
Author : Sehoon Ha*, Peng Xu, Zhenyu Tan, Sergey Levine, and Jie Tan
Paper Link : https://arxiv.org/abs/2002.08550
Video Link: youtu.be/cwyiq6dCgOc
0. ABSTRACT
- 사람의 최소한의 개입만으로 4족 보행로봇의 locomotion을 RL로 학습가능한 on-robot learning 시스템을 개발함
- Real-world RL은 학습과정에서의 자동화된 데이터 수집과 안전성의 문제가 근본적으로 있음
- 이를 극복하기 위해 1.multi-task learning/ 2. automatic reset controller/ 3. safety-contrained RL 의 세 가지 방법을 도입함
- 제안된 방법을 4족보행 로봇에 적용한 결과, 서로 다른 지형에서 사람의 개입없이도 단 몇시간 만에 지형에 특화된locomotion을 학습 하는것이 검증됨

1. INTRODUCTION
- 기존의 hand-engineered controller와 달리 RL은 자동화된 학습을 scratch부터 가능하게 만들었으나, 아직 simulation 환경에서만 주로 검증 됨
- 하지만 simulation으론 로봇이 실제로 마주할 환경을 충분히 구현하기 어렵다는 한계가 있으므로, 이 연구에서는 real world에서 자동적으로 학습이 되는 on-robot RL의 개발을 목적으로 함
- Real-world RL은 stable, efficient, safe, automated 의 조건을 필요로함
- 이 중 여기서는 특히 automation과 safety문제를 다루기 위해 robot의 반경을 재한하고, 위험하게 넘어지는 일을 줄이며, episode간 리셋을 자동화 하는 방법을 모색
- 결과적으로 저자의 지난 논문에선 Soft Actor-Critic을 사용한 로봇 locomotion 학습과정에 있어 수 백번의 수동 리셋을 한 반면, 이번 시스템에서는 단 한번의 리셋을 하지 않음
2. RELATED WORK
- 기존의 보행 로봇제어는 다층의 모듈설계로 구현됨 (ex. state estimation, foot-step planning, trajectory optimization, model predictive control)
- 하지만 로봇 플랫폼 및 task가 복잡할땐 prior knowledge를 알기 어려움
- 반면 RL기반의 보행 로봇 제어는 end-to-end training system으로 prior knowledge없이도 실제 경험을 통해 자동으로 locomotion을 학습 가능
- RL을 사용한 로봇제어는 많이 연구되었지만 대부분 simulation 환경에서 이루어짐
- Simulation에서 학습된 policy를 real-world 로봇으로 transfer하는데엔 두 환경 사이이 불일치(discrepancy)한다는 큰 한계가 있어, on-robot training system을 위한 많은 시도 (ex. system id, domain randomization, meta-learning) 가 현재 진행중이나 여전히 문제로 남아있음
