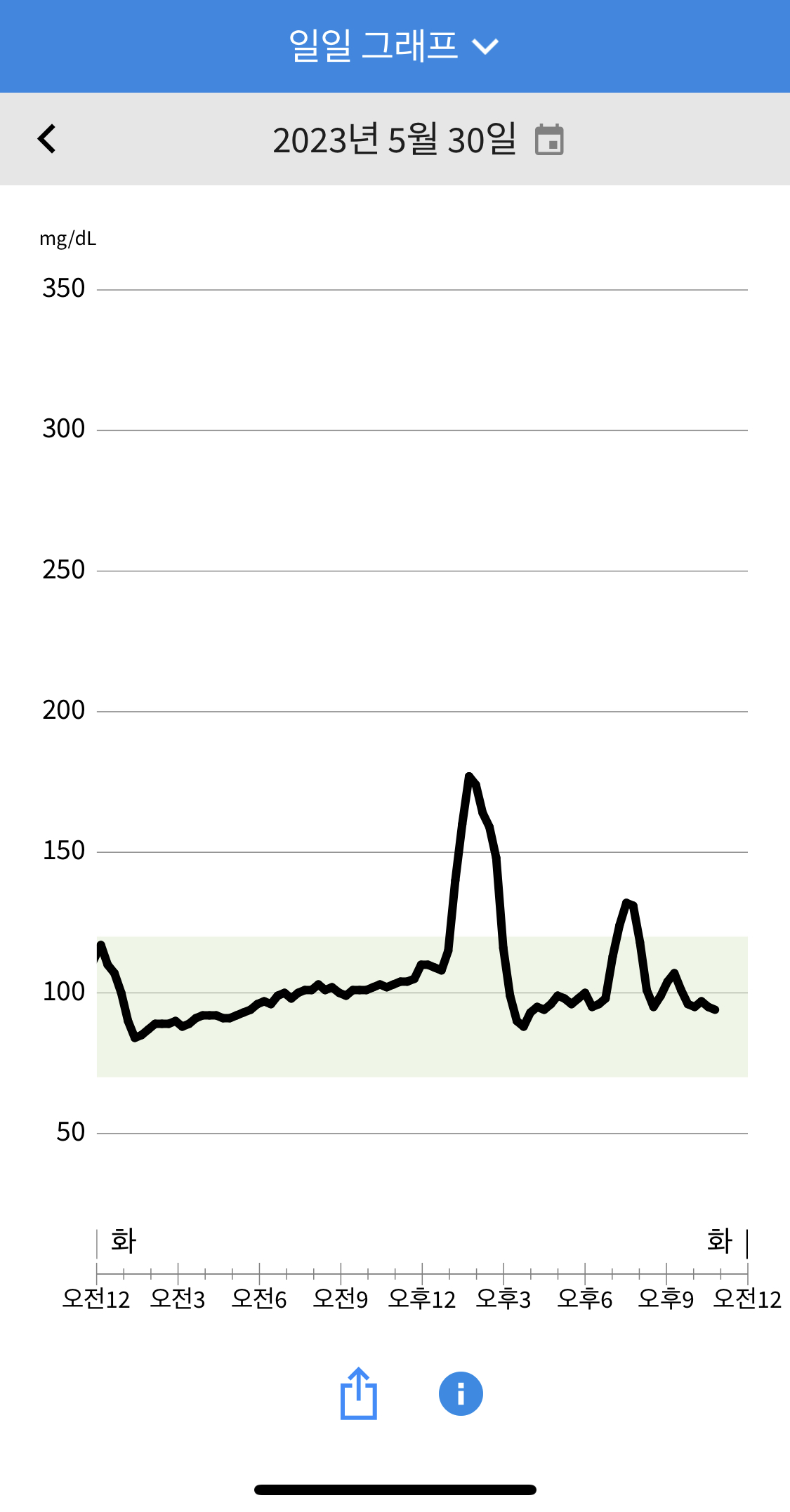
4일차 (사세버팔로윙)이라고 유명한 간식이 있는데, 나름 튀김옷이 없어 혈당 반응이 낮을거라 생각하고 밤에 에어프라이어에 구워먹었습니다. 하지만 급격히 치솟았는데 돌이켜보면 생각보다 단맛이 컷던것 같기도 합니다. 야식을 먹고자서인지 밤사이 기저가 높아졌습니다. 점심으론 (베이컨 샐러드/발사믹 드레싱/제로콜라)를 먹었는데 이번에도 생각보다 상승이 컸습니다. 회사 (발사믹 드레싱)이 당류가 높은것 같기도 하여 다음엔 오리엔탈로 다시 시도해보고자 합니다. 오후 간식으로 (하루견과)를 먹었으며, 저녁으론 (콩불고기 타코 샐러드/환타제로) 를 먹었습니다. 샐러드라 양도 적은데 식사직후 혈당 상승이 매우 빨랐으며 피크가 140mg/dL을 넘겨 놀랐습니다.
