
Author: Mary Phuong, Marcus Hutter
Paper Link: https://arxiv.org/abs/2207.09238
- 요약예정
Author: Mary Phuong, Marcus Hutter
Paper Link: https://arxiv.org/abs/2207.09238
- 요약예정

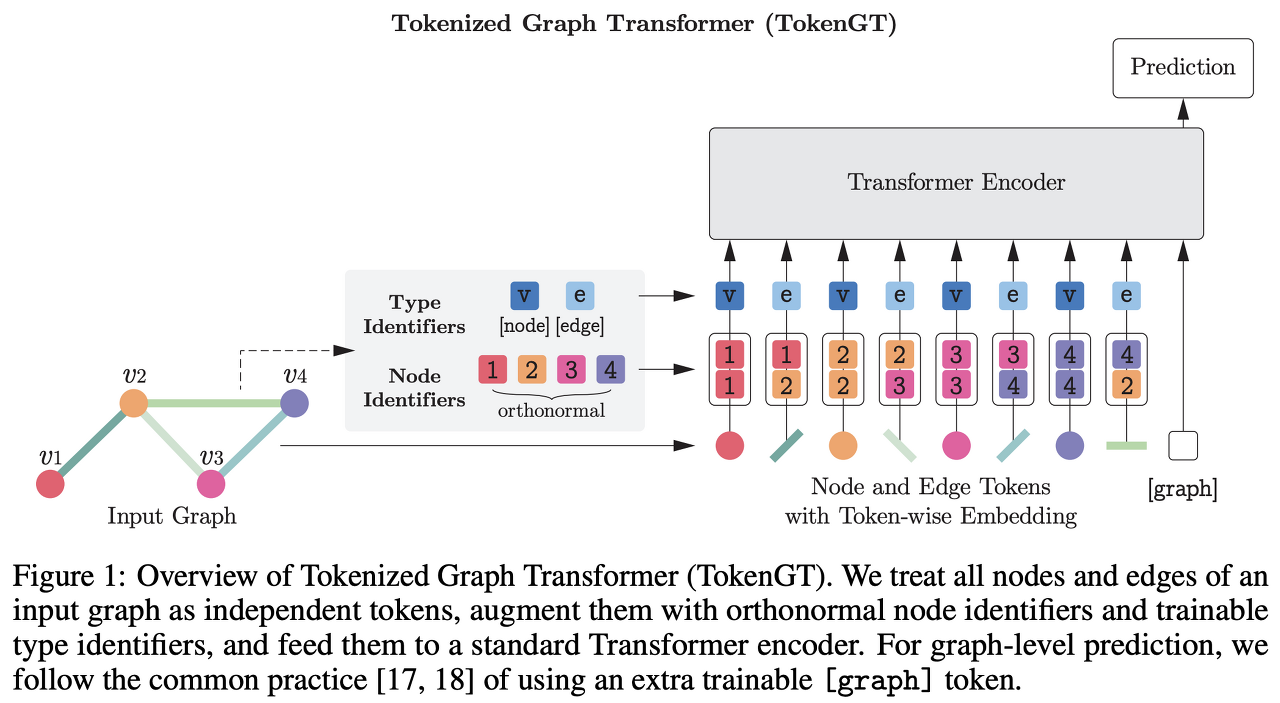
Author: Jinwoo Kim, Tien Dat Nguyen, Seonwoo Min, Sungjun Cho, Moontae Lee, Honglak Lee, Seunghoon Hong
Paper Link: https://arxiv.org/abs/2207.02505
Code: https://github.com/jw9730/tokengt


Author: Kuang-Huei Lee, Ofir Nachum, Mengjiao Yang, Lisa Lee, Daniel Freeman, Winnie Xu, Sergio Guadarrama, Ian Fischer, Eric Jang, Henryk Michalewski, Igor Mordatch
Paper Link: https://arxiv.org/abs/2205.15241
Website: https://sites.google.com/view/multi-game-transformers
Code: yet




How do different online and offline methods perform in the multi-game regime?

