Author : Tao Tu, Anil Palepu, Mike Schaekermann, Khaled Saab, Jan Freyberg, Ryutaro Tanno, Amy Wang, Brenna Li, Mohamed Amin, Nenad Tomasev, Shekoofeh Azizi, Karan Singhal, Yong Cheng, Le Hou, Albert Webson, Kavita Kulkarni, S Sara Mahdavi, Christopher Semturs, Juraj Gottweis, Joelle Barral, Katherine Chou, Greg S Corrado, Yossi Matias, Alan Karthikesalingam, Vivek Natarajan Paper Link:https://arxiv.org/abs/2401.05654
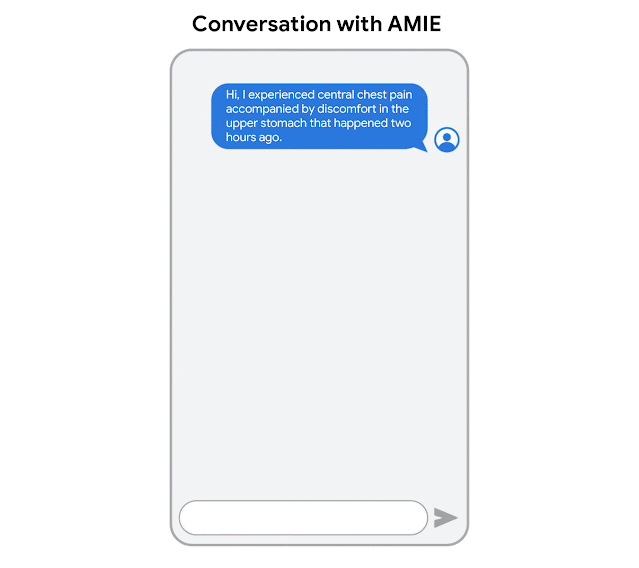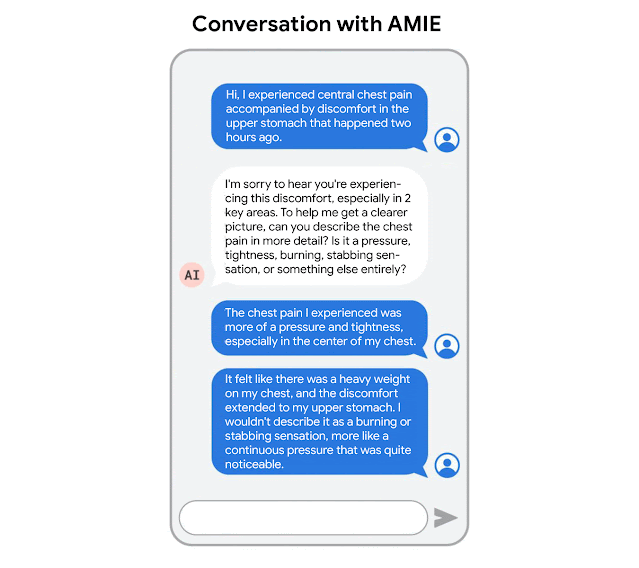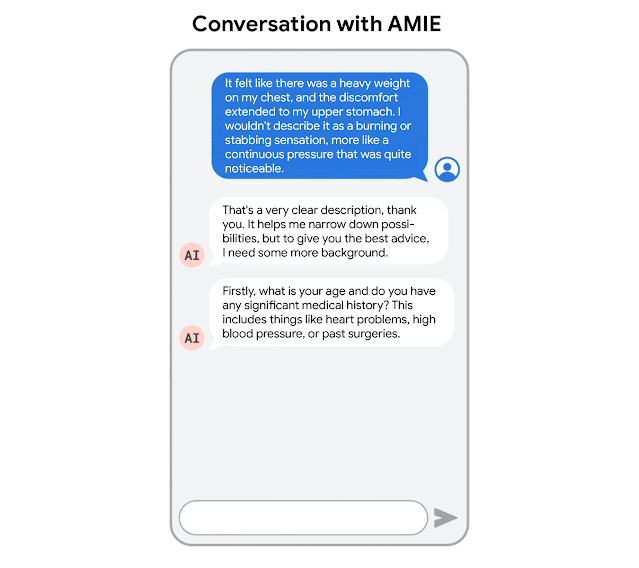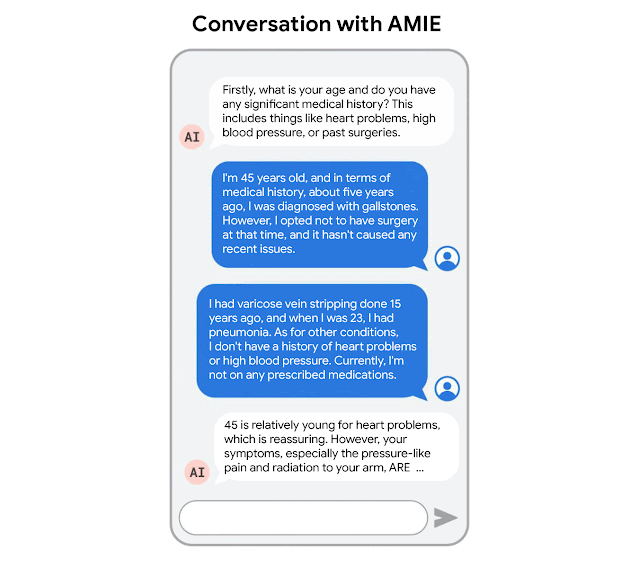
AMIE was optimized for diagnostic conversations, asking questions that help to reduce its uncertainty and improve diagnostic accuracy, while also balancing this with other requirements of effective clinical communication, such as empathy, fostering a relationship, and providing information clearly.