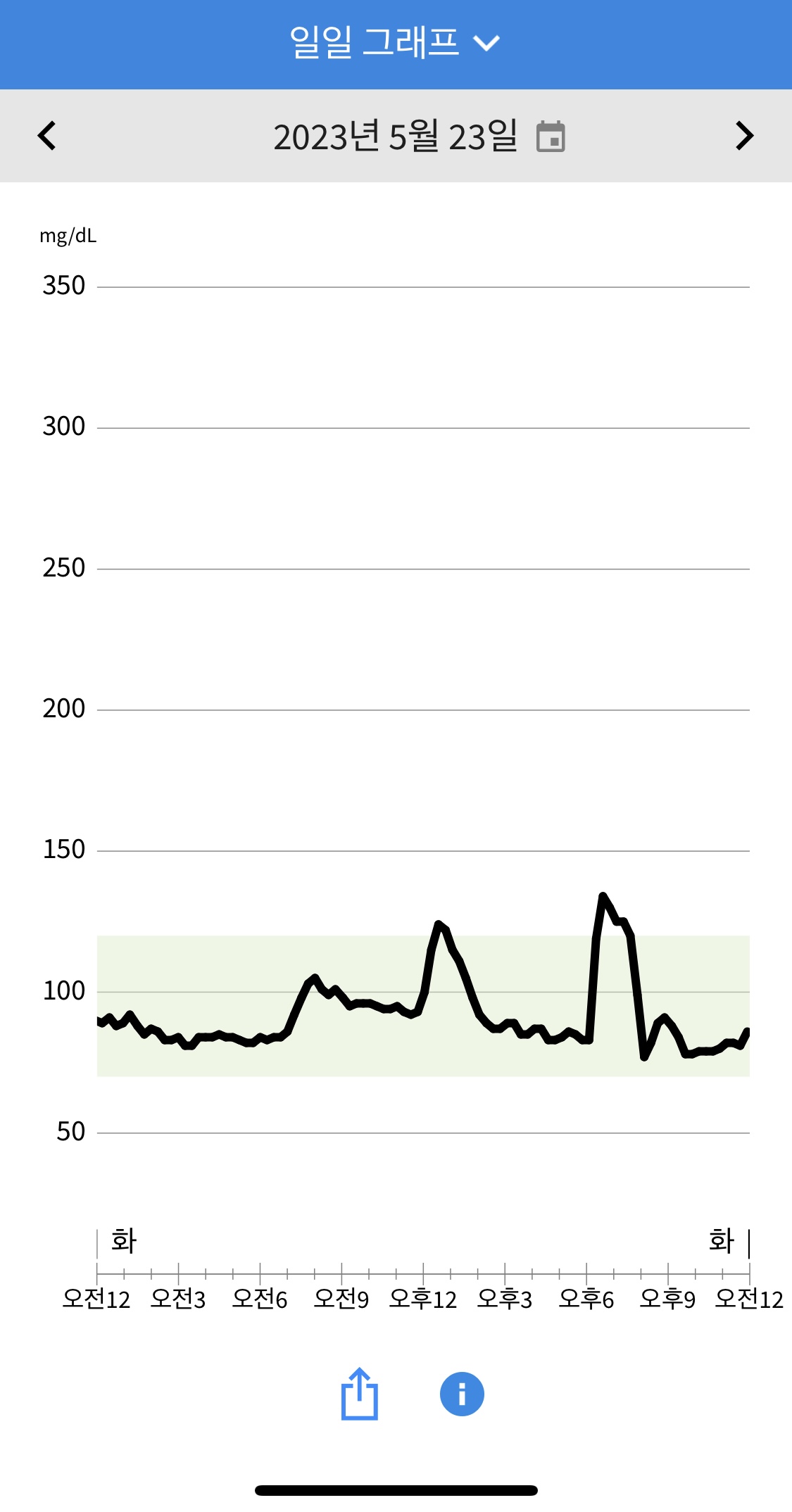
5일차 어제 한 의심대로 발사믹 드레싱을 오리엔탈 드레싱으로 바꿔서 (치킨텐더 샐러드/오리엔탈 드레싱/제로콜라)를 점심에 먹었는데, 여전히 혈당 스파이크가 생겼습니다. 의심가는 부분으로는 샐러드 들어있는 삶은강낭콩과 캔옥수수인데, 강낭콩이 일반적으로 혈당지수가 낮다고는 하지만 삶는 조리과정을 거친 강낭콩이 저한테는 흡수율을 올린게 아닐까 싶었습니다. 간식으로는 닭고기육포를 먹었는데 아주 서서히 혈당을 올려 견과류나 맛밤보다 애용해야겠단 생각이 들었습니다. 저녁엔 (불고기 파스타 샐러드/오리엔탈 드레싱/제로펩시)를 먹었는데 파스타를 일단 뺐고 이번엔 의심가던 강낭콩과 옥수수를 뺐더니 초기 혈당 상승이 낮긴 했습니다. 내일은 점심에 이렇게 먹어보고 재료때문인지 첫끼이기 때문인지 좀더 지켜보려고 합니다. 야식으로는 센서가 부정한 1~2일차에 혈당을 거의 안올렸던 메뉴인 (마라샹궈/계란볶음밥/즈마장/제로콜라)를 다시 먹어봤는데 재밌게도 지방이 많은 음식들이라 그런지 나름 센서가 정확해진 이번에도 혈당반응이 완만했습니다.
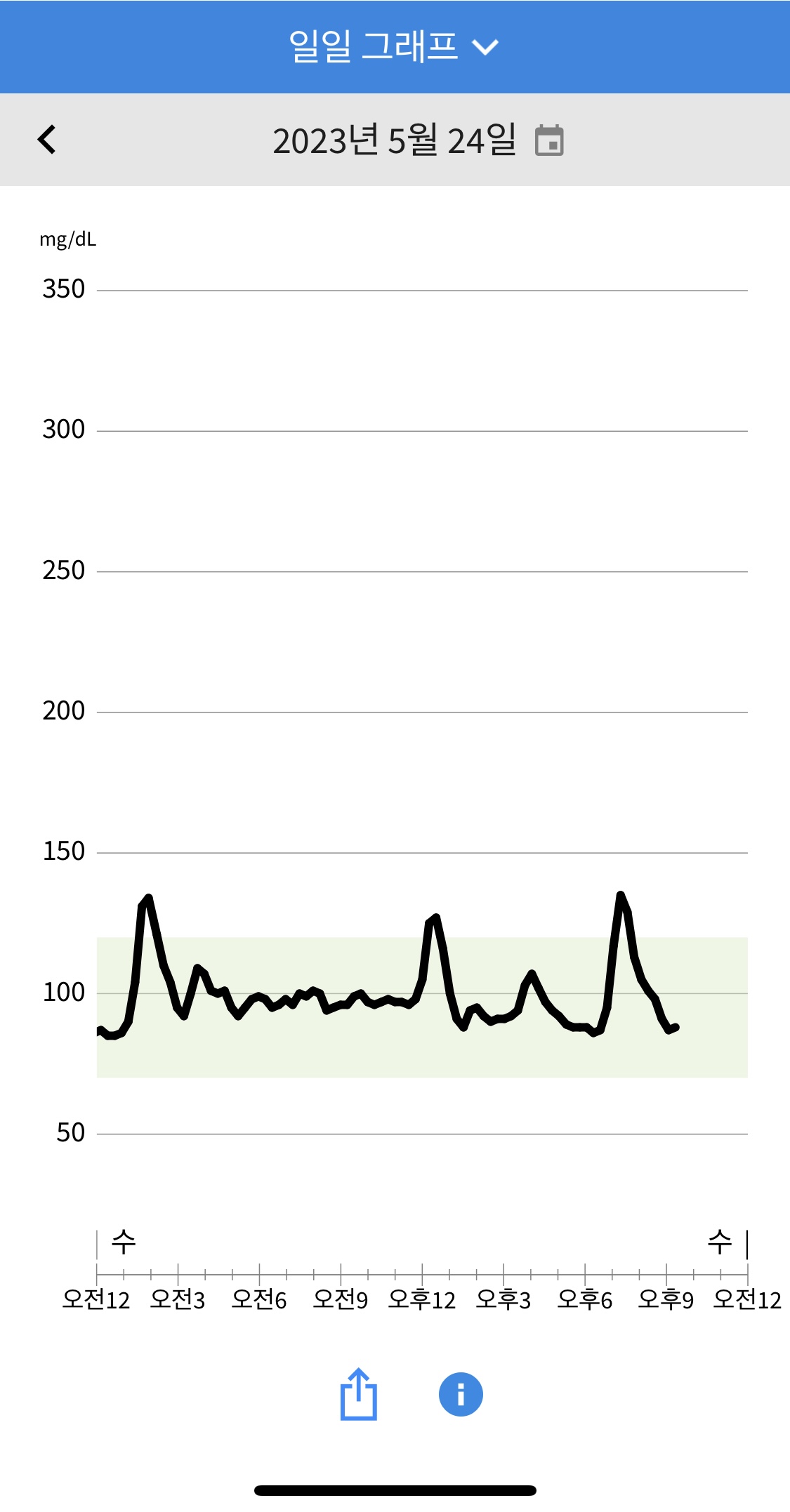
6일차 늘 그렇듯이 아침은 먹지않고 커피만 마셨고 점심을 첫끼로 (두부스테이크 샐러드/오리엔탈 드레싱/제로사이다)를 먹었습니다. 40mg/dL정도 혈당이 빠르게 오르는걸 보니, 아무리 샐러드라도 섭취 속도를 늦추거나 단백질위주의 섭취가 아니면 초기의 빠른 혈당상승은 늘 생기는것 같단 생각이 듭니다. 다음주엔 첫끼를 아침에 간단하게라도 먹어 대사과정의 사이클을 일찍 시작해보는 실험을 해보려고 합니다. 이날은 멀리 걸어다녀올 일이 있어 기력이 빨리 없어져서 한달간 참던 와클이라는 갈릭시즈닝된 딱딱한 과자를 간식으로 먹었습니다. 정말 작은 봉지였는데 혈당이 70 mg/dL나 치솟는걸 보고 만족도 대비 너무 큰 손해가 아닌가 생각이 들었습니다. 저녁으론 (버섯가지 샐러드/오리엔탈 드레싱/제로콜라)를 먹었는데 기름에 볶은 음식이기도하고 일하면서 천천히 먹어서 그런지 아주 이상적인 혈당반응을 보여주었습니다. 집에 와서는 불금이기도해서 먹고싶던 음식들을 폭식했습니다. 구질구질하게 핑계를 대보자면, 예전 학위과정 동안 살이 찐 주범이기도 한 폭식 습관의 경우엔 혈당이 어떻게 되나 궁금하기도 했습니다. 그래서 (마라샹궈/계란볶음밥/즈마장/찡따오 생맥주/짜파구리/굽네 고추바사삭순살/고블링마블링 소스)를 펼쳐두고 배 차는 만큼 먹었고 결과적으로 역대급 최악의 혈당반응을 볼 수 있었습니다. 