Author : Lili Chen, Kevin Lu, Aravind Rajeswaran, Kimin Lee, Aditya Grover, Michael Laskin, Pieter Abbeel, Aravind Srinivas, Igor Mordatch Paper Link :https://arxiv.org/abs/2106.01345
바로 이전 포스팅인 Trajectory Transformer의 발표 딱 하루전에 먼저 발표된 논문. (기본 개념이 거의 같은 관계로 이 논문은 정리보다 요약으로 대신하며, 많은부분 두 논문을 비교하고자 함)
Trajectory Transformer가 GPT아키텍처로 RL의 transitions들을 sequence modeling을 하여, 이전 trajectory가 input으로 들어갈때 미래의 trajectory $\tau$를 output으로 하는 모델이라면
Decision Transformer는 input은 마찬가지로 trajectory이지만 output은 action $a$를 output으로 하는 모델이라는 차이가 있음.
Trajectory Transformer와 마찬가지로 offline RL에서의 활용을 주로 삼고 있으나, Trajectory Transformer는 transformer 아키텍처를 planning을 위한 model로 쓰기때문에 model-based offline RL인 반면
Decision Transformer는 transformer 아키텍처가 바로 action을 내뱉기 때문에 model-free offline RL.
Decision Transformer가 추구하는 Offline RL의 예시를 그림으로 잘 설명해주는데, 아래와같이 그래프 navigation task에 대한 랜덤한 trajectory 데이터들이 주어져있을 때, 이 경로들을 stitching하여 새로운 최단 경로를 찾아내는것.
여기서 주의해야할 점이 있는데 바로 마지막 generation path에서 노란색 선 옆에 쓰인 return값이 -3이라는것으로, 데이터셋에 있는 return을 그대로 stitching하는 수준이지
이걸 마치 "두 스텝 이전이니 -2로 return을 생성해야 하는군" 처럼 모델이 이해한다던가 하는 데이터셋 이상의 trajectory를 생성하는건 아니라는 것. (DL유투버 Yannic Kilcher가 -2여야 할것같다고 영상에서 잘못 설명하기도)
이렇다 보니, 적절한 action을 생성하기 위해 의도적으로 return을 매번 감소시켜 입력해줘야하는 등 조금은 억지스러운 Transformer 아키텍처의 활용이 필요.
이런 점에선 Beam Search 알고리즘을 써서 Conservation과 Reward Maximization을 동시에 하는 Trajectory Transformer가 더 자연스러운 sequence model의 활용이지 않을까 싶음.
반면 Trajectory Transformer보다 실험을 매우 다양하게 했다는 장점이 있음
Atari를 통해 high-dim과 long-term credit assignment의 성능을 확인
Qbert에선 잘 안됐지만 다른 환경에선 offline RL SOTA인 CQL과 유사
D4RL 벤치마크를 통해 continuous control에서의 성능을 확인
대부분의 데이터셋과 환경에서 CQL보다 나은 성능 확인BC는 데이터셋에서 상위 % 성능의 데이터를 빼서 return의 조절없이 Decision Transformer를 학습한 경우
이 실험은 Trajectory Transformer에서도 했는데다 두 논문에서의 대조군인 CQL성능이 거의 비슷해서 두 논문의 성능을 간접적으로 비교 가능함.
두 논문에서 차이가 가장 나는 부분은 replay buffer의 데이터인 "Medium-Replay(Decision Transformer) = mixed(Trajectory Transformer)"인데, Decision Transformer는 대체로 데이터셋의 최고성능보다 크게 뛰어난 성능을 못내는반면 Trajectory Transformer는 그 이상의 성능을 내는 모습을 보여줌.
실제로 Decision Transformer에서 return을 조절해가며 얼마나 잘 복원되는지를 분석한 결과, 아래와 같이 데이터의 분포를 있는 그대로 잘 학습했으나 데이터셋 최고성능 이상의 return을 조건으로 주었을땐 대부분의 환경에서 데이터셋의 성능을 upper limitation으로 갖는것을 확인함.
또한 과거의 context가 얼마나 중요한지를 확인함.
Trajectory Transformer에선 Humanoid 환경에서 비슷한 실험을 했는데, long-term credit assignment가 상대적으로 안중요한 환경이어서인지 context의 길이가 크게 중요하지 않았음.
Long-term credit assignment가 특히나 중요한 Key-to-Door 환경에서 실험을 해준 부분이 좋았는데, 아래와 같이 과거 context에 따라서 예측되는 reward가 크게 달라지는것을 볼 수 있으며, transformer 아키텍처의 장점인 attension map으로 이를 해석적으로 확인함.
또한 sequence modeling 방식의 접근은 reward의 density가 상대적으로 덜 중요함에 따라 기존 bellman backup 및 policy gradient방식과 대비하여 sparse reward에서 큰 장점을 가지는것을 보여줌.
