
Author: Ayush Jain, Norio Kosaka, Kyung-Min Kim, Joseph J Lim
Paper Link: https://openreview.net/forum?id=MljXVdp4A3N
Site: https://sites.google.com/view/varyingaction
Code: https://github.com/clvrai/agile
0. Abstract
- 지능이 있는 개체는 현재 행할 수 있는 action들의 종류에 따라서 유동적으로 task를 풀 수 있는 반면, 보편적인 RL은 고정된 action set을 가정하고 있음.
- 예를 들어 목공 수리를 하는 task에서 '못질을 하는 action'은 '망치를 드는 action'이 있을때만 의미가 있음.
- 본 연구에서는, 이러한 action사이의 상관관계를 활용하기위해 graph attention network를 활용가능한 action들에 적용하는 방법을 제안함.
- 결과적으로 이 관계성 접근방법을 사용할 경우, value-based 및 pollicy-based RL알고리즘 모두 에서 서로 연관된 action을 활용하는것이 가능함을 확인했으며
- action sapce가 변하는 추천시스템 및 물리적 reasoning과 같은 문제에서 기존의 비관계성 아키텍처들보다 뛰어난 성능을 보이는것을 확인함.
1. Introduction
- 액자를 벽에 거는 task가 있을때, 망치가 있을땐 못을 사용하면 되지만 후크가 있을땐 접착테잎을 사용해야함.
- 즉, 최선의 의사결정은 환경 뿐만이 아니라 현재 활용가능한 action에도 의존.
- 기존 RL은 fixed action space를 가정하고 있기때문에 최근엔 RL에서도 변화하는 action space 혹은 unseen action 문제를 다루고자하는 연구가 발표되고 있으나, 위 예시와 같은 action들 사이의 interdependence에대한 학습을 다루진 않았음.
- Varing action sapce에서의 interdepence문제로는 매일 추천해야할 기사의 set이 바뀌는 recommender system 혹은 공구/목적/스킬에 따른 물리적 reasoning이 있음
- 본 연구에서는 graph attention network (GAT)를 핵심요소로 하는 AGILE, Action Graph for Interdependence Learning 이라는 policy 아키텍처를 제안하며,
1. 입력으로서의 action set의 요약과 2. action들 사이의 관계정보 학습을 그 목적으로 함.
2. Related Work
2.1 Stochastic Action Sets
- 정해진 전체 action pool에서 활용가능한 action set이 랜덤하게 샘플되는 경우를 stochastic action sets라고 하며, 기존 연구에서는 활용불가능한 action의 경우 확률분포의 출력을 masking하는 방식 등을 사용함.
- 하지만 전체 action pool이 미리 정해져 있는것은 추천시스템과 같이 unseen item을 자주 받는 경우엔 실용성이 떨어짐.
- 또한 기존 연구와 같이 매 timestep마다 action set이 바뀌는것 역시 실용성이 떨어짐.
- 이에 본 연구에서는 한 episode에서는 샘플된 action set이 유지되도록하며, unseen action을 마주하는 상황에 대한 한계를 다루고자 action representation을 사용하는 방법을 활용함.
2.2 Action Representations
- 넓은 action space, transfer learning, shared structural action 등의 문제를 위해 action representation을 활용하는 방법이 기존 논문들에서 사용됨.
- 본 연구에서는 agent가 base action pool에 대한 사전지식을 활용하는것을 피하고 unseen action 문제를 다루고자 action representation을 사용함.
2.3 List-wise Action Space
- action의 선택이 large set I에서 k아이템의 subset인, 즉 combinatorial action space (Ik)에서 최적의 action list를 찾는 강화학습 문제를 list-wise RL 혹은 slate RL이라고 함.
- 본 연구에서는 제안하는 AGILE policy 아키텍처가 list-wise RL에도 적용가능함을 보여주고자 함.
2.4 Relational Reinforcement Learning
- GNN은 관계성이 중요한 task를 다루는 기존 RL연구들에서 사용 됨.
- 본 연구에서는 task를 풀기위해 action들 사이의 interaction이 중요한 문제들을 다루고자하며, 이 과정에서 의미있는 action interaction을 모델링 하기 위해 graph attention network (GAT)를 활용함.