- RL을 보행로봇에 적용하는데는 다음 두 가지 challenge가 있음
1. Episode가 끝날때마다 로봇의 적절한 initial state로의 reset
2. 학습 프로세스에서 로봇의 안전성 보장 - 특히 2번은 "Safety in RL"로 지칭되는 contrained Markov Decision Process (cMDP) 문제로서 주로 Lagrangian relaxation으로 접근하며, 이 외에도 다양한 방법들이 시도되고 있음 (ex. additional safety layer, safe boundary classifier, progressive safe region identification, alongside reset policy)
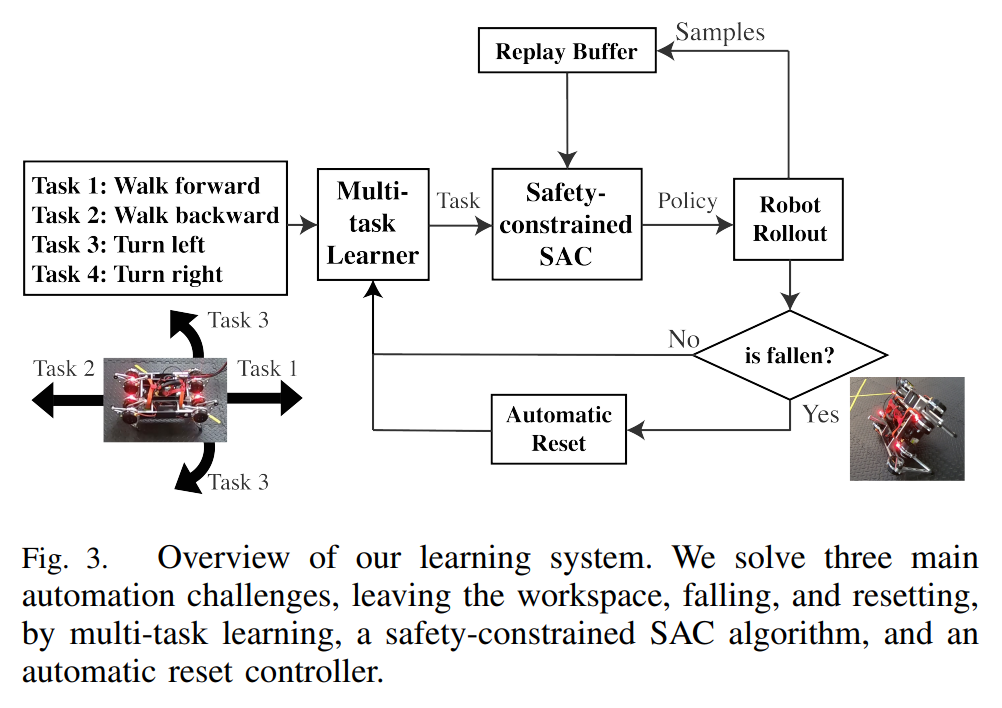
3. OVERVIEW
- 이 연구의 목적은 real world에서의 locomation을 학습하기위해 사람의 개입을 최소화 하는 자동화된 시스템을 개발하는 것
- 시스템의 구현에 있어 존재하는 3가지 challenge와 그 해결방법은 다음과 같음
- 1. 로봇은 training area (workspace) 안에 있어야 함
$\therefore$ 보행 방향을 각각 하나의 task로보고 로봇이 workspace를 벗어나지 않도록 적절한 task를 선택해 학습하는, multi-task learning 활용 - 2. 로봇의 넘어짐 학습시간을 더디게 하거나 기체를 파손시키므로 그 횟수가 최소화 되어야 함
$\therefore$ SAC 수식에 로봇의 종축(roll)과 횡축(pitch)에 대한 safety constraint를 추가해 cMDP 문제를 품 - 3. 넘어짐을 피할 수 없을경우, 자동화된 자세 복구가 되어야 함
$\therefore$ 직접 하드코딩한 stand-up controller를 추가함 - 이를 요약한 전체 automated on-robot learning system은 다음과 같음
4. PRELIMINARY: REINFORCEMENT LEARNING
- RL의 기본 내용이므로 생략
5. AUTOMATED LEARNING IN THE REAL WORLD
A. Multi-Task Learning
- multi-task learning을 위해서 보행 방향을 전/후 2가지, 혹은 전/후/좌회전/우회전의 4가지를 task로 설정
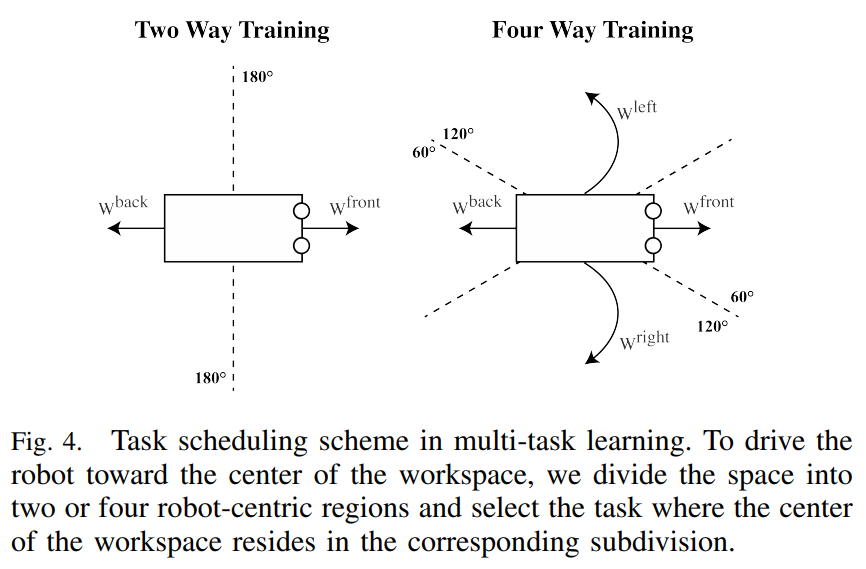
- Task scheduler를 두고, episode 시작 시 workplace의 중앙이 로봇의 방향구획 중 어디에 속하는지에 따라 scheduler가 task를 결정
- Task vetor는 $\textbf{w}=[\omega_{1}, \omega_{2}, \omega_{3}]^T$으로 정의되며, 이 방향과 일치할 경우 가장 큰 reward를 받도록 task reward $r$을 다음과 같이 정의
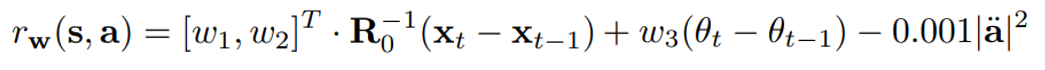
- $\ddot{a}$는 motor 가속도로서 action을 부드럽게 하는 역할