AMIE is a research AI system based on LLMs for diagnostic reasoning and dialogue.
AMIE uses a novel self-play based simulated dialogue learning environment to improve the quality of diagnostic dialogue across a multitude of disease conditions, specialities and patient contexts.
Author: Karan Singhal, Tao Tu, Juraj Gottweis, Rory Sayres, Ellery Wulczyn, Le Hou, Kevin Clark, Stephen Pfohl, Heather Cole-Lewis, Darlene Neal, Mike Schaekermann, Amy Wang, Mohamed Amin, Sami Lachgar, Philip Mansfield, Sushant Prakash, Bradley Green, Ewa Dominowska, Blaise Aguera y Arcas, Nenad Tomasev, Yun Liu, Renee Wong, Christopher Semturs, S. Sara Mahdavi, Joelle Barral, Dale Webster, Greg S. Corrado, Yossi Matias, Shekoofeh Azizi, Alan Karthikesalingam, Vivek Natarajan
# Contribution - **Med-PaLM:** PaLM을 instruction tuning한 Flan-PaLM만으로도 의료QA테스크에서 SOTA (eg., 미국의사시험에서 67.9%)를 달성했으나, 사람에 의한 정량적 평가에서 의료진의 응답과의 차이를 좁히고자 65개의 의료QA데이터를 만들고 여기에 instruction prompt tuing을 수행한 Med-PaLM으로 Flan-PaLM보다 안전하면서도 의료적으로 높은 평가달성 (미국의사시험 성능은 오히려 67.2%로 미미하게 하락) - Contributions - base model을 PaLM2로 바꾸고 도메인 특화 finetuning을 수행한 Med-PaLM2 개발 - LLM의 reasoning을 향상시킬 새로운 prompting전략으로 ensemble refinement 도입 - 다지선택 정량평가 데이터셋에서 SOTA - 일반인에 의한 긴 질의응답 데이터셋에서 의료진의 답변과 비교하여 뉘앙스 평가 9개 기준 중 8개에서 더 선호됨 (fig1) - 안전성과 기존평가의 한계점을 보완하고자 2가지 적대적 질문 데이터셋을 추가하고 Med-PaLM2의 응답이 Med-PaLM의 응답보다 높에 평가되는것을 확인
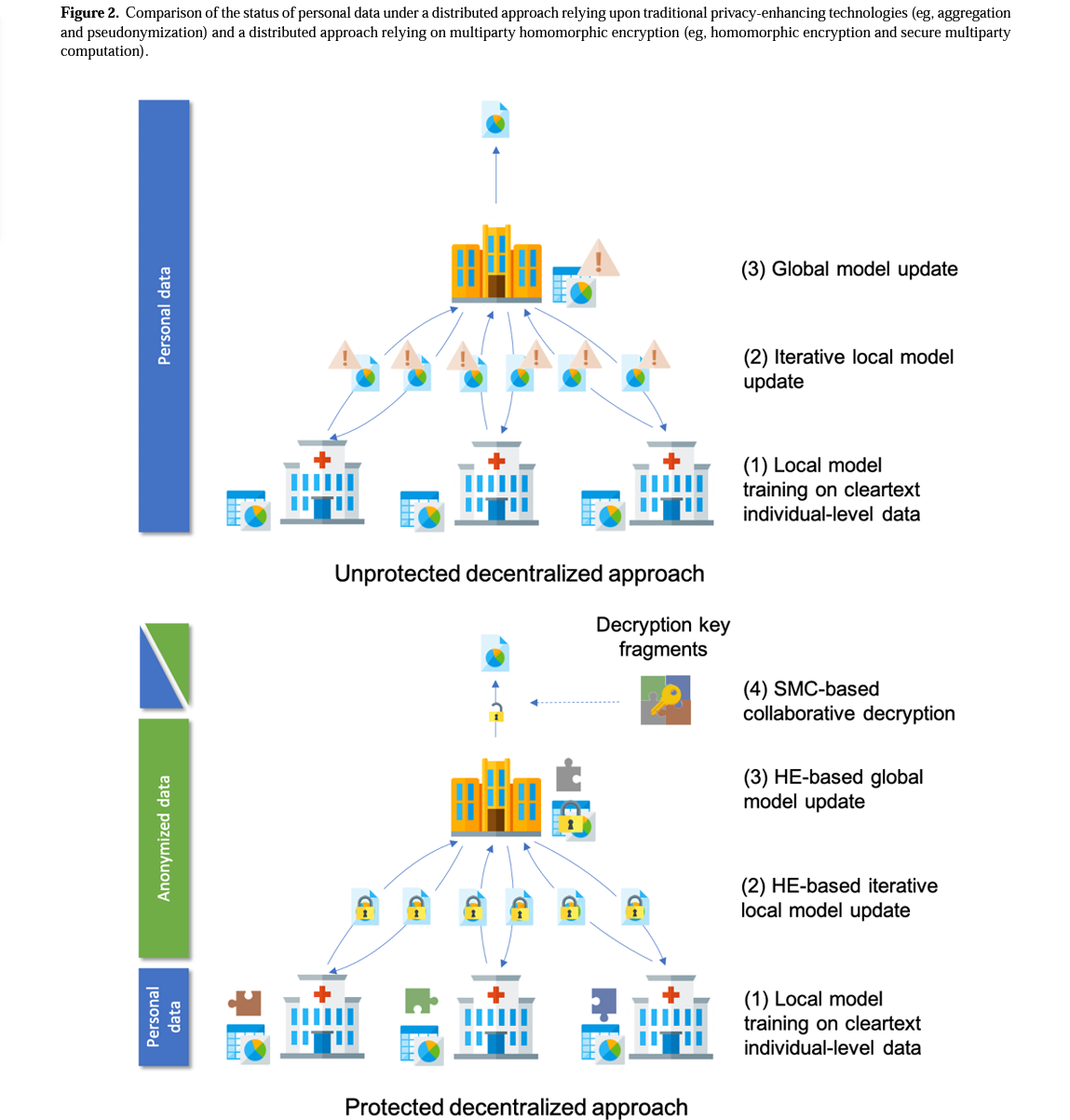