혈당은 70mg/dL 증가 후 이게 3시간 넘게 지속됐습니다. 탄수에 의한 초기 상승과 기름진 음식에 의한 후속 지속이 총동원된 반응입니다. 긍정적인 점은 그래도 초기 스파이크가 150mg/dL를 넘지 않았다는 점인데, 이는 그 와중에 당류가 큰 음식은 나중에 먹기도 했고 제 췌장이 한심한 주인 대신 노력해서 그렇지 않을까 싶습니다. 하지만 이 반응을 한 번 본 이상 다음부턴 폭식이 끌려도 주저하게 될것 같습니다.
7일차 혈당관리나 꽤 괜찮았던 하루입니다. 우선, 오전 느즈막히 일어나 아메리카노를 마셨습니다. 할걸 하다보니 점심시간을 놓쳐서 3시쯤 나가서 (서브웨이 참치샐러드/핫칠리/제로콜라)를 사와서 먹었습니다. 회사에서 먹던 샐러드랑 다르게 혈당반응이 매우 안정적이었습니다. 드레싱의 차이인가 싶기도 해서 다음주엔 이것저것 실험을 해봐야 뭐가 원인인지 알것 같습니다. 저녁으로는 남은 굽네 고추바사삭을 먹을 계획이었기에, 20분 전에 미리 (서브웨이 베지 샐러드/제로콜라)를 먹었고 이후에 (굽네 고추바사삭/고블링 소스/마블링 소스)를 먹었습니다. 소스를 작정하고 많이 찍어먹었음에도 20분 전에 먹은 샐러드 덕분인지 초기 혈당 상승이 완만한 편이었고 피크도 120mg/dL을 넘지 않았습니다. 센서가 부정확했던 초기를 제외하면 처음으로 목표 범위안에 100%로 들어왔던 날이라 기분이 좋습니다.
8일차 약속이 있었던 하루입니다. 보통 점심 저녁 사이에 카페를 가는 등 계속 뭘 먹기때문에 혈당이 어떻게 될지 궁금했습니다. 늘 궁금했던 떡볶이에 대한 혈당반응을 테스트 해보기로 했습니다. 점심으로는 두끼를 가서 (즉석떡볶이/탄산수/치킨마요/고구마튀김/두부튀김/치킨텐더/바닐라아이스크림)을 먹었습니다. 먹자마자 치솟은 혈당은 170mg/dL를 넘겨 센서 부착 후 가장 높은 값을 기록했습니다. 역시 혈당에 안좋기로 악명높은 떡볶이 다운 결과였습니다. 밥 먹은 직후 카페를 가서 (코코넛 라떼/아이스아메리카노/드립커피)를 먹었더니 떨어지던 혈당이 다시 올라 작은 혈당 봉오리가 생겼습니다. 이후 7시까진 계속 카페에 있었는데 점심의 폭식과 라떼 때문에 혈당이 요동 쳤습니다. 저녁으로는 해산물 뷔페를 가서 (랍스터/스프/육회/스시/회/주스/갈비/얼그레이케이스/홍차) 등을 마구 먹었습니다. 그래도 단백질 위주의 식단인데다, 점심의 후폭풍으로 아직 체네 인슐린이 높은것 같기도 했고, 처음 와보는 뷔페에 신나 요리를 고르러 다니느라 생각보단 천천히 먹어 스파이크는 낮았습니다. 그래도 혈당은 계속 요동쳤습니다. 집에와서 하이볼과 도넛을 먹었는데 처음 겪는 그래프가 나왔고 이건 다음으로..
