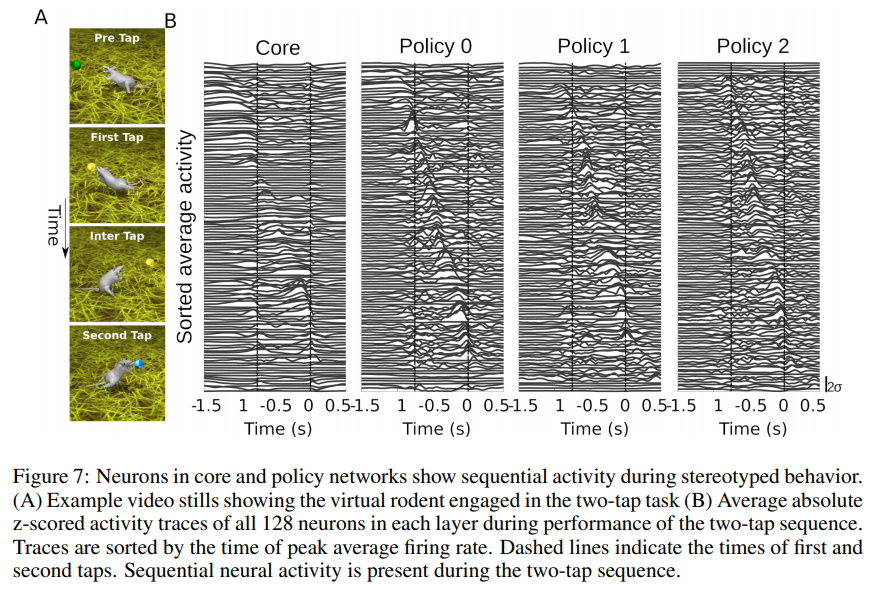
Author : Matthew Botvinick, Jane X. Wang, Will Dabney, Kevin J. Miller, Zeb Kurth-Nelson
Paper Link : https://doi.org/10.1016/j.neuron.2020.06.014
0. ABSTRACT
- 최근 몇 년간 뇌 기능 모델(i.e. vision, audition, motor control, navigation, cognitive control)에 근간한 딥러닝에 대한 연구 크게 급증함
- 하지만 그 중 Supervised Learning(SL)을 활용한 개념적 접근은 과거에 이미 많이 논의되어온 부분이며, 컴퓨팅 성능 및 데이터의 향상으로 재조명 받는 것
- 이에 여기선 신경과학자들에게 생소하지만 신경과학과 매우 긴밀한 연관성을 가지고 있는 Deep RL에 대해 리뷰하고 open challenge들에 대해 논의하고자 함
- 물론 RL역시 신경과학 연구에 영향을 많이 주어왔지만, 딥러닝과 결합되어 실질적인 결과를 보여주며 열매를 맺기 시작한건 불과 몇 년 안됨.
- 이러한 성과들은 뇌b의 주요 기능에 대해 흥미로운 접근을 가능하게 하면서 신경과학에서 아직 밝혀지지 않은 부분에 대한 더 많은 연구기회를 제공함
1. AN INTRODUCTION TO DEEP RL
