논문 리스트
TabTransformer: Tabular Data Modeling Using Contextual Embeddings (Xin Huang, arXiv 2022)
Paper Link: https://arxiv.org/abs/2012.06678
Talk: https://www.youtube.com/watch?v=-ZdHhyQsvRc
AWS Code: https://github.com/awslabs/autogluon/tree/master/tabular/src/autogluon/tabular/models/tab_transformer
Other Repo 1: https://github.com/lucidrains/tab-transformer-pytorch
Other Repo 2: https://github.com/timeseriesAI/tsai/blob/main/tsai/models/TabTransformer.py
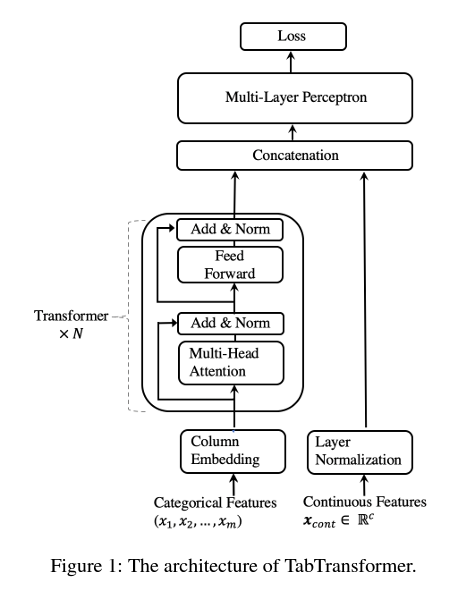
- by AWS
- Embedding layer로서 Transformer를 사용
- Tabular데이터에 대해 각 column에 대하여 Column Embedding 수행 후 Trasformer를 사용해 context embeddings를 생성
- 생성된 context embeddings는 concat하여 MLP classifier로 들어감
- Column Embedding
- 한 column이 d개의 클래스를 가지고 있을땐 missing value도 인덱스를 부여해 0부터 d+1까지의 lookup table로 인코딩
- one-hot보다 parametric embedding을 학습하는것이 더 나은 성능을 보여줌
- scalar column에 대해서는 3가지 방법의 re-scaling (quantiles, normalization, log)과 quantization을 방법을 모두 사용하여
- column identifier와 feature value를 따로 embedding하여 concat