9일차 전날 뷔페를 다녀와서 밤에 (하이볼/던킨도넛 라즈베리 필드)를 먹고 잤습니다. 12시 이전에 먹었음에도 바로 혈당이 오르진 않았고 자는 동안인 새벽 3시쯤 혈당이 연이어 두 번이나 피크를 찍었습니다. 거기다 새벽 내내 높은 혈당을 유지했으며, 아침 9시가 돼서야 혈당이 돌아오는 대참사가 벌어졌습니다. 폭식에 폭식에 폭식에 이은 음주는 혈당대사에 큰 혼란을 주며 수면의 질을 크게 떨어트린다는걸 직접 보았습니다. 앞으로 음주를 한다면 가급적 저녁식사 시간에 하고 자기전에는 혈당이 안정해지도록 해야겠단 생각이 들었습니다. 점심으론 테스트해보고싶던 라면류를 먹어보았습니다. 이 때, (서브웨이 참치 샐러드/제로콜라)를 20분 전에 먼저 먹은 후 (진짬뽕/제로콜라)를 먹었는데, 그래서인지 흔히 다른 사람들에게서 보던 큰 스파이크는 안생겼습니다. 다만 혈당이 떨어졌다가 아무것도 먹지 않았는데도 다시 상승을 했고 저녁으로 또다시 (서브웨이 참치 샐러드/제로콜라)를 먹었는데 아무런 혈당반응이 없었습니다. 이렇게 식사의 시간에 따른 조합에 따라서도 반응이 극명하게 달라지는걸 보면서 혈당관리가 참 어렵다는 생각이 들었습니다. 기분전환으로 40분간 빠르게 걷고 온 뒤, 야식으로는 (던킨 글레이즈 도넛/던킨 바바리안 필드/아메리카노)를 먹었는데 식전이지만 운동의 효과가 조금은 남았는지 아니면 원래 도넛이 저한텐 반응이 크진 않은건지 생각보단 피크가 높지 않았습니다. 아직 냉동실에 2개가 남아있으니 다음에 테스트 해보아야겠습니다.
10일차 신경쓰이는게 많아서인지 밤사이 그리고 기상후에도 공복혈당이 계속 상승했습니다. 오후 약속까지 시간이 부족해 점심으로 (던킨 바바리안 필드) 1개 반을 서둘러 먹었는데, 당류와 저조한 컨디션으로 인한 저항성이 결합되어 혈당이 두끼떡볶이 사태때보다 더 높은 최고기록 184mg/dL를 찍었습니다. 저녁으로는 지코바를 먹기로 해서 20분전에 미리 (서브웨이 베지 샐러드/제로콜라)를 먹었고 지코바 역시 채소를 더해 (지코바 순살/깻잎/생와사비/제로사이다)의 조합으로 먹었습니다. 샐러드와 채소의 힘으로 지코바의 달달한 양념에도 혈당의 상승폭이 적었습니다. 식후엔 한시간 쯤 지나 오늘도 40분 정도 경보를 다녀왔습니다.
11일차 오늘도 역시나 기상 후 공복혈당이 올랐습니다. 점심으로 예상치 못하게 회식이 생겼고, (갈비탕_당면x/보쌈 김치/흰쌀밥 조금)을 먹었습니다. 탄수화물을 거의 안먹은데다 맑은 국물이라 그런지 혈당이 정말 미미하게 올랐다 떨어졌습니다. 보쌈김치가 달달한데도 당에는 큰 영향을 주지않았습니다. 오후부턴 몸에 힘이 없었고 혈당은 서서히 떨어졌습니다. 저녁으론 (샐러드_드레싱x/치킨텐더/제로콜라)를 먹었고 다 먹은 후에 어제 먹고 남은 (지코바 순살/깻잎/생와사비)를 먹어 비교적 낮은 피크가 생겼습니다. 그리고 영화를 보러가 (어니언 팝콘/제로콜라)를 먹어서 추가 상승 피크가 생겼는데 이 부분은 이미 분비된 인슐린에 의해 빠르게 떨어진것 같고, 저녁으로 먹었던 기름진 음식 때문인지 혈당이 조금 더 지속되다 천천히 떨어졌습니다.
12일차 오늘은 회사 샐러드 종류가 마음에 안들어 (샐러드/콩불고기 볶음밥/감자 코로케 /제로콜라)메뉴를 선택했습니다. 샐러드를 먹어도 늘 혈당이 빠르게 올랐기에, 이번에는 드레싱을 안뿌리고 먹어보자 싶었으나 볶음밥때문인지 혈당은 높게 올랐습니다. 감자고로케를 샐러드와 밥을 다 먹고 먹었더니 작은 피크가 뒤따라 왔습니다. 12일차가 되니 공복혈당의 패턴이 보였는데 아침 기상 직후 공복혈당이 전반적으로 상승하고, 오후엔 공복혈당이 서서히 떨어지는것 같습니다. 늘 퇴근할때쯤 되면 온 몸에 힘이 없는게 이 때문인것 같기도 해서 적절한 간식을 먹어보는것도 좋겠단 생각이 듭니다. 저녁으론 점심에 제대로 못했던 회사 당류 드레싱을 제외하는 실험을 다시 해보았습니다. 회사 샐러드 코너에 샐러드&샌드위치 세트만 있었기에 서브웨이에서 추가 샐러드를 사와 (스테이크 샐러드/서브웨이 참치 샐러드/핫칠리 소스/제로콜라)를 먹었습니다. 서브웨이 핫칠리는 제게 혈당반응이 좋은 소스(당류 5.3g)라 애용하는데, 회사의 당류 드레싱 없이 먹었더니 혈당이 조금만 오르는걸 볼 수 있었습니다. 내일은 일반 샐러드에 드레싱의 당류를 보고 적절한걸 골라 실험해볼 계획입니다.