# Method ## Datasets - Med-PaLM과 동일한(+추가 샘플된) 데이터셋 + 2개의 adversarial 데이터셋 - Adversarial questions - 기존 데이터셋에서 평가가 어려웠던 편향성을 다루고자 새로운 데이터셋 추가 - General adversarial dataset (58): 건강 형평성, 구조적 사회적 요인이 건강에 미치는 영향, 신장기능에 대한 인종적 편향성을 평가하는 내용 포함 - Health equity adversarial dataset (182): 의료 접근성과 사회적 환경적 요인에 대한 의료 형평성에 대한 내용 포함
## Modeling - Base LLM: PaLM2 - Instruction finetuning: MultiMedQA의 training data로 Google의 Flan-PaLM 논문 [Chung et al.](https://arxiv.org/abs/2210.11416) 에 나온 프로토콜에 따라 PaLM2모델을 finetuning하고 이를 Med-PaLM2라 지칭
## Multiple-choice evaluation - 다지선택 데이터셋에 대해서 Med-PaLM의 prompting 방식에 ensemble refinement를 추가한 4개의 pormpting방식을 Med-PaLM2에 적용. 1. Few-shot prompting 2. Chain-of-thought 3. Self-consistency 4. Ensemble refinement - Self-consistency처럼 다수결로 의견을 뽑는게 아니라, 1.여러 응답을 생성한 후 2.생성된 응답들을 모두 고려하여 정제된 설명과 응답을 재생성하도록 하는 방법 - 성능 향상을 위해 최종 응답을 도출할때까지 두번째 단계를 다시 여러번 반복 - 다지선택 뿐만 아니라 긴 응답에도 적용가능 - 여기선 다지선택 질문에 한정하여 11개의 응답 생성 후, 이를 모두 입력으로 넣어 33개의 응답을 재생성한 한 다음 이 중에서 다수 응답을 선택 (fig2)
## Overlap analysis - Base LLM의 학습에 쓰이는 데이터에 평가 데이터가 들어가진 않는지 분석
## Long-form evaluation - 응답의 생성 및 평가 방식은 전체적으로 Med-PaLM과 유사 - Med-PaLM, Med-PaLM2, 의료진에 의한 응답들에 대해 1:1 비교 랭킹또한 시행
# Results ## Multiple-choice evaluation - 다지선다 데이터셋의 경우 GPT-4-base와 aligned-GPT-4에 대한 응답도 함께 비교 - Med-PaLM2의 경우 Flan-PaLM대비 크게 상승한 성능을 보여주었으나, GPT-4-base와 비교하여 조금 더 높거나 낮은 항목들을 비슷하게 보여줌 (Table4) - 단 aligned-GPT-4의 경우 GPT-4-base 대비 성능이 크게 떨어진 반면, Med-PaLM2는 의료 도메인에 필요한 조건들을 만족하면서도 GPT-4-base와 성능이 비슷 - Few-shot, COT, SC과 비교했을때, 대체로 ER이 높은 성능을 보여주었으나 모두 그런건 아님 (Table5) - 오버랩 분석에서는 데이터셋에 따라 0.9 ~ 48% (기준을 낮출 시, 11.15 ~ 