마지막으로 왜 pessimism이 필요 없는지에 대해선 Trajectory Transformer와 같이 value function을 approximate하는 과정에서 오는 오차가 없기 때문이라는 공통된 의견을 냄
개인적인 생각
위에서 중간중간 언급했다시피, 이렇게 데이터셋의 action을 생성하는 접근으론 stitching은 되겠지만 사실상 imitation learning에서 크게 벗어나지 않는 접근이 되어 데이터셋의 퀄리티에 영향을 받을수 밖에 없는것 같다.
때문에 transformer 아키텍처를 RL에 활용하는데엔, Trajectory Transformer 처럼, pre-trained language모델의 데이터에 대한 뛰어난 representation power에 집중하여 world model로서 잘 활용하고 발전시키는게 더 옳은 방향이 아닐까 싶다.
그럼에도 다양한 환경에서 실험을 하여 모델의 성질에 대해 구체적으로 분석을 한 점이 정말 좋았다.
또한 두 논문이 하루 차이로 나온것과 논문에서 하고자 하는 말이 거의 유사했다는 점이 재밌다.
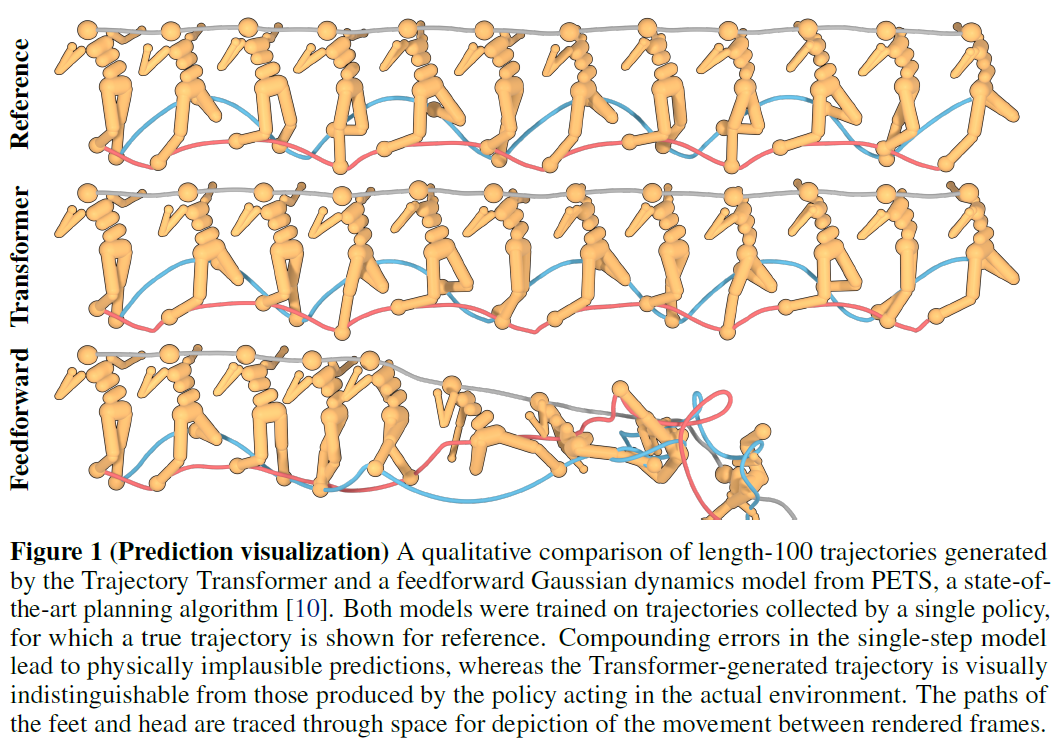
Long-horizon predictions of the Trajectory Transformer compared to those of a feedforward single-step dynamics model.
0. Abstract
기존 RL은 factorized single-step의 Markov property를 중요시 여기는 프레임 워크임
하지만 RL을 "one big sequence modeling"문제로 본다면, NLP에서 이미 상당한 성능을 보인 Transformer와 같은 high-capacity sequence prediction 모델을 그대로 가져다 쓸 수 있음.
이렇게 할 경우 기존의 offline model-free RL에서 필요로 했던 constraint나 uncertainty estimator가 필요 없어져 model-based RL과 같은 장점이 생김.
RL에 대한 이러한 재접근이 다양한 문제(long-horizon dynamics prediction, imitation learning, goal-conditioned RL, offline RL)에서 효과를 보인다는것을 검증함.
1. Introduction
기존 RL은 long-horizon문제를 Markv property에 따라 single-step subproblem으로 나누어 최적화하는것을 기본 원리로 하며 이는 model-free RL의 Q-learning, model-based RL의 single-step prediction으로 다루어짐.
Actor-critic, model-based, offline RL은 서로 다른 분포를 학습하지만 state, action, reward를 단순한 stream of data로 본다면 모두 single sequence model로 다룰 수 있으며, high-capacity를 가진 sequence model 아키텍처를 그대로 적용하여 GPT-3와 같은 scalability의 장점을 얻을 수 있을것.