- (이 챕터는 RL의 복잡한 문제에 대한 한계를 딥러닝이 해결했다는 내용으로, 신경과학자를 대상으로한 Deep RL의 보편적 설명에 해당하여 정리는 생략)
- Deep RL을 quantom jump하게 한 DQN알고리즘은, 의의가 그 성능보다 RL문제를 SL화 하여 얻은 안정성에 있음을 강조
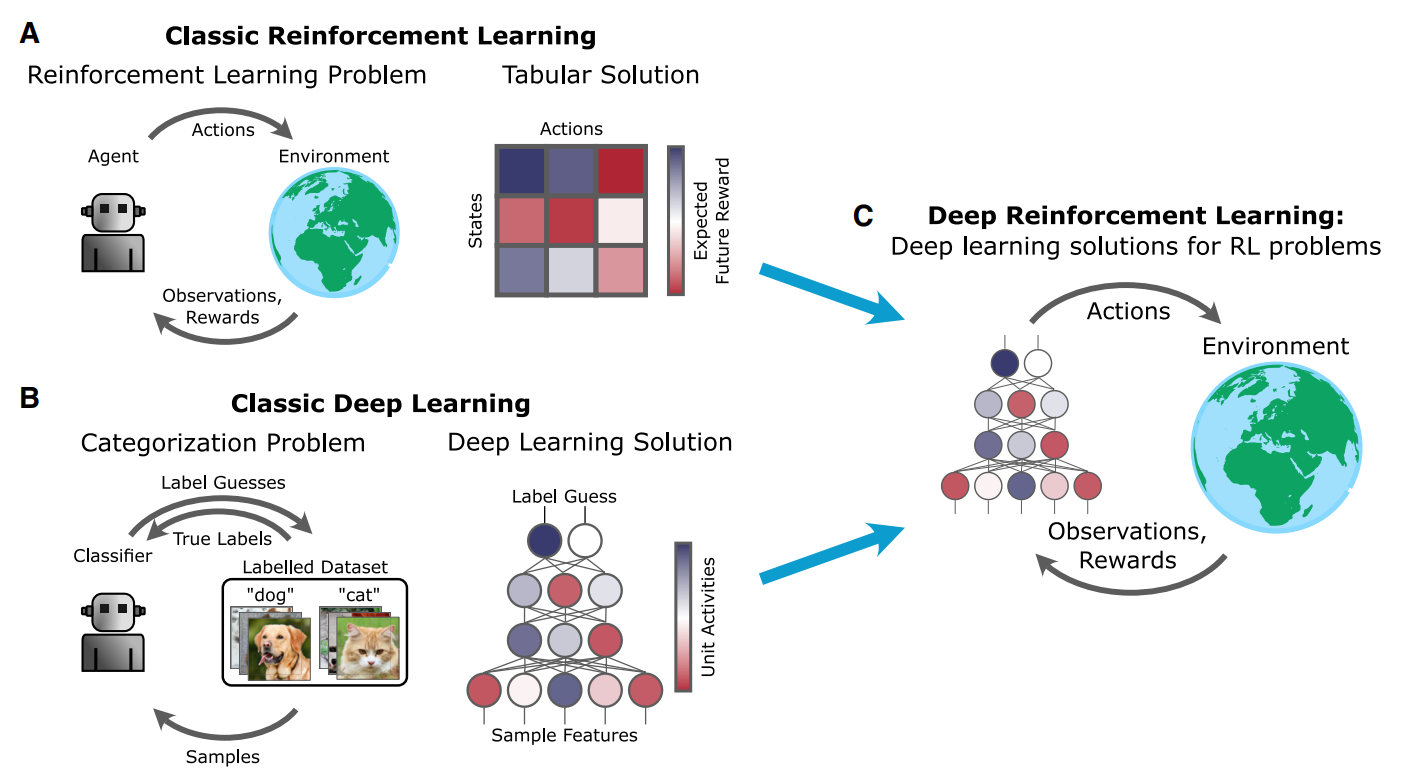
2. DEEP RL AND NEUROSCIENCE
- Deep neural network(DNN)이 실제 신경의 representation에 대한 매우 좋은 모델이라는 것은 Convolution Network를 통해 이미 증명됨
- 하지만 이러한 신경의 모델링을 통한 연구는 지금까지 대부분 SL을 사용하였기 때문에, 생물의 sensory-motor loop에서의 동기 및 목적 지향적 행동을 이해하는것과는 거리가 있음
- 반면 RL은 생물의 학습과 결정에 대한 신경학적 메커니즘에 있어 강력한 이론을 제공:
1. Reward-prediction error (RPE)로서의 도파민 뉴런의 활성을 설명
2. 보상기반의 학습과 의사결정에 있어서 뇌 구조에 따른 역할을 설명 - 딥러닝에선 representation이 어떻게 학습되는지가 중요하며, RL에선 보상이 학습을 어떻게 가이드 하는지가 중요
- 하지만 Deep RL에서는 딥러닝과 RL 두 분야의 단순한 결합 이상의 현상을 확인 가능하며, 신경과학에 있어 새로운 원리, 가설, 및 모델을 제공함