3. Problem Formulation
- 위에서 든 벽에 액자를 거는 예시와 같이, 주어진 action set에서 최선의 행동을 위한 action간의 interdependence를 학습하는것이 여기서 풀고자하는 문제의 핵심.
3.1 Reinforcement Learning with Varying Action Space
- 강화학습으로 문제를 접근하기위해 다음의 MDP를 정의
{S,A,T,R,γ}
- 이때 A 는 countably infinite한 action의 집합.
- 무한한 action set을 handling하고자, 여기선 추가적으로 a∈A에 대한 D-차원의 action representation ca∈RD 를 정의.
- Action의 subset인 A⊂A와 이에 해당하는 representation C 가 주어졌을 때, 여기서 agent의 목적은 unseen action들또한 포함한 subset에 대해 다음의 retrun 을 최대화하는 policy π(a∣s,A)을 학습하는것
EA⊂A[∑tγt−1rt]
3.2 Challenges of Varying Action Space
- Varing action sapce에서의 interdepence문제에는 챌린지가 있으며 그 대응안은 다음과 같음.
1. 모든 action이 다 주어지는것이 아니므로 policy framework는 유연해야함. 이를 위해 action representation C을 사용.
2. 현재 환경에서 활용 가능한 action set이 변하는 경우에는 기존의 state space S만으로는 환경의 상태를 완전히 표현할 수 없으므로, S는 Markovian이 아님. 이에, action set representation을 추가한 hyper state space S′를 새롭게 정의. S′={s∘CA:s∈S,A⊂A}
3. 활용가능한 action들 사이의 interdependence가 학습되어야함. 구체적으로, 최적의 agent는 미래의 활용 가능한 action들 cai∀ai∈A 과 현재의 활용가능한 action들 cat 의 특성간의 관계를 explicitly 모델링 할 수 있어야 됨.
4. Approach
- 제안하는 접근의 핵심은 GNN을 사용하여 action representation set를 임베딩하는 동시에 action들 사이의 관계를 학습하는 것.
4.1 AGILE: Action Graph for Independence Learning
- Action representation C의 리스트와 state encoding이 주어졌을때, 이 를 각각 concat하여 fully-connected action graph를 만듬.
- 여기에 graph attention network (GAT)를 사용하여 action간의 관계를 attention weight로서 추론함.