"RL을 sequence generation 문제로 본다면 기존의 unsupervised sequence model을 적용하여 새로운 RL알고리즘을 만들 수 있을까?" 에대한 분석을 하고자 Transformer 아키텍처를 사용하여 state, action, reward의 sequence를 다루고 planning 알고리즘으론 beam search를 사용하려 함.
이러한 접근을 Trajectory Transformer라고 이름 짓고, offline RL, model-baed imitation learning에 적용해보고자함
2. Recent Work
LSTM, seq2seq, 그리고 Transformer 아키텍처까지 빠르게 발전한 sequence 모델을 RL에 적용한 경우가 다양하나 모두 RL의 업데이트 알고리즘은 그대로 사용한 반면, 여기선 가능한 많은 RL파이프라인(특히 알고리즘)을 sequence model의 representation capacity로 대체하고자 함.
RL에서는 predictive 모델 (for model-based RL) / behaviror policy (for imitation learning) / behavior constraint (for offline RL) 등의 다양한 분포들을 학습하는 접근이 있으나, single high-capacity sequence model로 하여금 state / action / reward sequence들을 interchangeable하게 다루는 joint distribution을 학습하도록 하면 이러한 분포들의 역할을 모두 수행 할 수 있을것.
Trajectory Transformer는 학습된 모델로 planning을 하는 model-based RL과 가장 유사하지만 ensemble이 필요없으며 특히나 offline setting에서 conservatism이나 pessimism 구조가 명시적으론 필요없다는 점이 다른데, 이는 state와 action을 jointly모델링 하는데서 in-distribution action을 생성하도록 함축적인 bias가 들어가기 때문.
이 논문이 발표되기 하루전에 피터아빌 팀에서 Decision Transformer를 발표했으며, RL의 알고리즘 없이도 high-capacity sequence model만으로 RL문제를 다루고 그 가능성을 입증한다는 점에서 본 논문과 본질적으로 추구하는 컨셉이 같음.
3. Reinforcement Learning and Control as Sequence Modeling
본 논문에서 제안하는 접근을 Trajectory Transformer라고 새로 명명 했으나 구현 측면에선 NLP에서의 sequence 및 탐색 모델과 거의 동일하므로, 아키텍처 부분보다 trajectory 데이터를 어떻게 다루었는지에 더 집중하고자 함.
3.1 Trajectory Transformers
제안하는 접근방식의 핵심은 trajectory를 Transformer 아키텍처를 위한 비정형화된 sequence로 다루는것으로, trajectory $\tau$는 아래와 같이 $N$차원 state, $M$차원 action, 스칼라 reward로 구성됨
같은 방법으로 action 토큰 $\bar{a}_{t}^{j}$도 차원별로 offset $V\times \left ( N + j \right )$을 주어 tonkenize 하며 discretized reward 토큰 $\bar{a}_{t}^{j}$역시 offset $V\times \left ( N + M \right )$로 tokenize함.
Gaussian transition과 같은 단순화 가정 없이 이렇게 개별로 tokenize함으로서 trajectory에대한 분포를 더욱 expressive하게 만듬
Trajectory Transformer는 GPT 아키텍처의 Transformer decoder를 차용했으나, 상대적으로 작은 크기의 4개 레이어와 6개 self-attention head로 구성됨
Trajectory Transformer의 파라메터를 $\theta$라고 할때 학습 objective는 다음과 같고 이때 정답을 input으로 주는 teacher-forcing 방법을 사용함
$\bar{\tau}_{<t}$는 시간 t까지의 tokenized trajectory이나 self-attention의 quadratic complexity때문에 512개의 토큰으로 제한을 두기로 하고 총 $\frac{512}{N+M+1}$의 horizon을 사용함.
3.2 Transformer Trajectory Optimization
제안한 Trajectory Transformer를 control문제에 어떻게 적용하지 다뤄보고자 하며 기본 NLP알고리즘에서 추가되는 변형이 많아지는 순서로 다음 세가지 세팅이 있음 1. Imitation learning 2. Goal-conditioned RL 3. Offline RL
이와같은 Trajectory Transformer의 control 문제에서의 변형들을 아울러 Transformer Trajectory Optimization (TTO)라고 정의.
3.2.1 Imitation learning
Imitation learning과 같이 task의 목적이 학습데이터의 distribution을 복원하는 경우는 sequence modeling의 기존 목적과 일치하므로, 변형없이 beam search 알고리즘과 같으 탐색알고리즘을 적용하며 사용가능함
그 결과 현재의 state $s_{t}$로 시작하는 tokenized trajectory $\bar{\tau}$를 생성하며, 이때의 action $\bar{a}_{t}$ 는 reference 행동을 모방하는것으로서 model-based behavior cloning 역할을 함
3.2.2 Goal conditioned RL
Transformer 아키텍처는 "causal" attention mask기반의 이전 토큰에만 의존한 다음 토큰 예측을 그 특징으로 하며, 이는 물리적으로 미래가 과거에 영향을 미치지 않는 "physical causality"와도 일맥상통함.