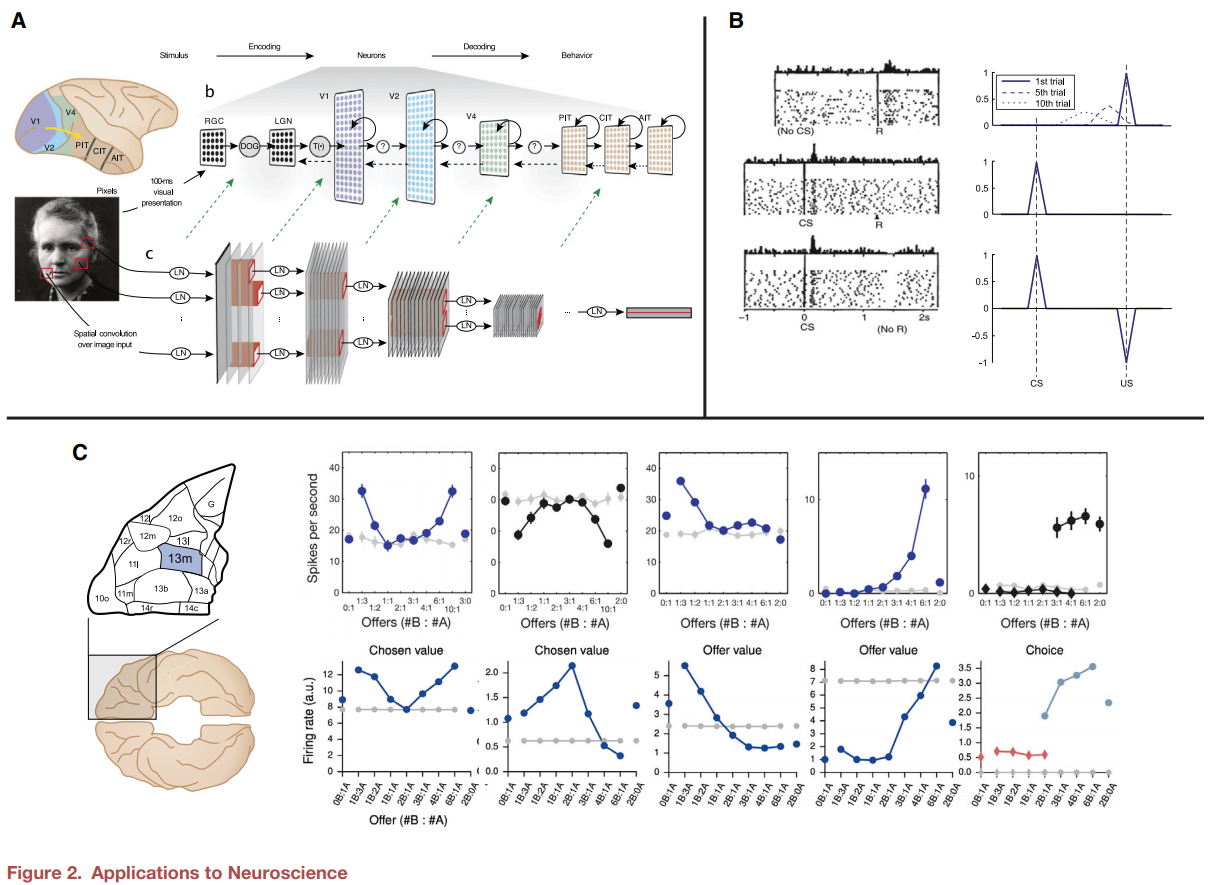
3. VANGUARD STUDIES (선행연구)
- 많은 연구들이 deep RL을 신경학적 관점에서 설명하고 있지만, 실제 신경 데이터에 deep RL을 적용한 경우는 거의 없으며 시작된지 불과 2~3년 남짓 되는 분야임
- 일부 연구에서는 기존의 딥러닝 혹은 SL을 활용한 신경과학적 연구 접근법을 그대로 RL을 사용한 신경과학 연구에 적용함
- Song et al. (2017) 에서는 recurrent deep RL 을 실제 신경과학에서 사용된 task에 대해 학습했을 때, 신경망의 unit에서 보이는 활성 패턴이 실제 원숭이 실험에서의 dorsolateral prefrontal, orbitofrontal 및 parietal cortex에서의 패턴과 연관성이 있음을 확인
- Banio et al.(2018) 에서는 SL과 deep RL을 결합하여 entorhinal cortext에서 발견되는 그리드형 표현이 rat의 navigation 능력을 어떻게 향상시키는지를 보여줌 - 앞서 강조한 바와 같이 deep RL에선 딥러닝과 RL 각각의 기존 특징 이상의 현상(ex. Meta-learning)이 나타나며, 이를 신경과학에 적용한 연구들이 최근 이루어짐
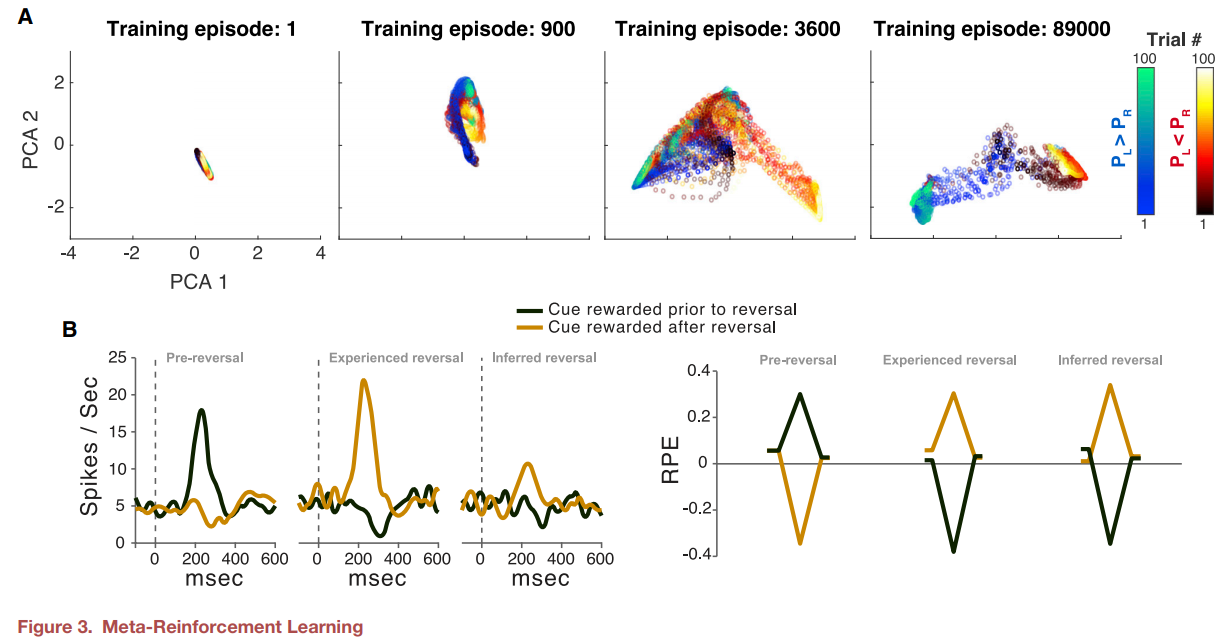