56%)의 오버랩이 있었으나, 오버랩된 질문과 아닌 질문 사이의 응답 성능에는 차이가 크게 없었음 (Table6)
## Long-form evaluation - 동시에 평가를 한 경우엔 Med-PaLM, Med-PaLM2, 의료진의 응답에 대한 차이를 뚜렷하게 관측하기 어려워 (Fig3) 1:1 평가 시행 - 1:1 평가에서는 9개중 8개의 평가항목에서 Med-PaLM2의 응답이 의료진의 응답보다 높게 평가됨(Fig1) - 하지만 부정확하거나 연관없는 정보의 포함 여부에 대해서는 의료진의 응답이나 Med-PaLM의 응답보다도 근소하지만 낮게 평가됨 - 일반인의 경우도 Med-PaLM2의 응답을 의료진의 응답보다 더 도움되거나 질문에 맞다고 평가(Fig4) - 하지만 Med-PaLM2의 응답이 의료진의 응답보다 길이가 두배 이상 긴데서 오는 평가항목 간의 tradeoff를 고려할 필요 있음(TableA9)
# Discussion - 가능한 모든 경우를 나열하여 길게만 하는 응답이 좋은건 아니므로, 적절한 정보를 다시 요구하는 multi-turn 대화나 active information acquistion이 고려될 필요 - 1:1 평가에서 의료진의 응답보다 높게 순위를 받은건 LLM이 의료진 수준의 성능으로 나아감을 뜻하는것과 동시에 더 나은 평가방법이 중요함을 의미
# Limiations - 의료진에 질문에 대한 응답을 요청할때 청자가 누가 될지나 좋고 나쁜 응답의 예시를 주지 않았으며 하나의 응답만 하도록 한 등, 평가를 더 개선하기 위해선 더욱 명확한 임상 시나리오를 정할필요가 있음
Author :(Microsoft) Cheng Zhang, Stefan Bauer, Paul Bennett, Jiangfeng Gao, Wenbo Gong, Agrin Hilmkil, Joel Jennings, Chao Ma, Tom Minka, Nick Pawlowski, James Vaughan Paper Link:https://arxiv.org/abs/2304.05524
Author : Hamed Nilforoshan, Michael Moor, Yusuf Roohani, Yining Chen, Anja Šurina, Michihiro Yasunaga, Sara Oblak, Jure Leskovec Paper Link:https://arxiv.org/abs/2301.12292
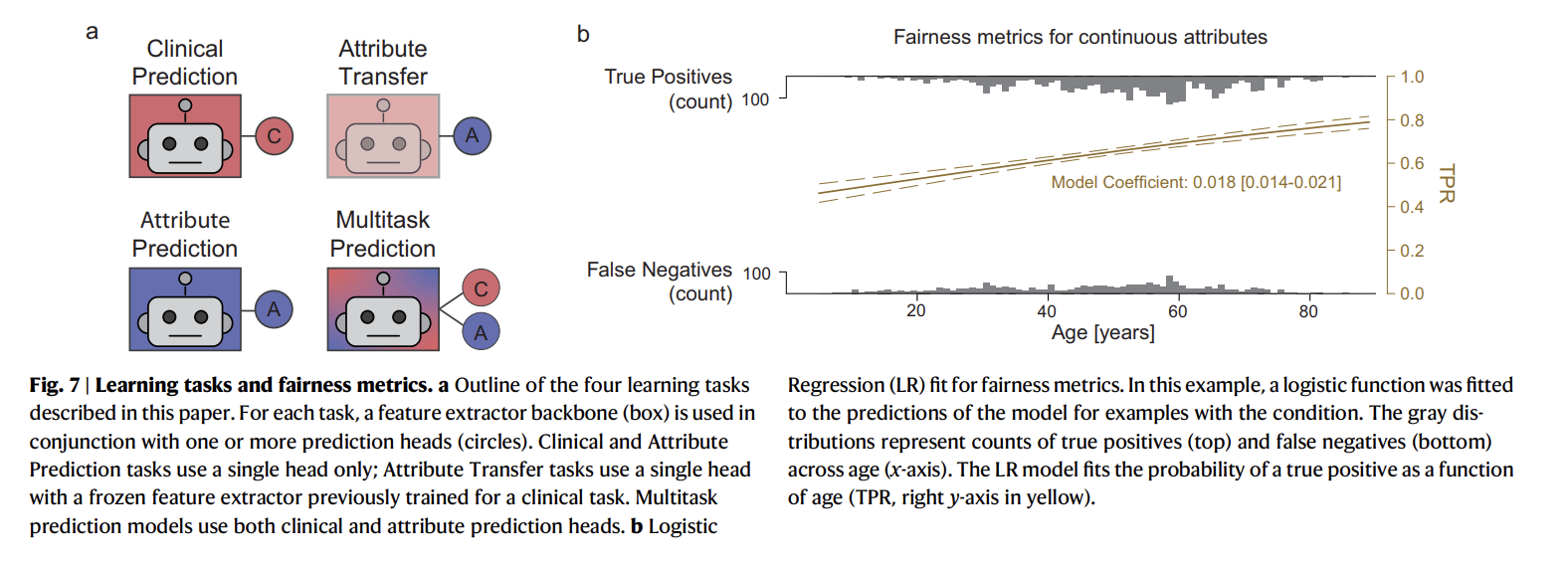
Author : Yukun Zhou, Mark A. Chia, Siegfried K. Wagner, Murat S. Ayhan, Dominic J. Williamson, Robbert R. Struyven, Timing Liu, Moucheng Xu, Mateo G. Lozano, Peter Woodward-Court, Yuka Kihara, UK Biobank Eye & Vision Consortium, Andre Altmann, Aaron Y. Lee, Eric J. Topol, Alastair K. Denniston, Daniel C. Alexander & Pearse A. Keane Paper Link :https://www.nature.com/articles/s41586-023-06555-x