하지만 self-attention 아키텍처에 기반하고 있기 때문에 과거 뿐만아니라 미래 역시 다룰 수 있어, 아래와 같이 마지막 state가 주어졌을때의 conditional probability역시 decode 할수 있음.
이때 마지막 $\bar{s}_{T-1}$는 일어나길 바라는 상태로서 지속적으로 입력 sequence에 줄 경우, trajectory transformer를 goal-reaching 방식으로 사용가능함.
실제 구현에선 미래의 goal state token을 sequence의 제일 앞에 항상 붙이는 방법으로, 기존 Transformer의 causal attention mask를 그대로 사용가능함.
이러한 접근은 기존에 supervised learning을 goal-conditioned policy에 적용하던 접근 혹은 relabeling 접근과 유사함.
3.2.3 Offline RL
Beam search (BS) 는 sequence planning의 한 방법으로 가장 높은 log-probability를 가지는 sequence들을 선택하는 알고리즘
BS 알고리즘에서 각 토큰의 log-probability대신 reward를 사용하면 reward-maximizing planning 알고리즘으로 사용가능
하지만 single-step reward-maxing으론 근시적인 planning만 가능하므로, 대신 아래의 reward-to-go (discounted return) 값을 전처리하여 학습 trajectory의 각 transition step에 reward 토큰 다음에 오는 새로운 토큰으로 추가
$R_{t}=\sum_{t'=t}^{T-1}\gamma^{t'-t}r_{t'}$
이로서 planning과정에서 reward-to-go의 예측값, 즉 value를 추정하지만 BS알고리즘에서만 휴리스틱 가이드로서 사용하므로 offline setting에서의 value estimation 문제와 달리 정확할 필요가 없어진다는 장점이 생김.
구체적으론, transition을 하나의 단어로 취급하여 likelihood-maximzing BS알고리즘을 사용하여 가장 확률이 높은 transition을 먼저 샘플링 한 뒤, 이 중에서 reward와 value가 높은 transition을 필터링함으로써 passimism없이도 기존의 offline RL과 같이 conservative한 planning효과를 내는것이 가능해짐.
4. Experiments
실험 파트에서는 다음 두가지에 집중하여 검증을 진행함 1. long-horizon 예측에 대한 기존 single-step 예측 모델 대비 Trajectory Transformer 모델의 정밀성 2. Offline RL / imitation learning / goal-reaching 세 가지 문제에서 BS알고리즘을 sequence 모델링 툴로 사용한 것의 제어 알고리즘으로서의 효용성
4.1 Model Analysis
4.1.1 Trajectory prediction
humanoid policyd 데이터셋을 reference로 하여 학습된 모델로 100 step을 예측한 결과 비교
Single-step만 예측하는 Markovian 조건 하에서 ensemble dynamics 모델을 학습하고 policy의 action에 따른 transition을 생성하는 probabilistic ensembles with trajectory sampling (PETS)알고리즘의 경우 feedforward로 few dozon step이 넘어가면 오차가 매우 커짐 (Figure 1의 세번째 줄)
반면 Trajectory Transformer는 reference (첫번째 줄) 와 차이없는 모습을 100 step 넘게 안정적으로 예측하는것을 보여주었으며 (두번째 줄) 이는 model-based RL방식에서 SOTA임.