예) Figure 2.에서 대포와 불은 높은 attention weight를 가짐 - Utility network는 state encoding, GAT의 결과인 relational action representation, 그리고 meal-pooling을 한 action summary를 사용하여 RL알고리즘의 Q나 logit을 계산.
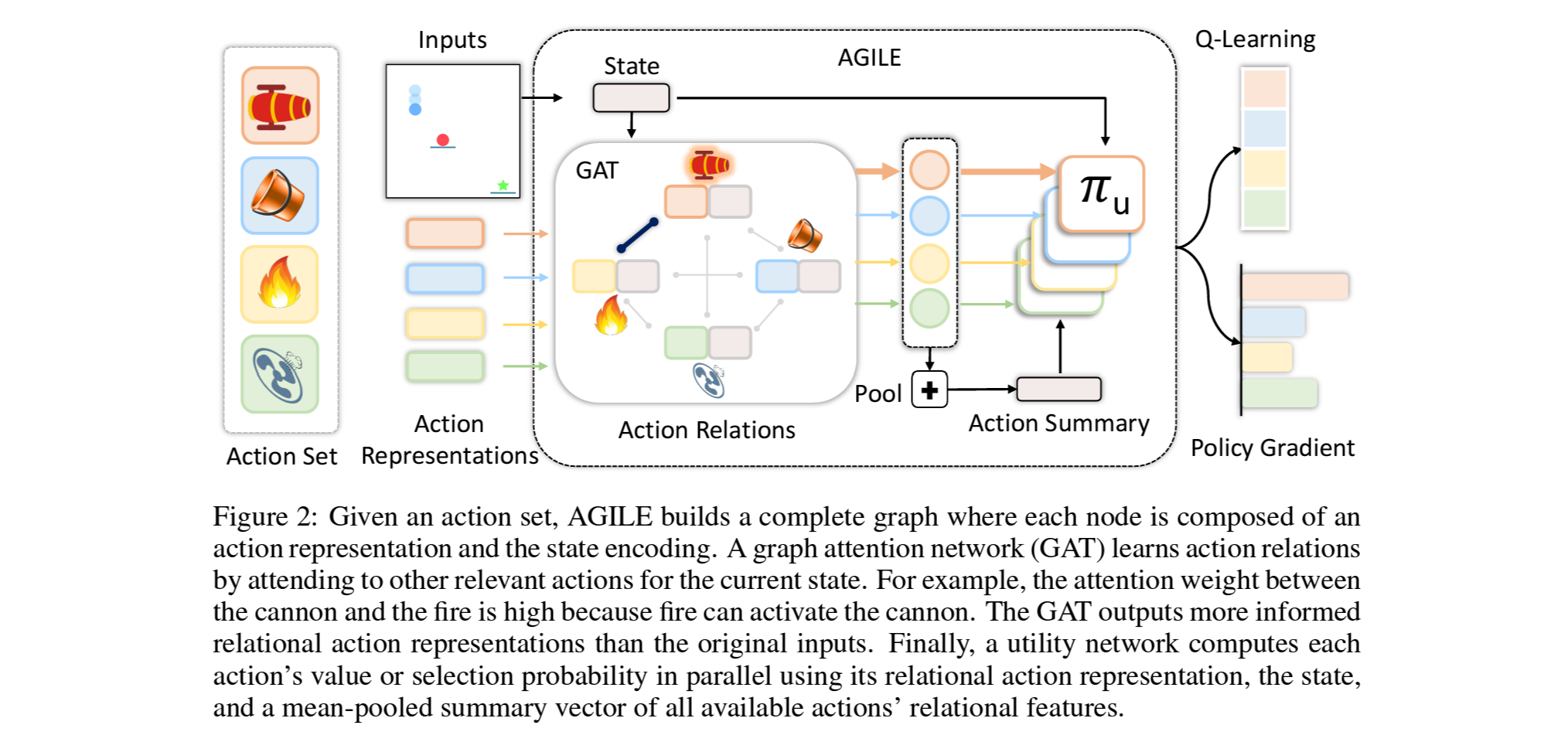
Action Graph:
- State에 따라 action들 사이의 관계가 달라짐.
(예: 스크류드라이버와 전동드릴은 나사못과의 관계가 유사하지만, 가구조립시엔 드라이버가 좀 더 선호되며 벽에 사용할땐 드릴이 좀 더 선호됨) - 즉, action representation만을 고려하여 graph를 만드는것이 아닌, state를 결합한 새로운 action representation c′ai=(s,cai)를 각 노드의 feature로 하여 fully-connected action graph G를 구성함.
- 이 후 실험파트에서, 이와같이 state를 추가할 경우에 더 optimal에 가까운 결과를 보여주는것을 다룸.
Graph Attention Network (GAT):
- 만들어진 action graph G를 GAT의 입력으로 넣어, 주어진 action set 중에서 서로 연관성이 큰 action들에 더 포커스를 하도록 학습.
- GAT에 대한 설명은 고려대학교 DMQA 연구실 소속이었던 강현규님의 세미나를 참고.

- 충분한 propagation이 가능하도록하기위해 ELU를 사이에 연결한 2개의 graph attention layer를 구성.
- 이 후 실험파트에서, 두번째 레이어 다음의 residual connection은 중요한 반면 multi-head attention은 영향이 없는것을 결과로서 다룸.
Action Set Summary:
- GAT의 출력은 relational action representation CR={cRa0,⋯,cRak}이며, 각 action representation은 가능한 다른 action과 그 관계에 대한 정보를 내포하고 있음.
- 앞서 MDP정의에서 다룬바와 같이, 현재 주어진 action set을 state변수로 고려하는 목적에서 action set 정보를 요약하기위해 mean-pooling을 다음과 같이 수행함. ¯cR=1K∑Ki=1cRai
Action Utility:
- 앞서 계산관 값들은 RL네트워크에 전달하기 위한 utility score를 계산하는 utility network 아키텍처 πu에 입력으로 전달 됨. 즉, πa(cRa,s,¯cR)
4.2 Training AGILE framework with Reinforcement Learning
- AGILE 아키텍처의 학습은 PPO, DQN, CDQN을 사용하여 end-to-end로 각각 수행.