- 이러한 multi-task를 사용한 학습 자동화는 policy가 불완전한 초기 상황에서도 해당 task의 방향으로 조금이나마 움직인다는 가정 1 과, 한 task의 방향과 반대 방향의 task가 존재한다는 가정 2를 내포
- 가정 1의 경우, 중앙으로부터 멀어지려는 task가 없기때문에 가능하며 실제로 약 10~20 roll-out 이후엔 1cm라도 움직이기 시작
- 다만 task마다 별개의 다른 네트워크로 별도의 학습을 진행하며, shared achitecture에선 성능이 안나옴
- 이는 task가 discrete하게 설정 된 점과, 각 task간의 경험이 서로의 학습에 이점이 없기 때문으로 추정
- Task는 episode 처음에 정해지면 episode 동안은 고정되어 있으므로 roll-out이 길어질 경우 원치 않게 boundary를 벗어날 수 있으므로, 이 같은 상황에선 early termization 수행
B. RL with Safety Constraints
- MDP문제를 cMDP문제로 만들기위해 기존의 RL objective에 safety constraints $f_{s}$를 추가하면 다음과 같음

- 여기서는 로봇의 넘어짐을 제한하기 위해 본체의 pitch와 roll에 bound를 주고 이를 다음과 같이 constraint로 정의
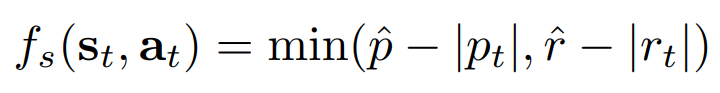
- $p_{t}$와 $r_{t}$는 각각 pitch와 roll의 각도이며, $hat{p}$와 $hat{r}$는 각각의 최대 bound로서, $\pi/12$ 와 $\pi/6$으로 설정함
- Constrained optimization엔 여러 해법이 있는데, 여기서는 Lagrangian 방법을 사용하여 constrained prior problem을 unconstrained dual problem을 바꿔 gradient descent로 최적화 (Lagrangian은 간단히는 CS287, 자세히는 '모두를 위한 컨벡스 최적화'를 참고)
- Lagrangian multiplier $\lambda$ 를 도입하여 위 constrained objective를 다시 쓰면 다음과 같음
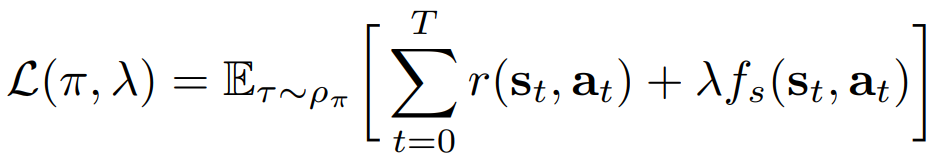
- 이 목적함수의 최적화를 위해 policy $\pi$와 Lagrangian multiplier $\lambda$를 번갈아 최적화 하는 dual grdient decent 방법을 사용함
- 먼저 기본 reward에 대한 Q함수와 safety term에 대한 Q함수를 각각 $\theta$와 $\psi$로 parameterize한 $Q_{\theta}$와 $Q^s_{\psi}$를 학습
- 여기서는 SAC를 알고리즘으로 사용하므로, SAC논문에서의 actor loss에 safety term을 추가한 다음 식을 actor loss로 설정 (SAC에 대한 내용은 블로그의 정리 포스팅 참고)
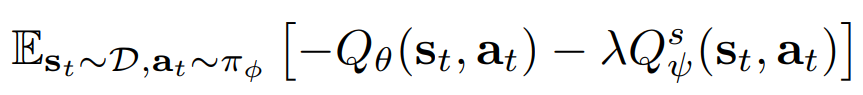