Author : Scott L. Fleming, Alejandro Lozano, William J. Haberkorn, Jenelle A. Jindal, Eduardo P. Reis, Rahul Thapa, Louis Blankemeier, Julian Z. Genkins, Ethan Steinberg, Ashwin Nayak, Birju S. Patel, Chia-Chun Chiang, Alison Callahan, Zepeng Huo, Sergios Gatidis, Scott J. Adams, Oluseyi Fayanju, Shreya J. Shah, Thomas Savage, Ethan Goh, Akshay S. Chaudhari, Nima Aghaeepour, Christopher Sharp, Michael A. Pfeffer, Percy Liang, Jonathan H. Chen, Keith E. Morse, Emma P. Brunskill, Jason A. Fries, Nigam H. Shah Paper Link :https://arxiv.org/abs/2308.14089
Author : Shawn Xu, Lin Yang, Christopher Kelly, Marcin Sieniek, Timo Kohlberger, Martin Ma, Wei-Hung Weng, Attila Kiraly, Sahar Kazemzadeh, Zakkai Melamed, Jungyeon Park, Patricia Strachan, Yun Liu, Chuck Lau, Preeti Singh, Christina Chen, Mozziyar Etemadi, Sreenivasa Raju Kalidindi, Yossi Matias, Katherine Chou, Greg S. Corrado, Shravya Shetty, Daniel Tse, Shruthi Prabhakara, Daniel Golden, Rory Pilgrim, Krish Eswaran, Andrew Sellergren Paper Link :https://arxiv.org/abs/2308.01317
Author : Catarina Barata, Veronica Rotemberg, Noel C. F. Codella, Philipp Tschandl, Christoph Rinner, Bengu Nisa Akay, Zoe Apalla, Giuseppe Argenziano, Allan Halpern, Aimilios Lallas, Caterina Longo, Josep Malvehy, Susana Puig, Cliff Rosendahl, H. Peter Soyer, Iris Zalaudek & Harald Kittler Paper Link :https://www.nature.com/articles/s41591-023-02475-5