(RL에 대한 자세한 내용은 이 포스팅에선 생략. CQDN은 list-wise action 문제에 대한 RL알고리즘.)
5. Environments
- AGILE알고리즘의 실험은 세가지 서로 다른 특징을 가진 환경에서 진행.
1) Dig Lava Grid World: 샘플링된 skill을 사용한 최단경로 찾기
2) CREATE: 물건을 목적지로 옮기기위해 샘플링된 도구들을 physical reasoning하여 선택하기.
3) Recommender Systems:
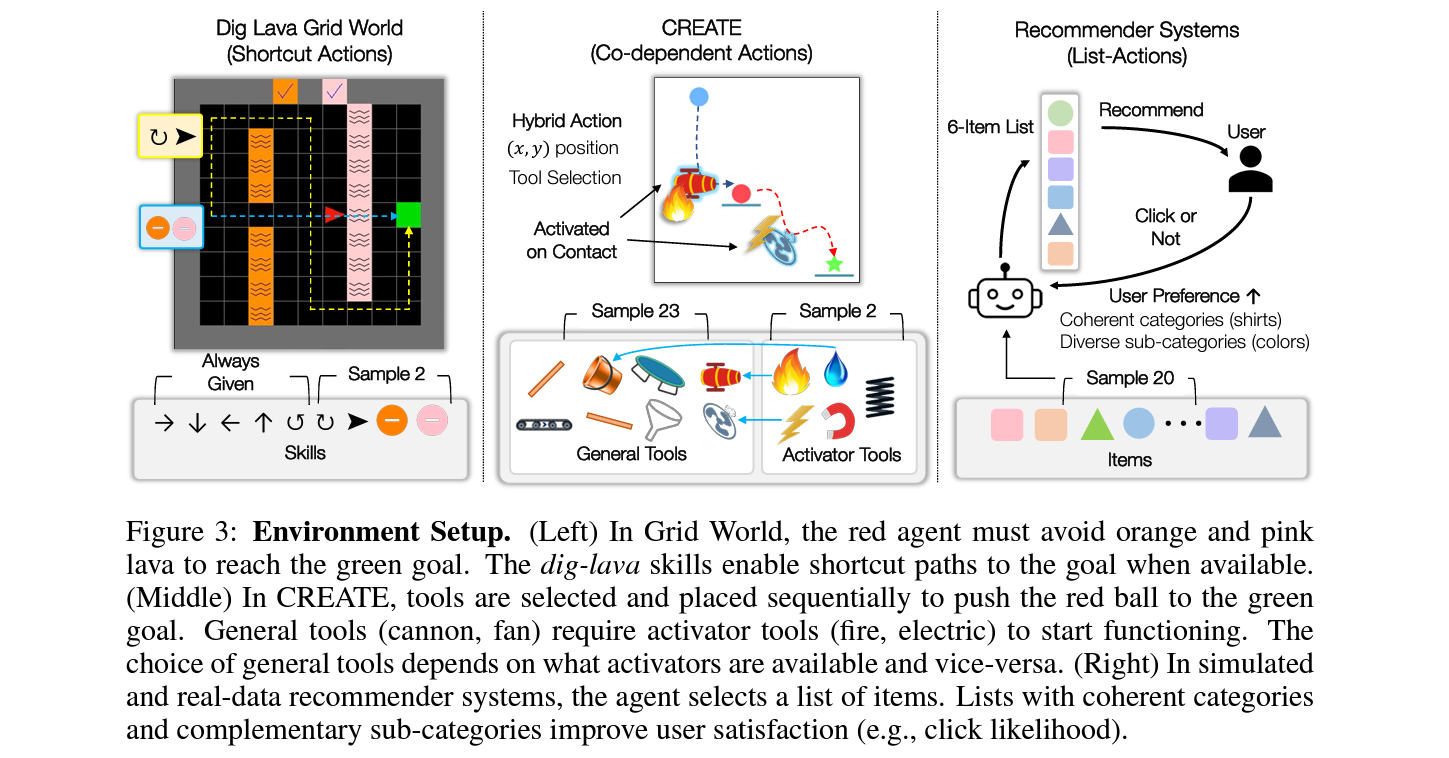
5.1 Dig Lava Grid Navigation
- 최단 경로 찾기의 대표적인 toy 환경인 기존의 2D Grid World에서 디폴트 5개 action 외에 4개의 추가 action 중 2개가 랜덤하게 더 주어질 경우, 이를 활용하여 최단 경로를 개선하는 문제.