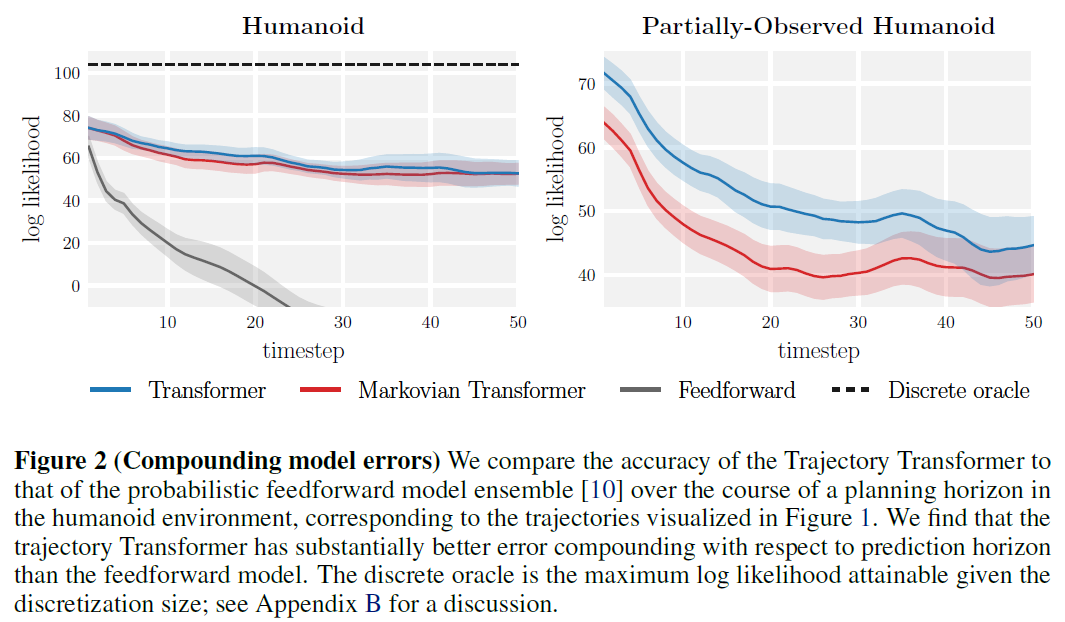
4.1.2 Error accumulation
위 실험에서 보여준 누적 오차를 정량적으로 평가하기위해 두 모델에서 각각 1000 trajectory를 샘플링하여 per-timestep state marginal을 구하고 reference state의 likeihood를 비교한 결과, Trajectory Transformer가 월등한 대비성능을 보여줌
또한 Trajectory Tranformer로 하여금 과거의 1개 step만 참고하도록 변경한 Markovian Transformer의 경우도 비슷한 예측 성능을 보여줌으로서, Transformer 아키텍처 그 자체와 autoregressive state discretization으로 인해 향상된 expressivity가 long-horizon accuracy에 큰 역할을 한다는것을 확인.
state 차원을 랜덤하게 절반 masking한 partially-observed 케이스에서 original Trajectory Transformer가 abblation대비 높은 성능을 보여주어 long-horizon conditioning의 accuracy에대한 역할을 확인할 수 있음.
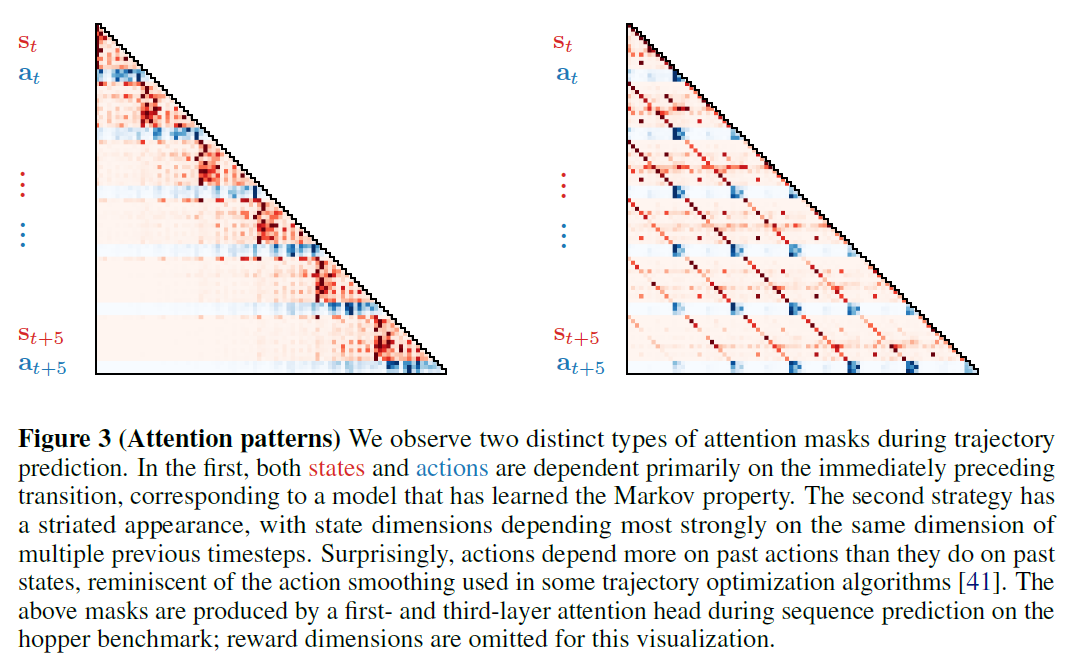
4.1.3 Attention patterns
Trajectory Transformer는 두가지 attention pattern을 보여줌 1. 직전 transition에 집중하는것으로 Markovian strategy를 학습한 패턴 2. State는 동일한 dimension에 집중하며 action은 과거 state보다 과거 action에 집중하는 패턴
두번째 패턴의 경우 action이 과거 state에만 의존하는 behavior cloning과 반대되는 결과이며, 몇 trajectory optimization알고리즘들에서 쓰인 action filtering 기법과 닮음.