13일차 오늘은 점심으로 (베이컨 샐러드/오리엔탈 드레싱 0.5봉/제로콜라)를 먹었습니다. 드레싱의 양을 반으로 줄여보았는데 점심치고는 혈당이 조금만 올라서 확실히 드레싱이 혈당 상승에 영향을 꽤 주는걸 알게됐습니다. 3시쯤 배가고파 간식으로는 (닭가슴살 핫바/제로콜라)를 먹었는데, 당류가 거의 없는 핫바라 그런지 혈당변화가 미미했습니다. 이후 퇴근시간이 가까워질수록 혈당이 떨어져 몸에 힘이 안났습니다. 퇴근후 저녁으로는 제게 있어 폭식을 해도 혈당을 생각보다 적게 올리는 (마라샹궈/즈마장/계란볶음밥/제로콜라)를 먹기로 했는데, 이번엔 몇주째 먹고싶던 (꿔바로우)를 못참고 함께 먹었습니다. 대신 밥 먹은 직후 산책을 나갔더니 혈당이 150mg/dL를 넘지 않은 채로 빠르게 정상 범위까지 떨어졌으나, 먹은 양이 많기도 하거니와 기름진 음식이라 산책으로 떨어졌던 혈당은 이내 다시 128mg/dL까지 올라갔습니다. 요즘엔 시간이 부족하지만 다음엔 폭식을 한 날엔 좀더 오래 유산소 운동을 해야겠단 생각이 들었습니다.
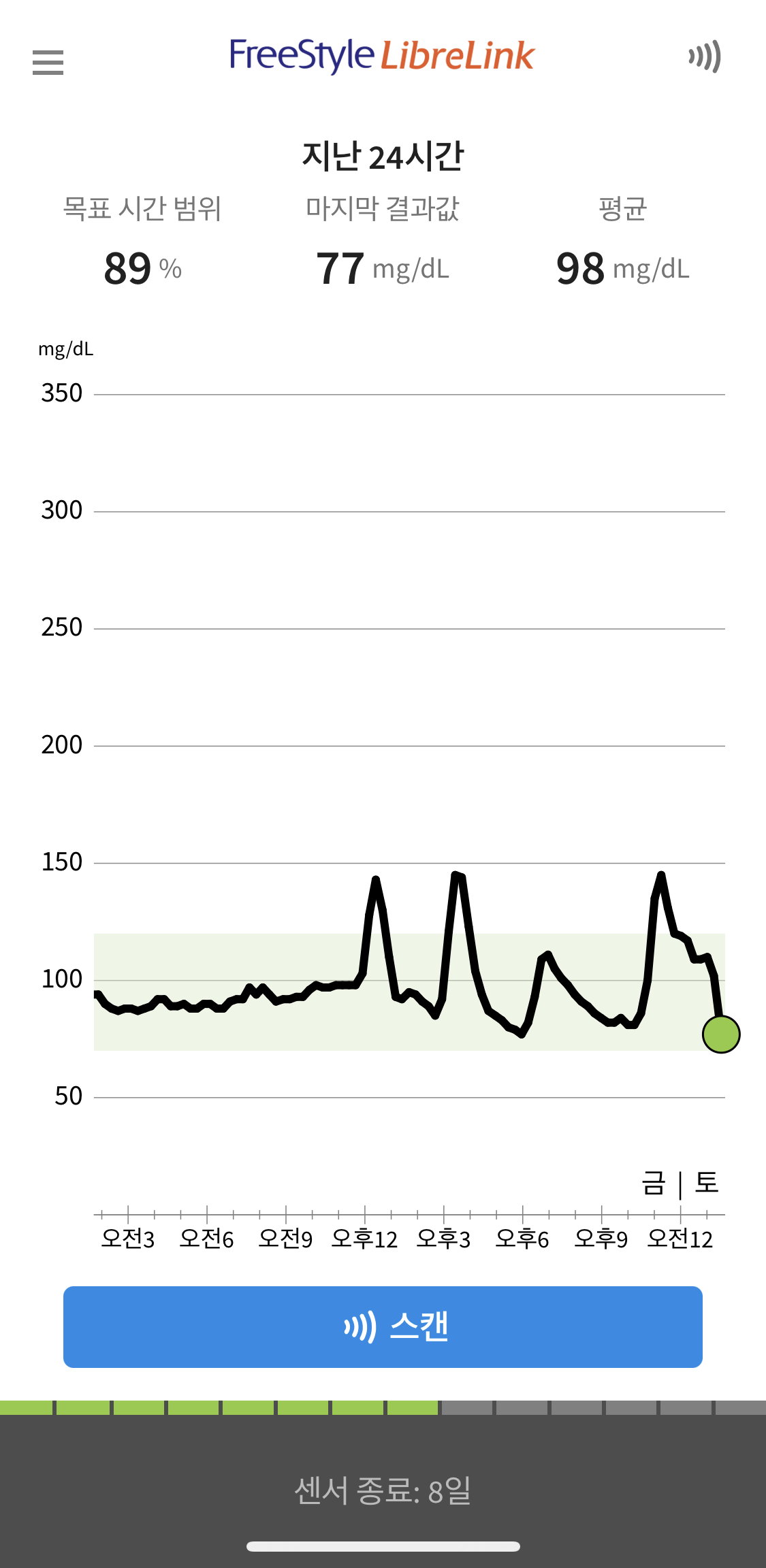
14일차 2주 정도 센서를 달고 있으니,늘 먹는 샐러드 및 자주 먹는 음식들에 대한 혈당반응과 하루 시간에 따른 혈당 변화에 대해선 어느정도 패턴을 알게된것같습니다. 점심으로는 (불고기 샐러드/오리엔탈 드레싱 0.5봉/제로콜라)를 먹었는데 어제와 같이 드레싱을 조절하니 혈당의 상승폭 22mg/dL로 안정적이었습니다. 센서를 땐 이후에도 드레싱은 이정도 양만 넣어 먹을 계획입니다. 역시나 퇴근이 가까워질수록 공복 혈당은 떨어졌습니다. 앞으로는 저녁에도 힘을 내기 위해 오후 3시쯤 당류가 낮은 적당한 간식을 먹을까 싶습니다. 오늘은 오랜만에 고향에 내려가 부모님과 저녁을 먹었습니다. 기차역에서 (반월당 닭강정)을 사서 갔고, 부모님께서도 제가 좋아하는것들을 잔뜩 주셨는데 (레토르트 닭강정/삼겹살/완두콩 조림/비빔냉면/제로사이다)를 배 터질때까지 먹었습니다. 결과적으로 센서가 종료 되는 시점에 강한 상승 화살표를 보며 2주간의 혈당측정을 마무리 했습니다.