- 용암에 들어간 후 다음 스텝에서 용암의 색깔에 맞는 땅파기 스킬을 사용하면 용암이 사라지나, 두 스텝 연속으로 용암에 들어 있으면 해당 에피소드는 실패.
- RL알고리즘으론 PPO 사용.
5.2 Chain Reaction Tool Environment: CREATE
- 2차원 공간 상에서 주어진 도구들을 사용하여 빨간색공을 목적지로 옮기는 문제 .
- 기본도구와 기본도구를 활용하기위한 동력장치가 각각 샘플링되어 주어졌을 때, 이를 사이의 물리적 관계를 파악하고
- RL알고리즘으론 PPO사용.
5.3 Recommender Systems
- RecSys, 즉 추천시스템은 variying action space RL문제로 볼수 있음.
(예: 매일 새롭운 기사나 유투브 영상이 올라오며 이중에서 추천이 이루어짐) - Complementary Product Recommendation (CPR): 추천을 할 때 high level에선 관련이 있지만 low level에서는 다양성을 늘리는것을 말하며 long-term 관점에서 서비스를 운영할 때 매우 중요한 부분.
(예: primary category는 셔츠 및 바지와 같은것이라면 subcategory는 색깔)
CPR=EntropyofsubcategoryEntropyofcategory
- 본 연구에서는 user preference에 더해 현실적인 시나리오를 만들고자 listwise item이 잘 추천된지에 대한 metric으로 CPR을 추가적으로 사용.
- CPR의 정의에 따라, CPR을 최적화 하려면 추천 agent는 가장 보편적인 primary 아이템을 찾아
- 이 후 실험에서는, 추천 시뮬레이션 환경에서는 user의 클릭수로 함축적으로 CPR를 최대화하고, 실제 서비스 데이터에서는 reward로서 명시적으로 CPR을 최대화.
5.3.1 Simulated Recommender System: RecSim
- 사용자 인터렉션을 시뮬레이션하고 강화학습을 적용하기위해 구글에서 개발한 환경인 RecSim (Github)을 listwise recommendation task로 확장. (RecSim에 대한 자세한 내용은 DataBro 님의 포스팅 [1], [2] 참조)
- train과 test 아이템이 각 250개씩 있으며, 매 에피소드마다 20개의 아이템이 샘플링되어 agent에 주어지고 agent는 매 step마다 6개의 아이템을 추천.
- user의 state는 각 아이템에 따른 preference를 embedding한 vector로 구성.
- user는 preference에 따라 추천된 아이템중 하나를 클릭하거나 아무것도 클릭하지않음.
- 이때 아이템을 클릭을 할 확률은 아래와 같은 기본 user preference에 CPR metric이 추가로 반영된 score를 계산한 뒤, softmax를 거친 categorical distribution을 따름
scoreitem=αuser∗⟨eu,ei⟩+αmetric∗m
pitem=esitem∑esitem
R=fclickorskip(pitem)
- 즉, 클릭을 많이 한다는것은 추천한 listwise action의 CPR이 높은것을 함축적으로 내포.
- 클릭을 할 경우와 skip을 할 경우 각각 1과 0의 reward를 반환.
- 이 user preference embedding과 item embedding은 user의 이전 step response (클릭 여부)를 반영하여 매 step마다 새롭게 업데이트.
- user preference vector와 action representation이 모두 주어지는 fully observable 조건.
- 추천한 아이템 리스트의 CPR은 아이템간의 카테고리 coherence가 높은 동시에 subcategory diversity가 클수록 증가한다고 볼 수 있으며, 이러한 추천을 하려면 샘플링되어 주어진 아이템 간의 관계를 reasoning할 수 있어야 함.
- CDQN을 사용하여 user session내에서 클릭수를 최대화.
5.3.1 Real-Data Recommender System
- LINE의 온라인 광고추천 서비스에서 2021년 8월 말 2주간 offline 데이터를 수집하고, 이를 학습하여 9월 초 2주간 offline 테스트를 진행함.
