
Author : Takahiro Miki, Joonho Lee, Jemin Hwangbo, Lorenz Wellhausen, Vladlen Koltun, Marco Hutter
Paper Link : https://www.science.org/doi/10.1126/scirobotics.abk2822
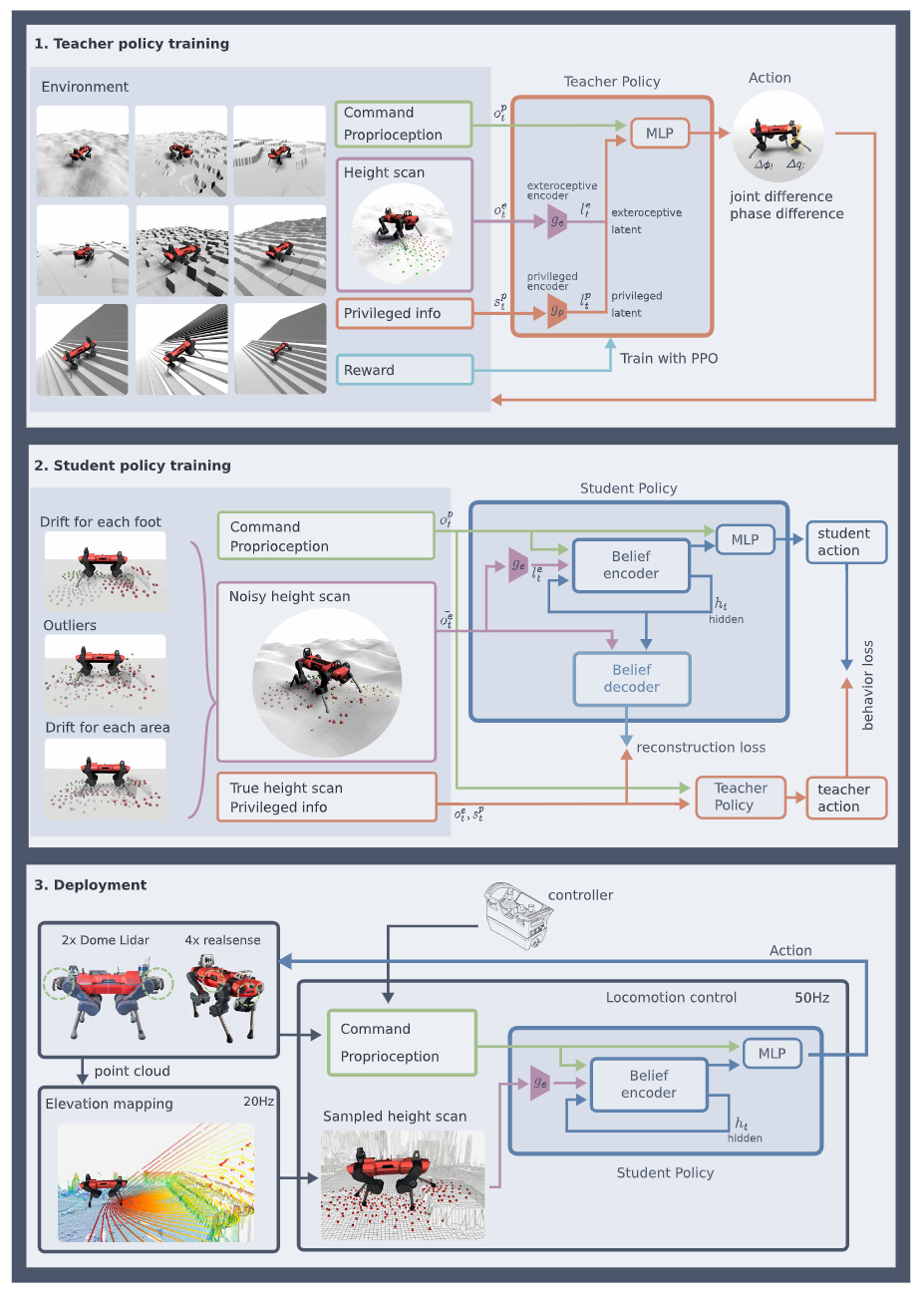
Contributions
1. Context based meta-RL을 활용하여 예상치 못한 or 노이즈가 강한 환경에서의 4족보행 로봇의 real-world robustness 구현
- Recurrent belief encoder가 센서로는 측정되지 않는 true dynamics에 대한 정보를 내포하는 latent task belief를 추론하고, 이를 RL policy가 활용
- Attentional gate를 사용하여 prioprioception(고유수용성 감각; 로봇자체의 움직임에 대한 센서) 과 exteroception(외수용성 감각; 외부환경에 대한 센서)의 multi-modal 센서에대한 상황에 따른 선택적 활용
2. 시뮬레이션의 이점을 활용한 privileged learning기반의 zero-shot sim-to-real transfer learning
- 현실적인 조건을 가정한 충분히 다양한 물리적 환경을 시뮬레이션상에서 미리 학습
- 이상적인 조건에서 학습되는 teacher policy와 현실적인 조건에서 teacher policy가 학습한것을 knowledge distillation하는 student policy
- 3 단계에 걸쳐 zero-shot sim-to-real transfer learning을 구성
- Step1: Teacher policy training