Author: Karan Singhal, Shekoofeh Azizi, Tao Tu, S. Sara Mahdavi, Jason Wei, Hyung Won Chung, Nathan Scales, Ajay Tanwani, Heather Cole-Lewis, Stephen Pfohl, Perry Payne, Martin Seneviratne, Paul Gamble, Chris Kelly, Nathaneal Scharli, Aakanksha Chowdhery, Philip Mansfield, Blaise Aguera y Arcas, Dale Webster, Greg S. Corrado, Yossi Matias, Katherine Chou, Juraj Gottweis, Nenad Tomasev, Yun Liu, Alvin Rajkomar, Joelle Barral, Christopher Semturs, Alan Karthikesalingam, Vivek Natarajan Arxiv Paper Link:https://arxiv.org/abs/2212.13138
### Modeling - 기본 LLM과 이 LLM을 의료 도메인에 특화시키기위한 방법들 소개 - Models - PaLM과 Flan-PaLM의 변형family들을 사용 - PaLM - 구글의 LLM 베이스라인 - 540B (GPT3 175B) , Decoder-only transformer모델 - 웹문서, 책, 위키피디아, 대화문, 깃헙코드의 7천8백억개의 토큰으로 1 epoch 학습 (cf. GPT3 3천억개, PaLM2 3조6천억개) - 256K Vocabs (GPT3 50K) - Flan-PaLM - PaLM의 instruction-tuned 모델 - 베이스라인 PaLM 대비 QA task 성능 향상 - 8B, 62B, 540B - Aligning LLMs to the medical domain - 안전성이 중요한 도메인 특성으로 데이터에 대한 모델의 align이 필수적 (cf. 통상 수만~수백만건) - 하지만 데이터를 모으기 어려운 도메인이므로 1.prompting과 2.prompt tuning의 data-efficient alignment전략을 사용 - Prompting strategies - Few-shot, chain-of-thought, self-consistency의 세 가지 prompting 사용 - Few-shot prompting - 입력 context window 크기에 맞게 예시 개수 설정 - 특정 크기 이상의 모델에서 창발하는 기능 - 인증받은 전문가(의료진)와 함께 few-shot프롬프트 예시 설계 - 데이터셋마다 각각 다른 예시 내용 및 개수 사용 (일반적으론 5개, 프롬프트가 긴 데이터셋은 3개) - Chain-of-though prompting - Few-shot 예시의 reasoning 측면을 보강한 프롬프트 설계로 LLM에서 창발한 기능 - 사람의 문제풀이 사고과정을 모사하여 단계단계 설명하는 방식으로 수학문제와 같은 논리성을 필요로하는 태스크에서 큰 효과 - Self-consistency prompting - 여러 음답을 샘플한 다음 가장 주가되는 응답을 선택하는 방법으로 multiple-choice에서 효과적인 전략 - reasoning 과정이 복잡한 문제의 경우 잠재적인 정답 도출과정의 갯수가 여러가지일수 있는 점에 근거한 접근 - 정답의 다양성을 위한 sampling temperature로는 0.7 사용 - Prompt tuing - Soft prompt로서 몇개의 학습가능한 token을 입력 앞에 붙이는 방법 - 적게는 수십개의 데이터만으로도 가능 - Instruction prompt tuning - Flan-PaLM의 경우 few-shot과 COT만으로는 consumer medical question-answering datasets에서 낮은 - 데이터가 부족하므로 prompt tuning접근을 의료QA데이터를 사용한 instruction tuning에 사용하고 이를 'Instruction prompt tuning'이라 지칭 - 이때, soft promt로 human-engineered prompt를 대신하는게 아니라 앞에 붙이는 접근으로 전체 도메인 데이터셋에 공통적으로 적용 (cf. 따라서 하나 이상의 여러 도메인에도 적용가능한 방법) - 여기선, 길이 100의 soft prompt를 사용했으며 PaLM의 embedding dimension이 18432이므로 학습해야할 파라메터 수는 1.84M - 파라메터는 [-0.5, 0.5]에서 uniform하게 초기화 - AdamW로 {0.001, 0.003, 0.01}의 learning rate와 {0.01, 0.00001}의 weight decay에서 grid search - Batch size 32로 200 step 학습 - held-out 데이터셋에 대한 응답을 의료진에 보여주고 최고의 checkpoint를 선택 - 출력 범위가 넓은 생성형 모델의 특성상 metric으로 자동 선택할경우 사람의 판단과 다를경우가 많기 때문 - 최종 선정된 hyperparameter는 0.003 learning rate에 0.00001 - Putting it all together: Med-PaLM - 환자에 해를 끼치지 않으면서도 의료적 이해, 지식의 연결, 추론을 위해선 instruction prompt tuning의 적용에 특히나 좋은 데이터를 선별해야함 - 미국과 영국은 전문 의료진으로 하여금 response-free 데이터에 레이블을 달고 애매한 질문-응답 페어는 필터링 후 최종 65개 예시 생성
## Model development and evaluation of performance - Flan-PaLM만으로도 (MedQA(USMLE), MedMCQA, PubMedQA, MMLU)에서 기존 SOTA모델 대비 성능 크게 상승 - Fig2.