4.2 Reinforcement Learning and Control
4.2.1 Offline RL
D4RL offline RL 벤치마크에서 reward-maximizing TTO알고리즘을 검증하며 이를 다음 4가지 접근방법과 비교함. 1. Conservative Q-learning (CQL; model-free SOTA) 2. Model-based offline policy optimization (MOPO; model-based SOTA) 3. Model-based offline planning (MBOP; single-step dynamics 모델 사용) 4. Behavior cloning (BC)
그리고 3가지 MuJoco 환경에서 다음 3가지 데이터셋으로 학습을 진행함. 1. medium: 중간정도의 점수를 가지는 policy로 만들어낸 데이터 2. med-expert: medium 데이터와 최고점수를 가지는 policy로 만들어낸 데이터의 혼합 3. mixed: medium을 학습시키기 위해 사용된 replay buffer 데이터
실험 결과 모든 데이터넷에서 대체로 기존 알고리즘들과 동등하거나 보다 뛰어난성능을 보여주었음.
단, HalfCheetah의 med-expert데이터에서는 expert데이터의 성능이 상당히 좋아지는 바람에 discretization이 세세하게 되지 못하여 성능이 낮은것으로 추정.
4.2.2 Imitation and goal-reaching
Behavior cloning 성능을 확인하고자 likelihood-maximizing TTO 알고리즘을 hopper와 walker2d환경에 적용한 결과, 각각 behavior policy대비 104%와 109%의 return을 보여줌.
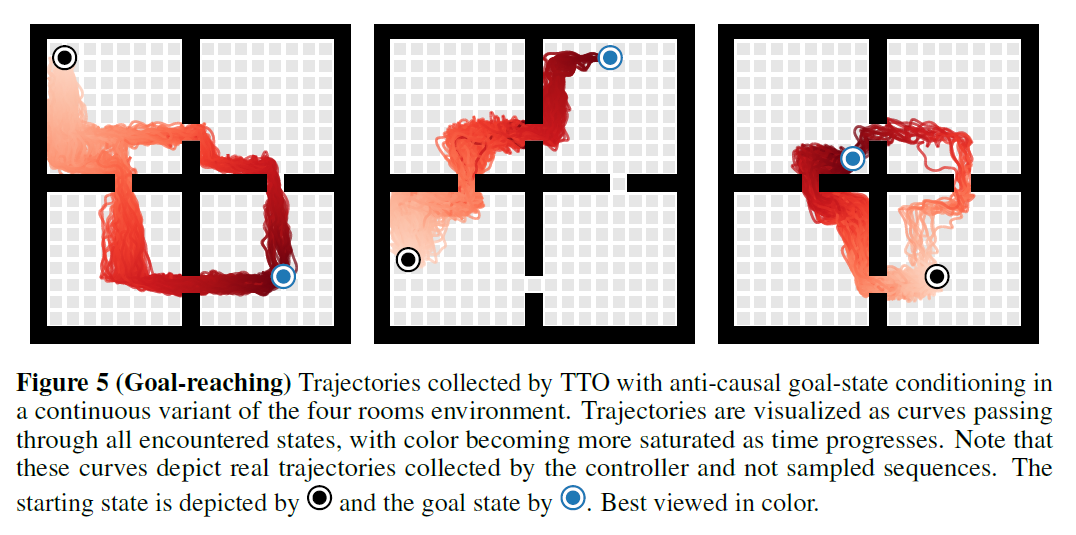
Goal-reaching 성능을 확인하고자 likelihood-maximizing TTO 알고리즘을 goal-stated conditioned sequence를 주어 four rooms환경에 적용한 결과, reward shaping이나 어떤 reward 정보 없이 goal relabeling만으로도 plannindg이 잘 되는것을 확인함.
5. Discussion
Large-scale language 모델에서 사용되는 Transformer를 기존 강화학습의 분리된 구조 대신 하나의 통합된 sequence 모델로서 beam search알고리즘과 함께 사용한 결과 imitation learning, goal-reaching, offline RL에서 효용성을 보여줌.
구조가 간편하고 유연해지는 대신 기존의 single-step 예측모델에 비하면 느리다는 단점이 있으나, 현재의 Transformer의 경량화 흐름을 비추어보면 문제없을것으로 예상.
Continuous space 데이터의 경우 disctretize해주어 사용하기때문에 accuracy가 떨어진다는 단점이 있지만 이는 다양한 discretization방법으로 어느정도 해결가능할것으로 예상.
Transformer를 사용하여 RL문제를 SL문제로 다루는것이 처음은 아니지만, 이러한 접근이 Markov property를 학습하고 offline RL에서 기존 방법과 비교할만한 결과를 보여준다는것을 입증한것에서 의의가 있음.
개인적인 의견
기존의 Model-based RL에서도 말만 RL이지 policy부분은 전혀 RL이 아닌 경우가 있어서 사실상 Model-based RL 접근으로 볼 수 있을것 같다. 특히 Model-based RL에서 가장 중요한게 model부분인데 기존의 single-step model은 markov property 조건때문에 real-world에서 적용이 어려워보이는 느낌이 강했었다. 이러한 문제를 Transformer를 사용하면 쉽게 해결할 수 있어져 decision making AI가 real-world로 나아갈수 있는 방향이 크게 늘어날것 같은 생각이 든다.