- embedding dimension의 4, 28을 각각 column과 value dim으로 사용
- Transformer 아키텍쳐
- Transformer hiddem dim: 32
- Transformer layer: 6
- Transformer multi-head: 8
MET: Masked Encoding for Tabular Data (Kushal Majmundar, Arxiv 2022)
Paper Link: https://arxiv.org/abs/2206.08564
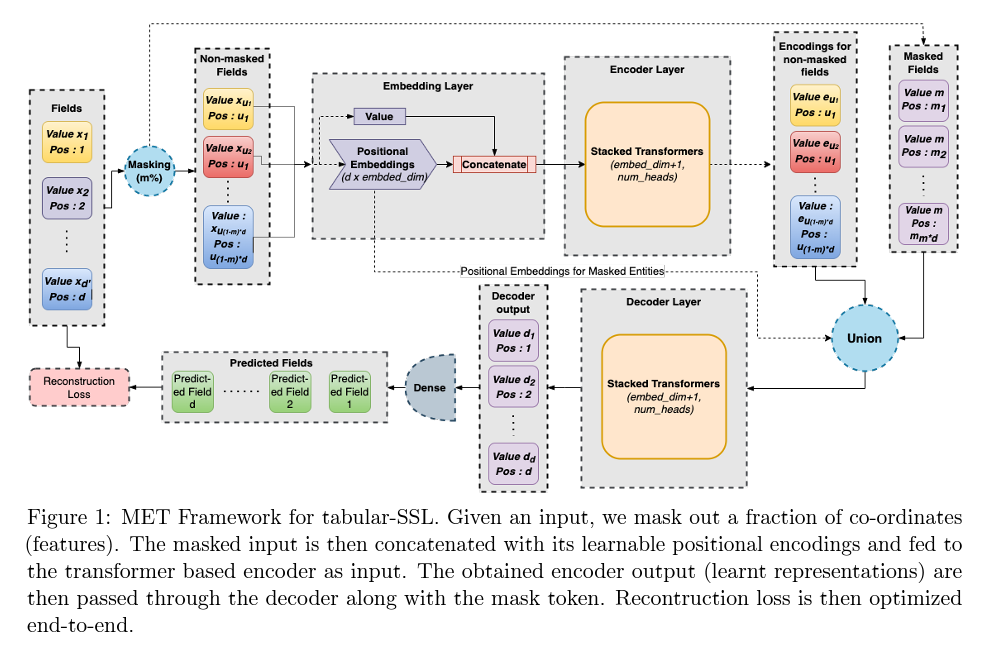
- by Google Research India
- Masked-AutoEncoder(MAE)방식의 SSL을 사용하여 tabular data의 embedding을 학습
- MAE Contributions:
- Downstream 테스크에 embedding을 전달할때 column별 context embedding을 average가 아닌 concatnation하여 전달
- 입력 데이터에 adversarial perturbation을 추가
- 인코더와 디코더 모두 Transformer사용
- mask되지 않은 column에 한하여, column identifier로서 학습가능한 e크기이 embedding과 feature value의 scalar를 concatation해 e+1 차원의 embedding이 생성되어 Transformer 인코더의 입력으로 들어감
- mask된 column은 column identifier와 학습가능한 special token으로서의 mask scalar를 contatation하여 masked embedding을 생성
- Transformer 인코더를 커쳐나온 context embedding에 masked embedding을 합쳐 Transformer 디코더에 넣어 전체 column을 복원
- Downstream task에 전달할때 contexted embedding column들에 대하여 average가 아닌 concat하여 전달