- user는 '지역/나이/직업'으로 representation되며, 아이템은 'text/이미지/보상포인트'를 feature로 포함.
- 학습 데이터는 68,775명의 user와 57개 아이템을 포함했으며, 테스트는 82,445명의 user와 58개의 아이템을 포함.
- reward function은 user의 클릭수와 추천리스트의 CPR값으로 구성.
- 학습엔 CDQN을 사용했으며 test reward로 평가.
6. Experiments
- 본 연구의 실험파트는 다음 5가지 의문에 대한 분석을 수행 하기위해 설계됨.
Varying action space 측면에서,
1) AGILE이 action을 독립적으로 다루거나 고정된 action set을 다루던 기존 접근보다 얼마나 효과적인가?
2) AGILE의 relational action representation이 action set summary나 action utility score의 계산에 있어서 얼마나 효과적인가?
3) AGILE의 attention이 action relation을 유의미하게 표현하는가?
4) AGILE의 GNN에서 attention이 필수적인가?
5) state-dependent action relation 은 general varying action space task문제를 푸는데 있어 중요한가?
6.1 Effectiveness of AGILE in Varying Action Spaces
- action을 독립적으로 다루거나 고정된 action set을 다루는 기존 알고리즘들을 baseline으로 AGILE을 평가하고자함.
- relational action feature와 summary의 효과를 평가하고자 이에 대한 ablation test를 수행함.
6.1.1 Baselines
- Mask-Output: 고정된 action space를 가정하고 불가능한 action과 관련된 Q-네트워크나 policy의 output은 masking.
- Mask-Input-Output: Mask-Output에 더해, 각 action이 활용가능한지 아닌지의 binary정보를 입력에 넣어줌
- Utility-Policy: action representation과 각 action에 대한 utility policy를사용하여 unseen action을 다루나, graph는 사용하지 않음.
- Simple DQN: 기본 DQN을 의미. action간의 상호관계를 고려하지않고 가장 높은 Q-value를 가지는 top k를 선택.

6.1.2 Ablations
- Summary-LSTM: relational action representation을 고려하지 않으며 summary도 GAT 대신 bi-LSTM을 사용.
- Summary-Deep Set: relational action representation을 고려하지 않으며 summary도 GAT 대신 deep set 아키텍처를 사용. (deep set에 대한 내용은 해당 논문 참조)
- Summary-GAT: GAT가 summary에만 사용되고 relational action representation은 고려되지 않는 경우.

6.1.3 Results
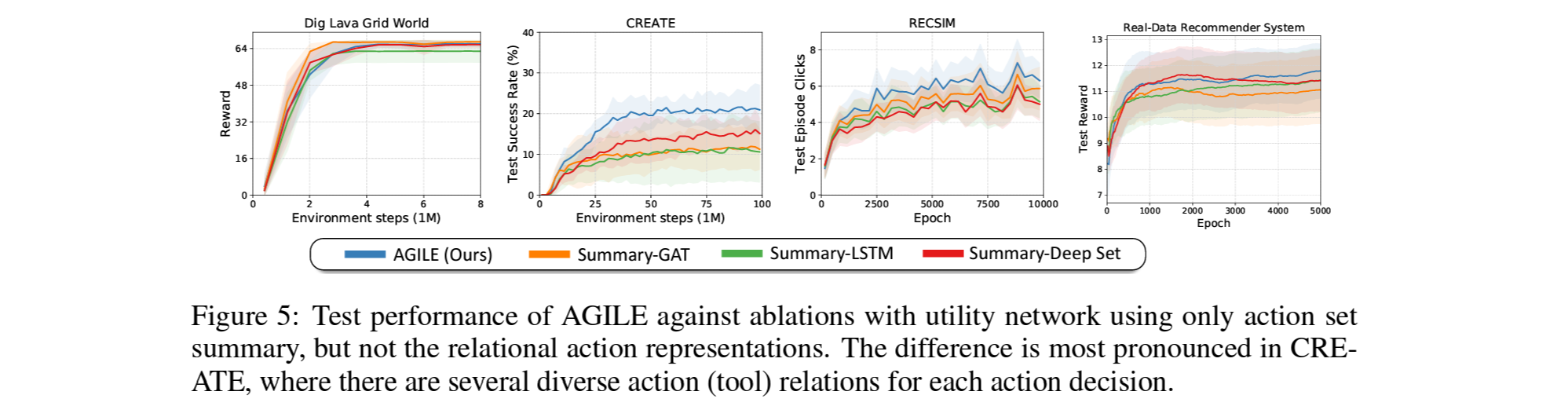
- Figure 4.는 baseline의 학습과정(위)과 unseen action이 포함된 테스팅(아래)에서의 결과.