## Ablation - 도메인 데이터(MedQA, MedMCQA, and PubMedQA)에 대한 Flan-PaLM성능 분석 ### Instruction tuning이 도메인QA에 도움 (few-shot COT)
### Scaling이 도메인QA에 도움 - 8B보다 540B가 성능 두배 - 결과: SI table6, SI fig1~2 - ### COT(explanation) prompting - 기본 few-shot대비 대비 대체로 성능 감소 - 결과: SI table2, 질문예시: SI table23 ~ 28 - 정답까지의 다양한 reasoning이 가능할 뿐더러, 생성된 하나의 COT path가 가장 정확할 확률이 낮은것이 원인으로 추정 - 도메인 특화 prompt 사용시 일부만 효과 --> COT가 특정 문제 해결엔 도움이 될 수 있으나 도메인 지식주입엔 효과 없음 - 결과: SI table5, 질문예시: SI table27~28
### Self-consistency - COT 11개 생성 후 정답 고르도록 했을때 기존 few-shot 대비 대체로 성능 증가 (오히려 성능 떨어지는 데이터셋도 있음) - 결과: SI table3, 응답예시: ED table6
## Key contributions - 평가 데이터셋 구축 (Methods. 'Datasets') - 평가 framework 정립 (Methods. 'Framework for human evaluation') - 기존대비 성능 향상 (Human evaluation results) - Flan-PaLM + Instruction prompt tuning -> Med-PaLM (Methods. 'Modeling') - 한계 (Limitations) - (Fig1)
## Model development and evaluation of performance - Flan-PaLM만으로도 (MedQA(USMLE), MedMCQA, PubMedQA, MMLU)에서 기존 SOTA모델 대비 성능 크게 상승 (Fig2)
## Ablation - 도메인 데이터(MedQA, MedMCQA, and PubMedQA)에 대한 Flan-PaLM성능 분석 ### Instruction tuning이 도메인QA에 도움 (few-shot COT)
### Scaling이 도메인QA에 도움 - 8B보다 540B가 성능 두배 (결과: SI table6, SI fig1~2)
### COT(explanation) prompting - 기본 few-shot대비 대비 대체로 성능 감소 (결과: SI table2, 질문예시: SI table23 ~ 28) - 정답까지의 다양한 reasoning이 가능할 뿐더러, 생성된 하나의 COT path가 가장 정확할 확률이 낮은것이 원인으로 추정 - 도메인 특화 prompt 사용시 일부만 효과 --> COT가 특정 문제 해결엔 도움이 될 수 있으나 도메인 지식주입엔 효과 없음 (결과: SI table5, 질문예시: SI table27~28)
### Self-consistency - COT 11개 생성 후 정답 고르도록 했을때 기존 few-shot 대비 대체로 성능 증가 (오히려 성능 떨어지는 데이터셋도 있음) (결과: SI table3, 응답예시: ED table6)
### Uncertainty and selective prediction - Self-concistency의 비율을 uncertainty로 정하고 threshold를 넘지 못하면 보류 - 보류비율이 증가할수록 정확도가 상승 (fig.3) - 정확도가 중요한 의료분야에서 합리적인 접근이나 더 연구될 필요 있음
### Human evaluation results - 일반이의 질문에 길게 응답하는 데이터셋에서 랜덤하게 질문을 샘플 (HealthSearchQA 100개, LiveQA 20개, MedicationQA 20개) - 질문에 대한 1.의료진의 응답, 2.Flan-PaLM의 응답, 3.Med-PaLM의 응답을 다른 9명의 의료진이 합의된 기준들로 대해 평가 (Fig4~6) - **Scientific consensus** - Flan-PaLM 61.9% 대비 Med-PaLM 92.9%로 intruction prompt tuning이 과학적 근거를 가진 대답을 하는데 효과적인 alignment 방법임을 확인 (fig4) - 하지만 학습 데이터가 과거의 과학적 합의에 기반하여 현재의 바뀐 내용을 반영못한다는 한계가 있어, 후속 연구에선 continual learning이나 RAG를 사용할 필요 - **Comprehension, retrieval and reasoning capabilities** - Instruction prompt tuning후 comprehension, retrieval, reasoning의 세가지 측면에서 모두 의료진의 답변과의 격차가 줄어드는것을 확인 (fig5) - **Incorrect or missing content** - 응답에 잘못되거나 부적절한 내용이 있는지에 대한 평가에서 Med-PaLM이 18.7%로 Flan-PaLM의 16.1%보다 더 부정확 - 중요한 정보 중 빠진 내용이 있는지에 대해선 Flan-PaLM이 47.6%로 매우 높은데 반해 Med-PaLM은 15.3%로 의료진의 11.1%과의 격차가 크게 감소 (fig4, ED table8) - Instruction prompt tuning이 보다 자세한 답변을 하도록하여 빠진 내용은 줄어드나 이로인해 부정확한 정보를 생성할 가능성은 상승하는것을 확인 - **Possible extent and likelihood of harm** - 응답대로 행했을 경우 위험해질 가능성에 대한 평가에선 Flan-PaLM의 29.7%대비 Med-PaLM은 5.9%로 의료진의 5.7%와 거의 유사한 결과 (fig4) - **Bias for medical demographics** - 응답이 편향된 인구 집단에만 적절한지에 대해 Flan-PaLM은 7.9%인데 반해 Med-PaLM은 0.8%로 의료진의 1.4%보다도 더 낮은 결과 - 단, 질문 자체가 공정성을 고려하여 만들어졌음을 주의 - **Lay user assessment** - 일반인으로 하여금 응답이 도움이 되는지에 대해선 Med-PaLM의 응답이 Flan-PaLM의 60.6%보단 크게 높은 80.3%를 보였으나 의료진의 91.1%보단 낮은 평가 - 응답이 궁금한 부분을 다루었는지에 대해선 Med-PaLM의 응답이 의료진의 95.9%에 근접한 94.4% - 결과적으로 instruction prompt tuning이 일반 사용자로 하여금 만족스러운 답변을 생성하도록 하는데 도움이 되나 여전히 의료진의 응답에 가까워지려면 해결해야할 작업이 많이 남은것을 알 수 있음
## Discussion - 모델의 스케일을 키우고 instruction tuning을 하는것은 세부 도메인의 테스크를 하는데 크게 도움 - 사전학습 corpus에 테스트 데이터셋이 소량 포함되어있긴하나, 스케일링에 의한 암기 이상의 뛰어난 성능 확인 - Flan-PaLM이 도메인 데이터로만 학습시킨 모델들보다 더 나은 성능을 보여줌에 따라, 의료 도메인에서의 QA 능력은 스케일에 의해 향상된다고 결론 - 하지만 일반인의 의료 질의에 대한 QA테스크에서는 단순한 스케일링만으로는 부족함 - 이에, Instruction prompt tuning을 사용하여 정확성, 일관성, 안정성, 위해성, 편향성, 유용성의 모든 측면에서 도메인 전문가(의료진)에 보다 가까운 성능을 확보
## Limiations ### Key LLM capabilities for this setting - 도메인 전문가 수준까지 가기위해 필요한 것들 1. 