Tabular Transformers for Modeling Multivariate Time Series (Inkit Padhi, ICASSP 2021)
Paper Link: https://arxiv.org/abs/2011.01843
Code: https://github.com/IBM/TabFormer

- by IBM
- Tabular 데이터에 대한 BERT 및 GPT스타일의 sequence encodeing
- TabBERT
- 시간에 따른 각 row를 Field Transforer를 사용하여 row embeeding한 다음 token으로서 BERT에 입력
- Mask는 row단위가 아닌 row의 field단위로 mask하여 이를 예측하도록 학습
- TabGPT
- 각 row들을 [SEP]로 분리하면서 연속되게 이어서 입력으로 주며, 현재의 row가 들어갔을때 미래의 row들을 예측하도록 학습
- Continuous column은 quantization을 수행하여 categorical column으로 변환
TAPEX: Table Pre-training via Learning a Neural SQL Executor (Qian Liu, ICLR 2022)
Paper Link: https://arxiv.org/abs/2107.07653
Code: https://github.com/microsoft/Table-Pretraining
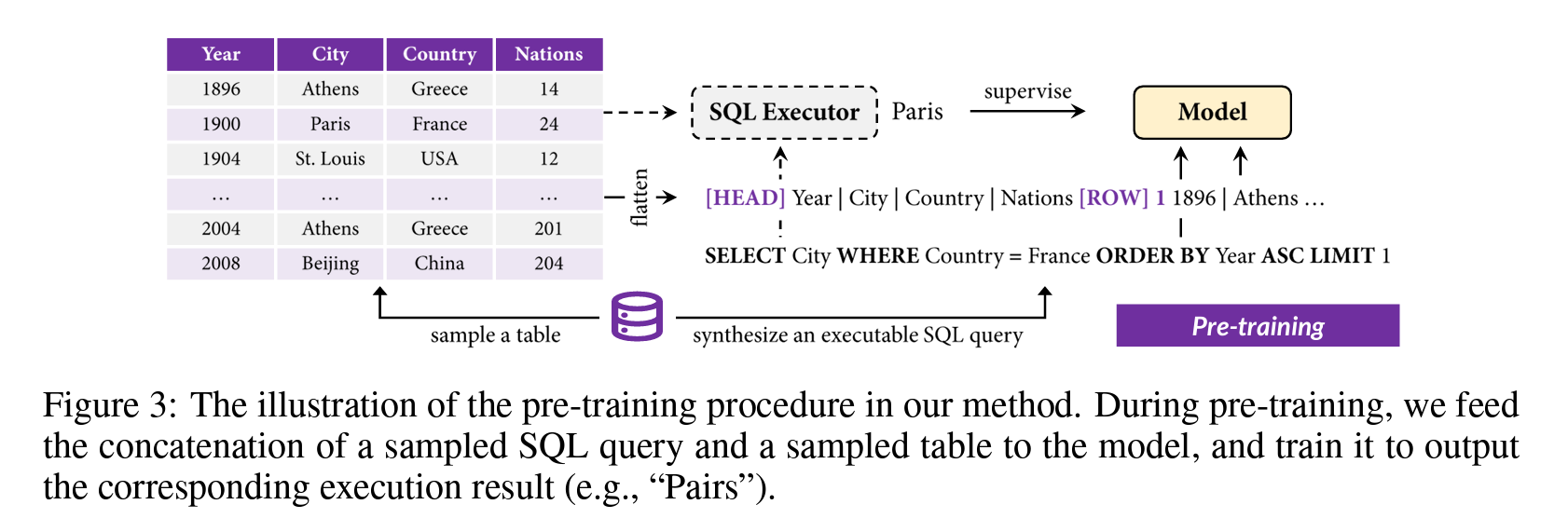
- by Microsoft
- 아키텍쳐로 BART를 사용
Revisiting Deep Learning Models for Tabular Data (Yura Gorishniy, NeurIPS 2021)
Paper Link: https://arxiv.org/abs/2106.11959v2
Code: https://github.com/Yura52/tabular-dl-revisiting-models
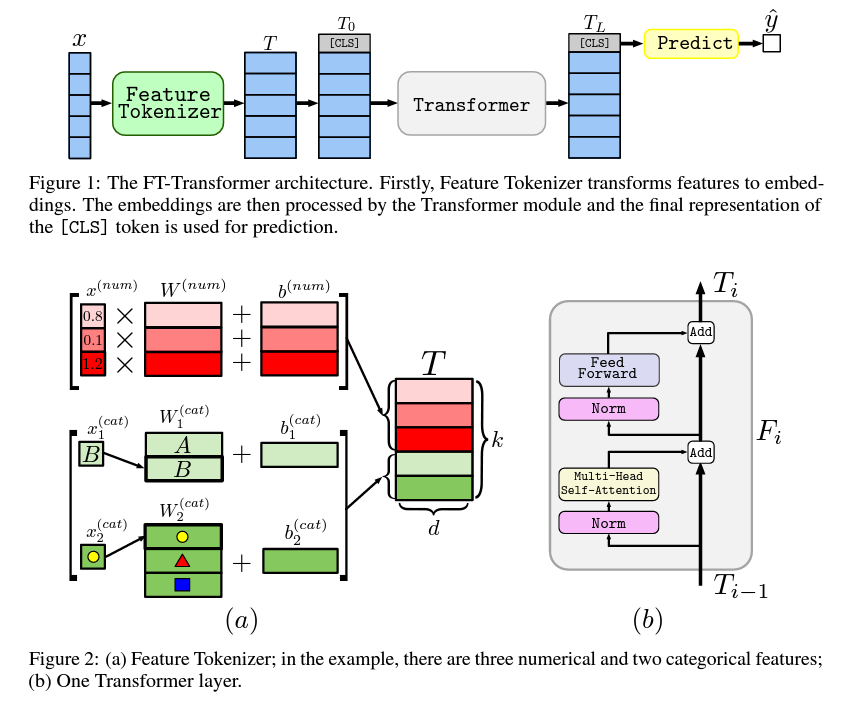