- 모든 환경에서 AGILE이 명확히 더 나은 결과를 보여주었음. (Real-Data RecSys에선 눈에띄는 차이는 아님)
- 이로부터, varing action space에서는 활용 가능한 action의 존재와 그 관계를 아는것이 optimal action을 찾는데 매우 중요함을 확인.

- Figure 5.는 relation은 고려하지 않고 주어진 활용가능한 action들의 정보 (action summary) 만 고려한 ablation의 test 결과.
- action의 갯수가 적고 관계성이 단순한 Dig Lava Grid에선 큰 차이가 없음.
- Recsys에서는 보편적인 아이템을 추천하면 CPR이 높아질 확률이 큰데, action summary만으로도 보편적인 아이템의 을 찾는게 가능하여 관계성 정보까지 사용하는 AGILE대비 큰 차이는 아닌 5-20%의 성능 상승을 보여줌.
- 반면 CREATE는 기구와 동력원 사이의 관계성이 매우 복잡하고 범위가 넓어서, summary만으론 이 관계를 파악하기가 어려워 여러 환경 중 AGILE이 가장 큰 성능 차이를 보임.
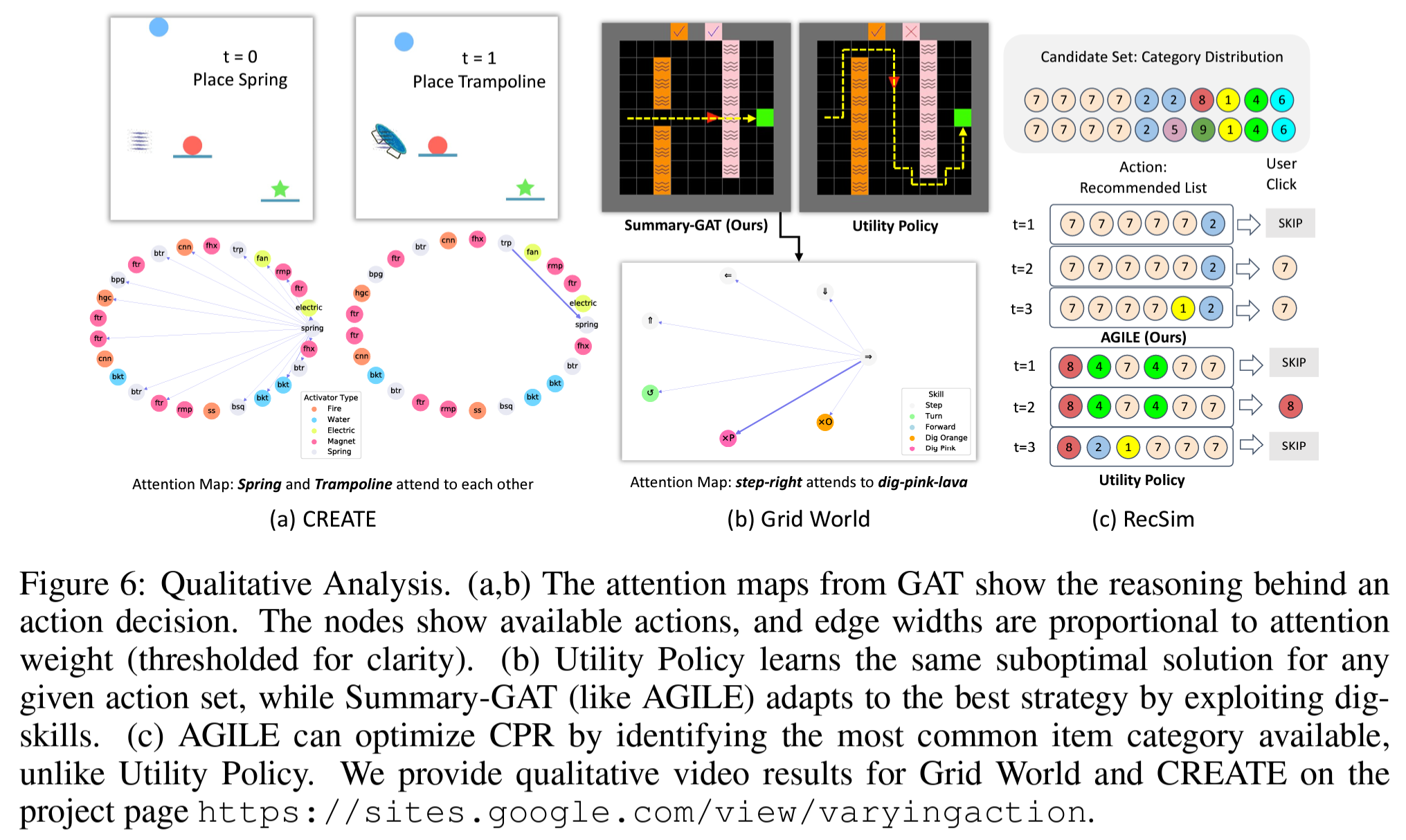
6.2 Does the Attention in AGILE Learn Meaningful Action Relations?
- Figure 6.은 학습된 agent의 퍼포먼스를 좀더 정성적으로 분석해본 결과.
- (a)는 CREATE에서의 attention map으로 spring을 선택한 후엔 trampoline에 대한 attention이 매우 강해지는것을 확인할 수 있음.
- (b)는 Grid World에서의 Suumary-GAT의 attention map으로, 오른쪽으로 가는 action과 분홍색 용암을 퍼내는 action사이에 attention이 매우 높은것을 확인 할 수 있음.
- (c)는 RecSim에서의 user와의 interaction으로, AGILE이 추천하는 아이템들은 6개 중에 5개를 동일한 가장 보편적인 카테고리인 7을 선택하여 CPR을 최대화 하는것을 확인 가능 함.
6.3 Additional Analysis