- 랜덤하게 생성된 지형에서 명령으로 준 랜덤 target velocity와의 차이를 reward로 PPO알고리즘에 주어 학습
- Teacher policy의 입력으로는 1. 속도 command, 2. proprioception센서 정보, 3. exteroception 센서 정보 4. previleged 정보 (ex. 마찰력과 같은 환경의 true dynamics)
- 시뮬레이션을 활용하여 이상적인 정보를 줌으로써, RL알고리즘이 충분히 optimal에 가까운 policy를 학습하도록 유도 - Step2: Student policy training
- Student policy의 입력으로는 1. 속도 command, 2. proprioception센서 정보, 3. 노이즈가 들어간 exteroception 센서 정보
- 충분하지 못한 정보에서 scratch로 좋은 RL policy를 학습하기보다, 이미 학습한 좋은 tearch policy를 supervised learning으로 distill하여 효율적으로 학습; privileged learning
- Prorioception정보와 extroception정보로부터 unobervable state에대한 belief를 추론하기위해 recurrent belief state encoder를 제안
- Belief encoder가 좋은 latent space를 학습하도록 하기위해, previleged 정보와 true exteoception정보에 대한 reconstruction loss를 사용 - Step3: Deployment
- 실제 로봇에 학습한 student policy를 decoder를 제외하고 deploy
- Context based meta-RL인 만큼 fine tunning이나 optimization 없이 실시간으로 real-world에 adaptation가능