- by Yandex
- Feature Tokenizer를 통과한 토큰들과 [CLS]토큰을 사용한 prediction
- 각 column별로 weight와 bias가 있어 이를 개별 embedding
- catetorical column의 경우 lookup table에서 각 카테고리에 해당하는 벡터를 onehot vector와 곱해준 뒤 각 column에 해당하는 bias vector를 더해줌
On Embeddings for Numerical Features in Tabular Deep Learning (Yura Gorishniy, arXiv 2022)
Paper Link: https://arxiv.org/abs/2203.05556v1
Code: https://github.com/Yura52/tabular-dl-num-embeddings
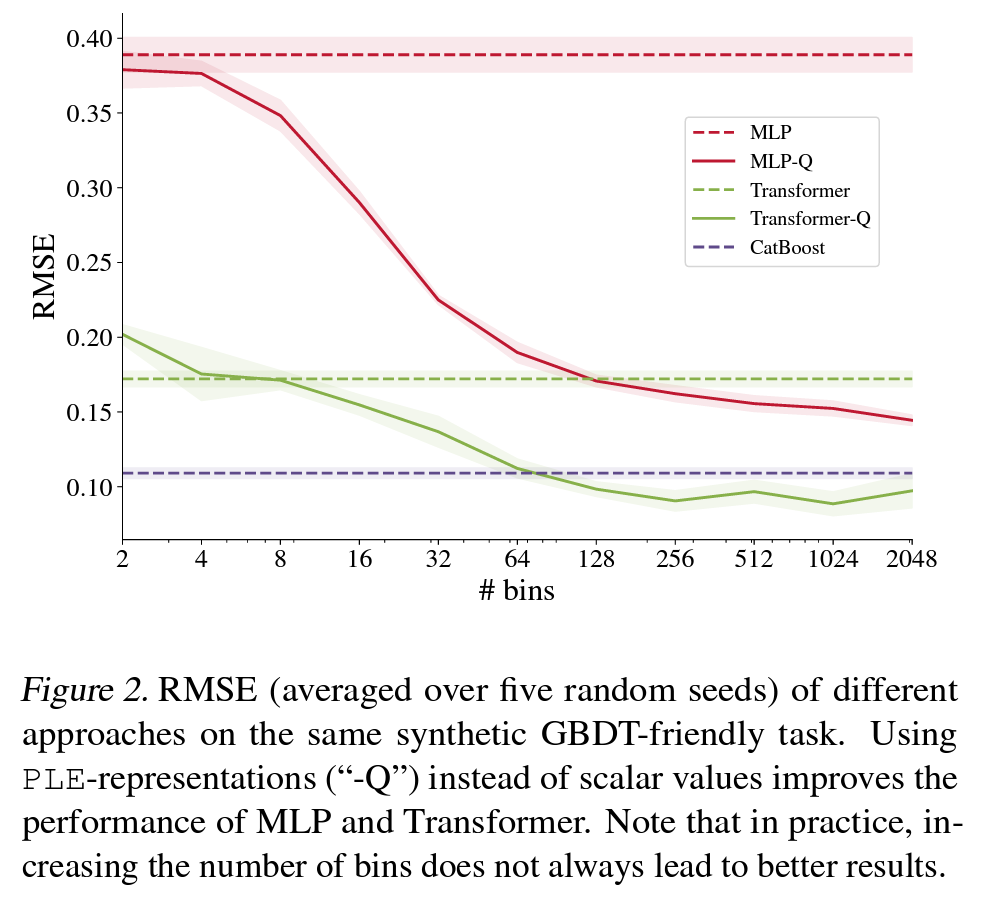
- by Yandex
- Tabular 데이터의 numerical feature에 대한 feature binning을 어떻게 하는게 좋은지에 대한 연구
- Token화 한 tabular 데이터를 Transforemr에 태워 prediction 테스크 수행
- scalar를 바로 넣어주는것 보다 one-hot의 개선된 버전인 PLE(piecewise linear encodding)을 사용할 경우 CatBoost보다 나은 성능을 보여주기도 함
Revisiting Pretraining Objectives for Tabular Deep Learning (Ivan Rubachev, arXiv 2022)
Paper Link: https://arxiv.org/abs/2207.03208
Code: https://github.com/puhsu/tabular-dl-pretrain-objectives
- by Yandex
그 외 깃헙 레포 리스트
- https://github.com/yandex-research/rtdl (위 Yandex사의 3개 논문 종합 레포)