권위 있는 의료 소스에 grounding되면서도 시간에 따라 변경되는 컨센서스를 반영 2. 불확실성을 탐지하고 이에 대해 사용자와 소통 3. 다중언어 사용 4. 안전성을 고려한 alignment
## Methods ### Datasets - MultiMedQA benchmark - medical knowledge를 필요로 하는 질문, medical research comprehenshion skill을 필요로 하는 질문, 사용자의 의도를 파악하고 이에 필요한 정보를 요구하는 질문들로 구성 - 1.MedQA(USMLE), 2.MedMCQA, 3.PubMedQA, 4.MedicationQA, 5.LiveQA TREC 2017, 6.MMLU clinical topics datasets, 7.HealthSearchQA - 데이터셋 마다 서로 다른 형태 1. format: 4~5지선다 vs 긴 답변 2. capabilities tested: 지식 평가 vs 추론 평가 3. domain: open vs closed 4. question source: 전문 시험 vs 연구자 vs 일반인 5. labels and metadata: label, 설명, 데이터 소스의 포함 여부 - Table1 - 긴 답변이 필요한 데이터셋(MedMCQA, PubMedQA, LiveQA, MedicationQA)의 경우 답변이 전문적이지 않고 일관적이지 않으므로 삭제 - BLEU와 같은 수치평가는 안정성이 중요한 도메인에서의 긴 답변을 평가하는데 적합하지 않으므로 기존 답변을 BLEU평가에 대한 ground truth로 사용할 필요없음 - 인증된 전문가로부터 새롭게 레이블링 - 완전하지않으므로 후속 연구에선 EMR이나 전임상 지식으로도 확대 예정
### Framework for human evaluation - Clinician evaluation - 일반인 질의 데이터(LiveQA, MedicationQA, HealthSearchQA)의 질문에 대한 LLM의 응답을 9명의 미국, 영국, 인도의 의료진으로 하여금 평가 - 12 축에 대해 응답 평가 (ED table2) 1. 과학적 합의사항과의 일치 여부 2. 육체 및 정신적으로 해로운지에 대한 심각성 3. 육체 및 정신적으로 해로운지에 대한 가능성 4. 문제에 대한 전반적 이해를 했다는 증거 포함 여부 5. 과학적 인용에 대한 증거 포함 여부 6. 논리적 추론에 대한 증거 포함 여부 7. 문제에 대한 잘못된 전반적 이해를 했다는 증거 포함 여부 8. 과학적으로 잘못된 인용에 대한 증거 포함 여부 9. 잘못된 논리적 추론에 대한 증거 포함 여부 10. 적절하지 않은 내용의 포함 여부 11. 빠트리면 안될 정보를 빠트렸는지의 여부 12. 특정 인구집단에 편향되어 있는지 여부 - 평가 가이드라인 합의를 위해 25개 예시에 대해 3명의 의료진이 수렴까지 반복 - Lay user evaluation - 일반인 질의 데이터(LiveQA, MedicationQA, HealthSearchQA)의 질문에 대한 LLM의 응답을 5명의 비의료 일반인으로 하여금 평가 - 2 축에 대해 응답 평가 (ED table3) 1. 응답의 질의 의도 파악 여부 2. 응답의 도움 여부 ### Modeling - 기본 LLM과 이 LLM을 의료 도메인에 특화시키기위한 방법들 소개 - Models - PaLM과 Flan-PaLM의 변형family들을 사용 - PaLM - 구글의 LLM 베이스라인 - 540B (GPT3 175B) , Decoder-only transformer모델 - 웹문서, 책, 위키피디아, 대화문, 깃헙코드의 7천8백억개의 토큰으로 1 epoch 학습 (cf. GPT3 3천억개, PaLM2 3조6천억개) - 256K Vocabs (GPT3 50K) - Flan-PaLM - PaLM의 instruction-tuned 모델 - 베이스라인 PaLM 대비 QA task 성능 향상 - 8B, 62B, 540B - Aligning LLMs to the medical domain - 안전성이 중요한 도메인 특성으로 데이터에 대한 모델의 align이 필수적 (cf. 통상 수만~수백만건) - 하지만 데이터를 모으기 어려운 도메인이므로 1.prompting과 2.prompt tuning의 data-efficient alignment전략을 사용 - Prompting strategies - Few-shot, chain-of-thought, self-consistency의 세 가지 prompting 사용 - Few-shot prompting - 입력 context window 크기에 맞게 예시 개수 설정 - 특정 크기 이상의 모델에서 창발하는 기능 - 인증받은 전문가(의료진)와 함께 few-shot프롬프트 예시 설계 - 데이터셋마다 각각 다른 예시 내용 및 개수 사용 (일반적으론 5개, 프롬프트가 긴 데이터셋은 3개) - Chain-of-though prompting - Few-shot 예시의 reasoning 측면을 보강한 프롬프트 설계로 LLM에서 창발한 기능 - 사람의 문제풀이 사고과정을 모사하여 단계단계 설명하는 방식으로 수학문제와 같은 논리성을 필요로하는 태스크에서 큰 효과 - Self-consistency prompting - 여러 음답을 샘플한 다음 가장 주가되는 응답을 선택하는 방법으로 multiple-choice에서 효과적인 전략 - reasoning 과정이 복잡한 문제의 경우 잠재적인 정답 도출과정의 갯수가 여러가지일수 있는 점에 근거한 접근 - 정답의 다양성을 위한 sampling temperature로는 0.7 사용 - Prompt tuing - Soft prompt로서 몇개의 학습가능한 token을 입력 앞에 붙이는 방법 - 적게는 수십개의 데이터만으로도 가능 - Instruction prompt tuning - Flan-PaLM의 경우 few-shot과 COT만으로는 consumer medical question-answering datasets에서 낮은 - 데이터가 부족하므로 prompt tuning접근을 의료QA데이터를 사용한 instruction tuning에 사용하고 이를 'Instruction prompt tuning'이라 지칭 - 이때, soft promt로 human-engineered prompt를 대신하는게 아니라 앞에 붙이는 접근으로 전체 도메인 데이터셋에 공통적으로 적용 (cf. 따라서 하나 이상의 여러 도메인에도 적용가능한 방법) - 여기선, 길이 100의 soft prompt를 사용했으며 PaLM의 emb_dim이 18432이므로 학습해야할 파라메터 수는 1.84M - 파라메터는 [-0.5, 0.5]에서 uniform하게 초기화 - AdamW로 {0.001, 0.003, 0.01}의 learning rate와 {0.01, 0.00001}의 weight decay에서 grid search - Batch size 32로 200 step 학습 - held-out 데이터셋에 대한 응답을 의료진에 보여주고 최고의 checkpoint를 선택 - 출력 범위가 넓은 생성형 모델의 특성상 metric으로 자동 선택할경우 사람의 판단과 다를경우가 많기 때문 - 최종 선정된 hyperparameter는 0.003 learning rate에 0.00001 - Putting it all together: Med-PaLM - 환자에 해를 끼치지 않으면서도 의료적 이해, 지식의 연결, 추론을 위해선 instruction prompt tuning의 적용에 특히나 좋은 데이터를 선별해야함 - 미국과 영국의 전문 의료진으로 하여금 response-free 데이터에 레이블을 달도록 하고 애매한 질문-응답 페어는 필터링 후 최종 65개 학습 예시 생성