- Exteroception정보는 경우에 따라 틀리거나 얻지못할 수 있으므로, 필요에 따라 exteroception정보에서 의미있는 정보를 선별하여 쓰기위하여 attention gate를 사용한 gated encoder 적용
- Attention gate는 최종 belief state에 어느정도의 exteroception정보를 담을지를 조절
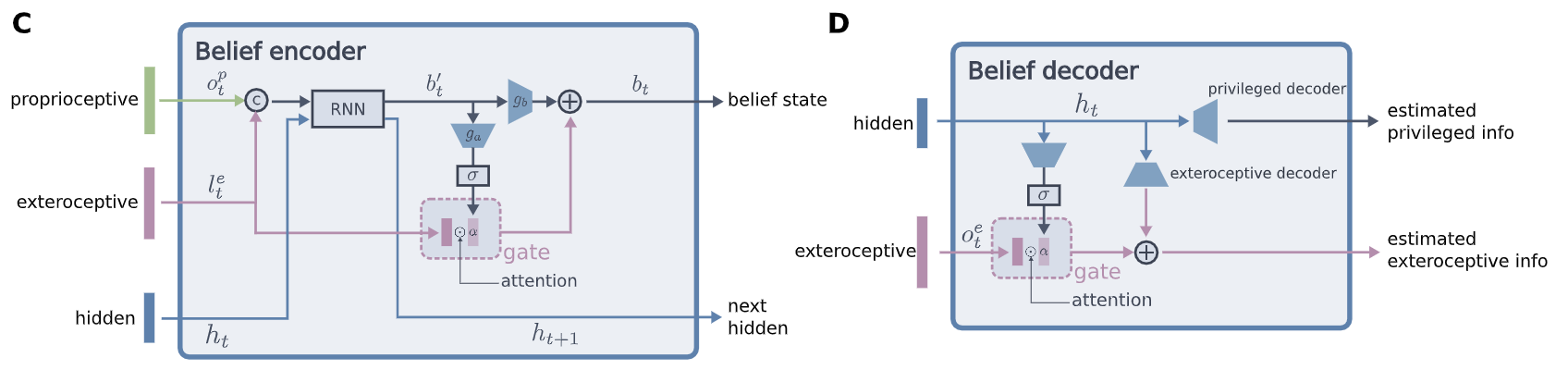
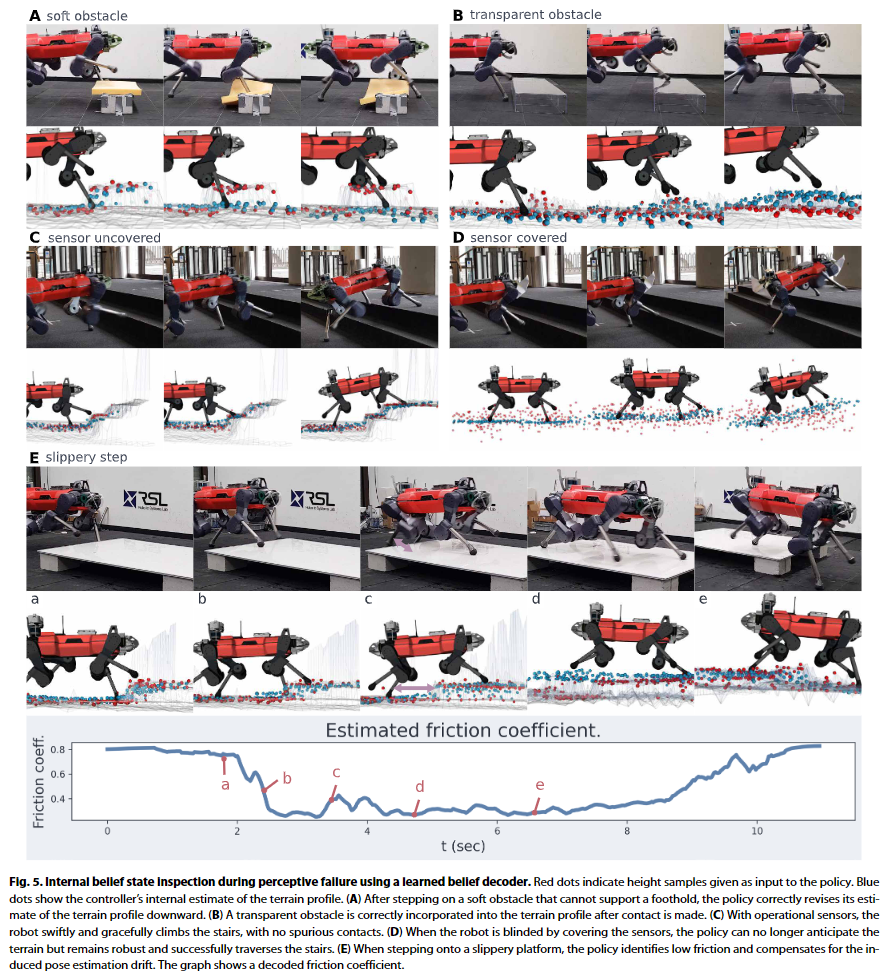
- Autoencoder를 사용하여 representation learning을 한 만큼, decoder를 사용하여 internal belief를 시각화 가능
- 아래 그림에서 빨간 점은 policy에 입력으로 들어가는 실제 지면높이 정보 파란 점은 decoder에 의해 복원된 지면높이에대한 agent의 belief
- A) 스펀지 장애물을 밟기전엔 지면 높이가 높다고 생각하고 있다가, 스펀지를 밟자으면서 들어오는 시계열의 푹신한 반응정보로부터 encoder는 실시간으로 평평한 지면 인것으로 belief가 변경
- B) 투명한 장애물을 exteroception 센서가 인식못해 평평한 지면이라고 생각하다가, 상자를 밟는 순간 지면의 높이가 있는것으로 belief가 변경
- D) 센서가 완전히 가려진 상태에서도 지면이 경사졌다고 판단다는 belief가 형성되며, 이는 사람이 걸으며 주변환경이 어두워질 경우 시각에서 체성감각으로 주의를 옮겨 지형지물을 판단하는것과 유사
- E) 미끄러운 지면의 장애물을 걸을경우, 미끄러지는 만큼의 연장된 너비의 지면에 대한 belief가 형성하는 동시에 마찰의 변화 역시 추정
- 실제 real-world 환경에서도 넘어짐 없이 robust하게 동작하는 영상