Model-based RL의 대표적인 model인 world-model은 RNN 기반인데, NLP에서 Transformer가 RNN을 대체한 만큼 world-model에서도 Transformer가 할 수 있는게 많지 않을까 싶다.
의료 도메인에서 특히나 치료/추천형 AI 연구를 하는 입장에서 AI의 판단근거를 항상 고려해야 하기에, 개인적으로 Transformer아키텍쳐는 attention map이 늘 매력적으로 다가왔다. 물론 attention의 XAI 측면은 자연어 생성 분야에서 여전히 말이 많긴하지만, Decision making으로 나아가고자 하는 이 논문이 추구하는 방향성에서 충분히 의미있는 정보가 될것은 분명한듯하다.
Goal-conditioned reaching역시 재밌는 부분이다. policy의 경우 Goal-conditional policy, Contexual policy 등 추가적인 정보를 policy에 주어 더 복잡한 task를 푸는 연구가 많다. 이러한 task들을 conditional-sequence로 새롭게 접근하는 방법들이 많이 나올 수 있을것 같다.
Author : Siqi Liu, Guy Lever, Zhe Wang, Josh Merel, S. M. Ali Eslami, Daniel Hennes, Wojciech M. Czarnecki, Yuval Tassa, Shayegan Omidshafiei, Abbas Abdolmaleki, Noah Y. Siegel, Leonard Hasenclever, Luke Marris, Saran Tunyasuvunakool, H. Francis Song, Markus Wulfmeier, Paul Muller, Tuomas Haarnoja, Brendan D. Tracey, Karl Tuyls, Thore Graepel, Nicolas Heess Paper Link : https://arxiv.org/abs/2105.12196v1
Author : Tuomas Haarnoja*, Aurick Zhou*, Kristian Hartikainen*, George Turker, Sehoon Ha, Jie Tan, Vikash Kumar, Henry Zhu, Abhishek Gupta, Piter Abbeel, Sergey Levine Paper Link :https://arxiv.org/abs/1812.05905
0. Abstract
Model free deep RL은 샘플링 효율이 매우 낮고, 수렴이 불안정함.
이를 극복하고자 maximum-entropy (MaxEnt) RL 프레임워크에 기반한 Off-poliy actor-critic 알고리즘을 제안함
1. Introduction
Real-world 에서의 model free RL의 단점
샘플링 비효율
Hyperparameter에 민감
On-policy는 샘플을 업데이트 할때마다 버리므로 샘플 효율이 높은 off-policy가 좋으나,
Q-learning기반 알고리즘의 단점 존재
고차원 NN 썼을때 불안정하며 수렴이 잘 안됨
Continuous space에서 악화
"어떻게 하면 Continuous space에서도 샘플 효율적이고 안정하게 만들까?"
MaxEnt를 RL에 적용 (MaxEnt RL) 하면 탐색과 강건성을 향상시키나 여전히 on/off policy문제 존재
Off-policy이면서도 stochastic하고 MaxEnt RL프레임을 사용하는 알고리즘 필요
저자의 이전 논문 Soft Q-learning (https://arxiv.org/abs/1702.08165) 에선 MaxEnt RL + Q-function의 soft-Q function을 도입하고 이를 따르는 (아래 그림의 오른쪽), $expQ$를 energy function으로 하여 energy based model 분포를 policy로 사용하는 알고리즘을 제안
KL Divergence를 사용하여 exp(Q)를 parameterized된 policy set에 information projection을 하여 새로운 policy 도출
일반적으로 intractable한 partition function Z는 추후 설명할 SAC의 목적함수에서 KL Divergence를 최소화 하는 gradient descent 과정에서 무시됨
이때, 행동이 유한하다는 가정 하에, 위 최적화를 만족하는 새로운 policy는 이전 policy에 비해 항상 높은 기대보상을 가짐
Soft policy iteration: 위 soft policy evaluation과 soft policy improvement의 과정을 parameterized policy set 내의 임의의 policy에 대해 번갈아 진행하면 policy set 내의 optimal MaxEnt policy로 수렴
위 Lemma와 Theorem은 tabular space에서 증명됨
continuous space에서 적용하려면 NN과 같은 function approximator가 필요하지만 수렴에 너무 큰 계산량을 요구하는 한계 존재
따라서 같은 프레임워크에서, Soft Q-function(evaluation)과 policy(improvement)를 NN으로 근사하고 두 network를 Stochastic gradient descent 하는것으로 대체