- 그리고 Lagrangian multiplier $\lambda$에 대한 loss는 constrained objective에서 $\lambda$ term만 남아 다음과 같음
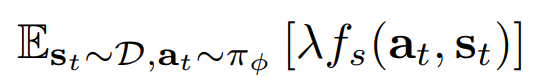
- 위 두 loss에 대해 번갈아 gradient descent를 시행하여 constrained optimization 수행
C. Additional System Designs for Autonomous Training
- Multi-task와 constrained optimization의 방법은 학습과정을 자동화했으나 디테일한 부분에서의 몇가지 보완이 필요함
- 특히 RL의 근간이 실패를 통해서 배우는 알고리즘이므로 넘어짐을 완전히 없애긴 어려워, manually-engineered된 stand-up controller를 개발해 추가함
- 외에도 로봇이 일어날 공간 및 줄꼬임 방지 등의 물리적인 부분을 위한 보조 도구들이 사용

- 또한 random exploration으로 인한 너무 급격한 변화로 인해 모터가 마모하는것을 완화하고자 first-order low-pass Butterworth filter를 사용하여 action을 post-processing
6. EXPERIMENTS
- 실험은 flat terrain에서 전후 2가지 task와, 전후회전의 4가지 task에 대해 각각 진행되었으며, challenging terrain에서 전후 2가지 task로 진행됨
- 실험 결과, 사람의 개입이 전혀 없이도 모든 terrain에서 모든 task를 잘 학습함
- 사람의 무개입과 효율적인 학습 알고리즘으로 wall clock기준 80분만에 task를 학습함
- 특히 SAC의 저자의 연구인 지난 state-of-the-art on-robot locomotion learning 실험에선 수백번 직접 reset한 것과 비교하면 매우 현실적인 학습과정이라 볼 수 있음



- Episode 시작 위치와 움직이는 방향을 관측 해 본 결과, task scheduler에 의해 workspace를 벗어나지 않고 중앙으로 향하도록 적절히 학습이 진행된 것을 아래 plot에서 확인 할 수 있음

- 의도한 자동화 시스템 설계 (1.multi-task, 2. safety-constrained SAC) 가 정말로 유의미한 효과가 있는지 확인하고자 ablation 학습을 추가적으로 진행했으며, parameter의 수정이 매우 많이 필요한 점을 고려해 현실적으로 real world가 아닌 Pybullet simulation으로 진행
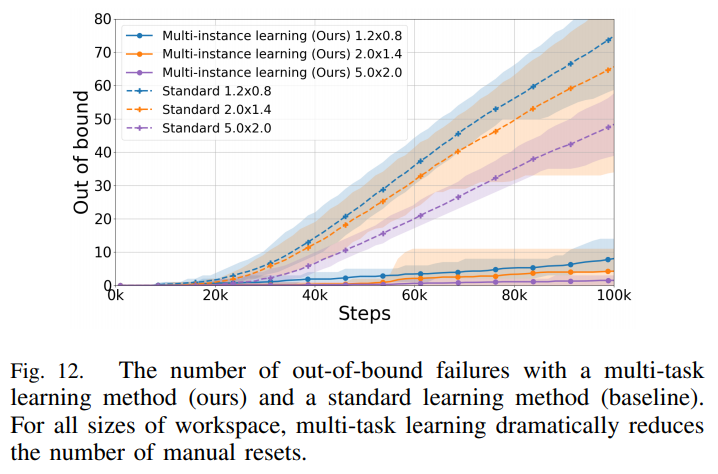
- Multi-task learning을 한 경우와 안한 경우, workspace를 벗어나는 빈도의 차이가 확연히 발생함을 위와 같이 확인함
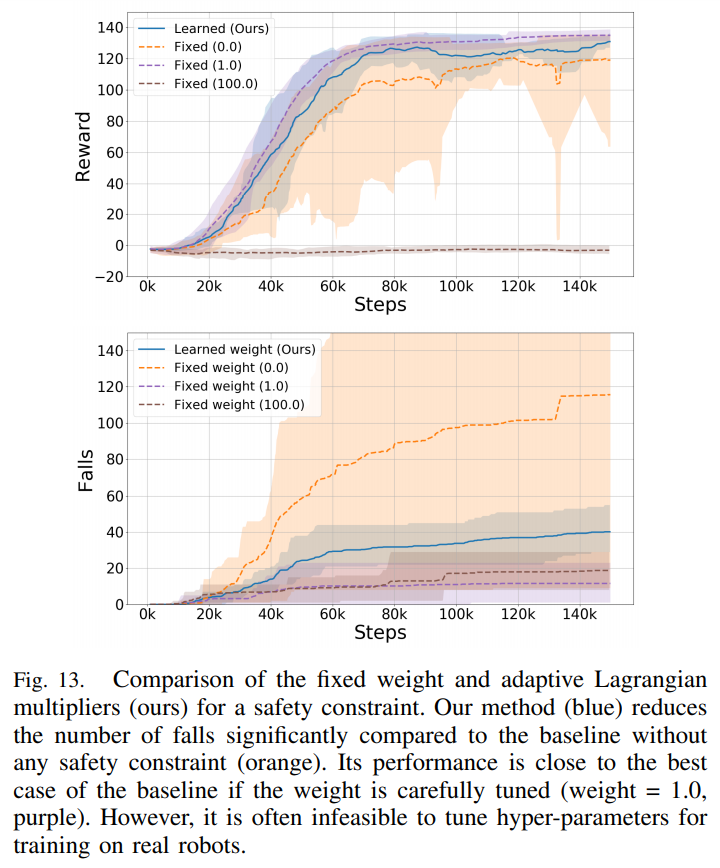
- Safety-constrained term을 사용한 경우 (위 파란색)엔 안한 경우 (위 주황색) 보다 약간의 성능의 향상됨을 확인했으며, 특히 넘어짐이 확연히 줄어드는것을 확인