- Wang et al. (2018) 에서는 RNN에 기반한 deep RL이 네트워크의 파라메터 업데이트 없이 뉴런의 activation 변화 만으로도, 새로운 task에 빠르게 적응하는 Meta-RL의 특징을 지니는것을 확인하였음. 즉, 네트워크 파라메터 수준의 'Slow RL'기반 학습만으로도 hiddend state에 의한 네트워크 activation에 의한 빠른 적응을 의미하는 'Fast RL'이 가능한 activation역학을 습득할 수 있으며, 이는 신경과학에서의 강화학습 역시 신경의 활성기반 working memory가 뒷받침한다는 사실 (Collins and Frank, 2012) 과 유사함. 또한 이러한 mera-RL 효과가 이전 신경과학 연구에서의 도파민과 prefrontal cortext에 대한 발견들을 어떻게 설명하는지를 보여줌
4. TOPICS FOR NEXT-STEP REASEARCH
- 작성중
4.1. REPRESENTATION LEARNING
4.2. MODEL-BASED RL
4.3. MEMORY
4.4. EXPLORATION
4.5. COGNITIVE CONTROL AND ACTION HIERARCHIES
4.6. SOCIAL COGNITION
5. CHALLENGES AND CAVEATS
'BIOMEDICINE > Neuroscience' 카테고리의 다른 글
| [정리] Deep Neuroethology of a Virtual Rodent (Josh Merel, ICLR, 2020) (0) | 2020.06.04 |
|---|