첫번째 SAC 논문(https://arxiv.org/abs/1801.01290) 에서는 Soft Value function, Soft Q-function, policy 셋을 모두 parameterize했으나, 이 두번째 SAC 논문에서는 Soft Q-function와 policy만 근사
Replay buffer (~D)에 저장된 (state, action) pair 데이터를 가져와 Soft Q-function와 Target soft Q-function 을 계산하고, 이 차이(Bellman residual)를 최소화 하는것이 objective function
이때 은 Target Soft Q-function
위 objective의 Soft value function V 는 Soft Q-function으로 풀어 쓸수 있으며, 최적화로 Stochastic gradient descent(SGD)를 사용하기 위해 objective function의 gradient를 구하면 다음과 같음
SGD를 사용하므로 Expectation은 제거 가능하다
여기서 S,A,R,S'까지는 Replay buffer(D)에서 추출한 값이며, Soft Target에서의 A'는 현재의 policy에 따름
policy의 objective function은 위 tabular policy improvement단계에서의 KL divergence 에 Replay buffer (D)에서 추출한 State 와 현재 policy를 사용
알고리즘의 실제 적용에선 TD3에서 value기반 알고리즘들의 policy improvement 단계의 positive bias문제를 해결하기 위해 사용한 것과 같은 맥락으로, 2개의 soft Q-function을 독립적으로 학습하여 더 작은 Q를 사용하며 이는 복잡한 task에서의 성능과 학습속도를 향상시킴
[22.6.25 수정] 최근 Google Deepmind에서 Mujoco를 인수하여 무료로 배포하였고 몇달이 지난 지금 기대했던대로 python 바인딩을 해주었다. 이에 맞게 포스팅을 업데이트하였다. (이전 설치방법들은 포스팅의 아래쪽에 그대로 있음)
현재 집필중인 meta-learning 도서의 코드 마무리를 위해, 윈도우, 리눅스, 맥 모두에서 알고리즘들이 잘 동작하는지 테스트 하던 중, 몇달 사이 딥마인드에서 mujoco의 python binding을 해두었단 사실을 알게되었다.
항상 mujoco-py 때문에 번거로웠는데 이젠 라이센스조차 필요없이 심플하게 사용가능한 python 패키지가 되었다.
1. OpenAI gym & MuJoCo 설치
pip install gym==0.24.1
pip install mujoco==2.2.0
(윈도우)
윈도우는 다음 패키지를 추가로 설치해준다.
pip install imageio>=2.1.2
2. mujoco 패키지 설치 확인
프롬프트에서 python을 입력해 python을 실행 한 후, 아래 코드를 실행시킨다.
import random
from gym.envs.mujoco.half_cheetah_v4 import HalfCheetahEnv
env = HalfCheetahEnv()
for _ in range(100):
env.render()
action = [random.randint(0,1) for _ in range(env.action_space.shape[0])]
_, _, _, _ = env.step(action)
env.close()
잘 설치가 되었으면, 랜덤하게 생성된 action에 의해 100step 동안 치타가 꿈틀거리는것을 볼 수 있다.
아래는 예전 포스팅
2년쯤 전에 어떻게 설치해서 사용하던 MuJoCo인데 최근 새로나온 Meta RL 알고리즘을 구현 해보고자 실행하니 사용기한이 만료됐다고 하여 새로 설치를 해야했다. 작년엔 연구실에서 만든 가상환자 gym 환경을 써온터라 잊고 있었는데 mujoco student licence는 1년마다 갱신을 해줘야 한다. 사실 DQN A2C 가 나올 시기만 해도 cartpole이나 간단한 Atari 환경에서 알고리즘 테스트가 주로 이루어졌다면, 불과 1~2년 사이에 RL이 크게 발전해서 이젠 복잡한 3D 환경에서의 알고리즘 검증이 필수가 되고 있다.
[21.12.02 수정] 최근 Google Deepmind에서 Mujoco를 인수하여 무료로 배포하였고 이에 맞게 포스팅을 업데이트하였다. (이전 설치방법은 포스팅의 아래쪽에 그대로 있음)
이를 가지고 다시 위 링크에 접속해 MuJoCo Personal License:1 year의 빨간색 창에 발급된 account number와 computer id를 입력하며 register computer를 클릭해 본인의 컴퓨터를 등록한다. computer id는 빨간색 창에서 win64 를 클릭해 프로그램을 다운받아 실행하면 알 수 있다.
2.0.0의 최신 버전도 있지만, 아쉽게도 MuJoCo는 더이상 윈도우를 지원 안해 1.5.0 를 받아야 한다. (사용엔 큰 문제 없다.)
3. MuJoCo 엔진 설치
받을 파일의 압축을 풀면 mjpro150이란 폴더가 생긴다. 이 폴더를 C:\Users\[본인계정] 에 ".mujoco" 란 새폴더를 만들고 그 안에다 옮긴다. 또한 메일로 발급받은 mjkey.txt 를 C:\Users\[본인계정]\.mujoco\mjpro150\bin 안에다 옮긴다.



































 은 Target Soft Q-function
은 Target Soft Q-function