- 단 fine tuning으로 찾은 최적의 Lagrangian muliplier (위 보라색)보단 낮은 성능 및 잦은 넘어짐을 확인
- 하지만 보통의 경우 성능과 constraint는 상호 반비례 관계를 가지는 경우가 많으며 (위 갈색), 이러한 fine tunning을 real world에서 반복적으로 수행하기란 너무 큰 cost로 인해 사실상 불가능함
- 따라서 본 연구에서 제안된 시스템이 가장 현실적인 자동화된 on-robot training 방법임
- 지금까지의 결과를 종합한 영상
7. CONCLUSION AND FUTURE WORK
- 어쩔 수 없이 넘어진 경우 manually engineered stan-up controller를 사용하였는데, 이는 로봇의 구조가 간단하여 쉽게 설계 가능
- 추후 더 복잡한 로봇에선 locomotion을 학습함과 동시에 recovery policy 또한 동시에 RL로 학습하는 시스템 필요
- Task가 discrete하여 어쩔 수 없이 unshared network architecture를 사용함
- task 자체를 연속적인 목표 선형속도 및 각속도로 parameterize 한다면 shared architecture도 가능할 것으로 예상됨
개인적인 의견
- 사람의 개입이 없는 locomotion 학습이라는 점이 아주 재밌다. RL의 구현은 사실상 Agent보다 사람이 더 많이 움직이며 인내심이 학습되는 과정인데, 이 논문을 통해 한 발짝 더 실제 동물과 같은 학습을 향한 로망에 커지는듯 하다.
- 하나의 shared architecture가 아닌, task 별로 서로 네트워크가 분리되어 완전히 독립적으로 학습되었다.
- 논문에서도 언급됐다시피 task가 discrete하고 task 사이의 공유되는 학습이점이 없는게 shared architecture에서 multi-task learning이 잘 안된 이유인듯 하다.
- 개인적으로는 이는 사용된 로봇(Ghost Minitaur)이 전후회전 움직임을 할때 actuator가 다 다르게 움직이는 구조라서 더욱 그런게 아닐까 싶다.
- 다리를 움직임에 있어 low level에서는 공통적인 feature를 가지는 로봇이라면 어땠을까 궁금하다.
- 물론 사람의 다리 구조도 앞뒤 걷는 task 둘 사이엔 공통으로 사용되는 근육이 많진 않아보인다.
- 대신 좌우 방향으로 회전 하는건 어느정도 직진과 움직임에서 공통점이 있는것 같다.
- 동물과 같은 다리구조의 로봇이라면 이러한 부분을 고려하여 task를 설계한다면 shared architecture의 성능이 잘 나오려나? DeepMind의 Virtual Rodent 논문 (정리 포스팅) 을 보면 서로다른 task를 수행함에 있어 공통된 locomotion feature가 사용되는걸 보면 그럴수도 있겠다 싶다.
- Spot Buddy 프로젝트에서 실험해보면 좋을 부분이 생겼다.


























 은 Target Soft Q-function
은 Target Soft Q-function