6.3.1 Importance of Attention in the Graph Network
- Figure 7.에서는 AGILE의 GAT를 또다른 GNN아키텍처인 graph convolutional network (GCN)으로 바꿨을때의 결과를 비교함.
- 앞서 살펴본 바와 같이 action간의 관계가 단순한 환경인 Grid World와 RecSys에서 GCN은 optimal 성능을 보여주는것을 확인.
- action간의 관계가 복잡한 CREATE에서는 GAT를 사용한것 대비 크게 성능이 떨어지는것을 확인 함.
- RecSym에서도 추가적으로 item간의 pair를 만들어 이를 맞출때만 클릭이 되도록 환경의 action관계성의 복잡도를 올릴 경우, GAT를 쓰는것이 GCN을 쓰는것보다 더 나은 성능을 보여주는것을 확인 함.
- 저자들은 이에 대해, GAT가 graph를 더 sparse하게 만들어 RL알고리즘의 학습을 쉽게 하는것이며 fully-connected GCN은 이러한 것이 어려울것이라 가정.


6.3.2 Importance of State-Dependent Learning of Action Relations
- AGILE-Only Action: GAT에서 state를 action과 concat하여 새로운 action representation을 만들지않고 action만 사용한 경우.
- Figure 7.에서는 AGILE-Only Action의 학습결과도 함께 비교함.
- Grid World와 CREATE와 같이 state에따라 action의 관계성이 달라지는 환경에서는 state를 concat하지 않을경우 성능이 떨어지는것을 확인함.
- 반면 CPR이 user의 state와는 독립적으로 가장 일반적인 category를 아는것만을 필요로 하므로 RecSim에서는 state-dependence의 영향이 적은것을 확인함.

7. Conclusion
- varying action space RL문제에서 action간의 관계성을 활용가능한 AGILE아키텍처를 제안.
- AGILE은 GAT를 사용하여 action들 사이의 상호의존성을 학습하는것이 가능함을, real-data 추천시스템을 포함한 4개 환경에서 검증 및 확인함.