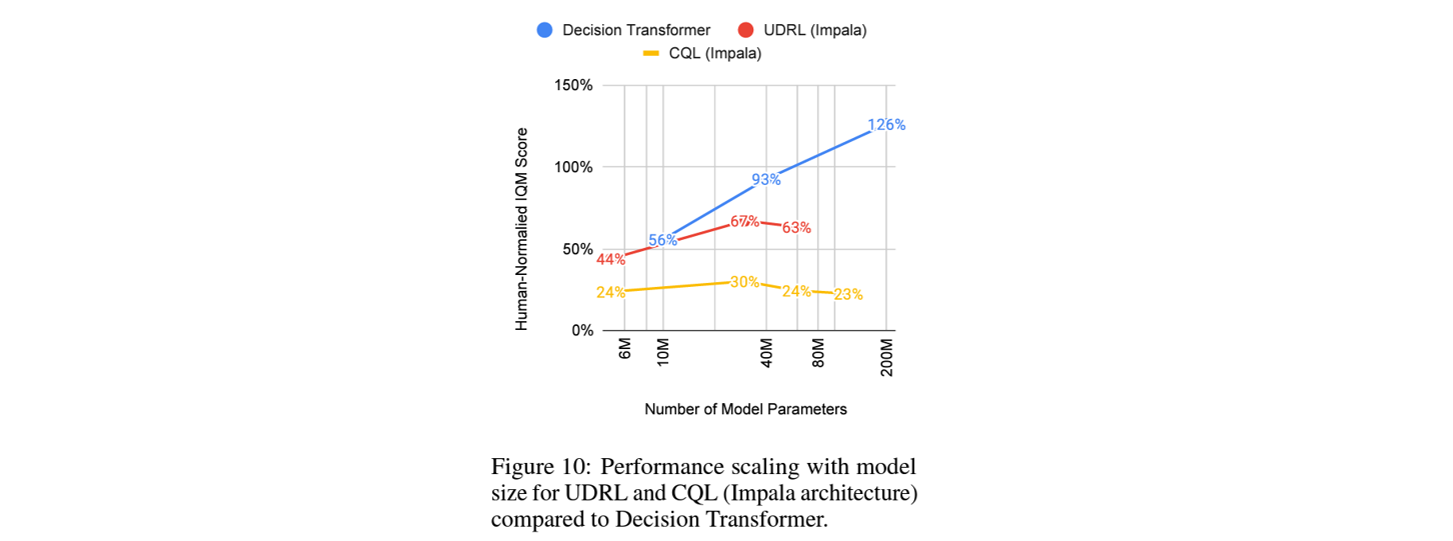
How do different methods scale with model size?
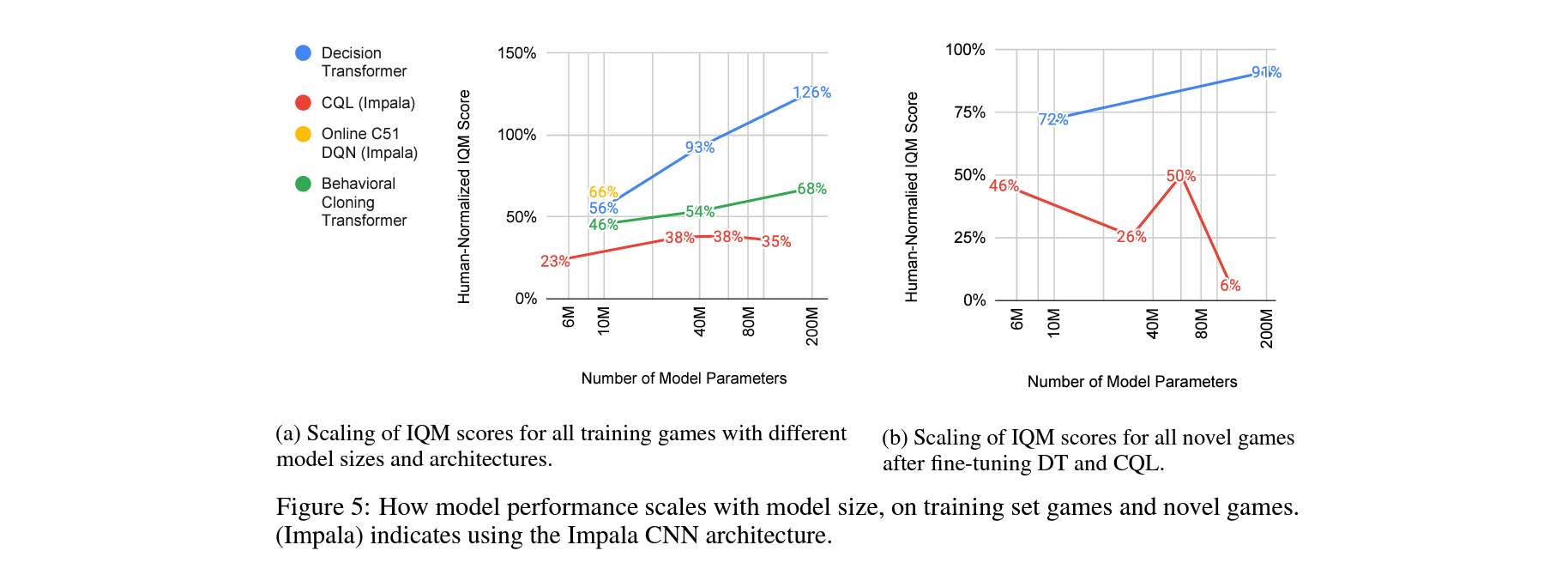
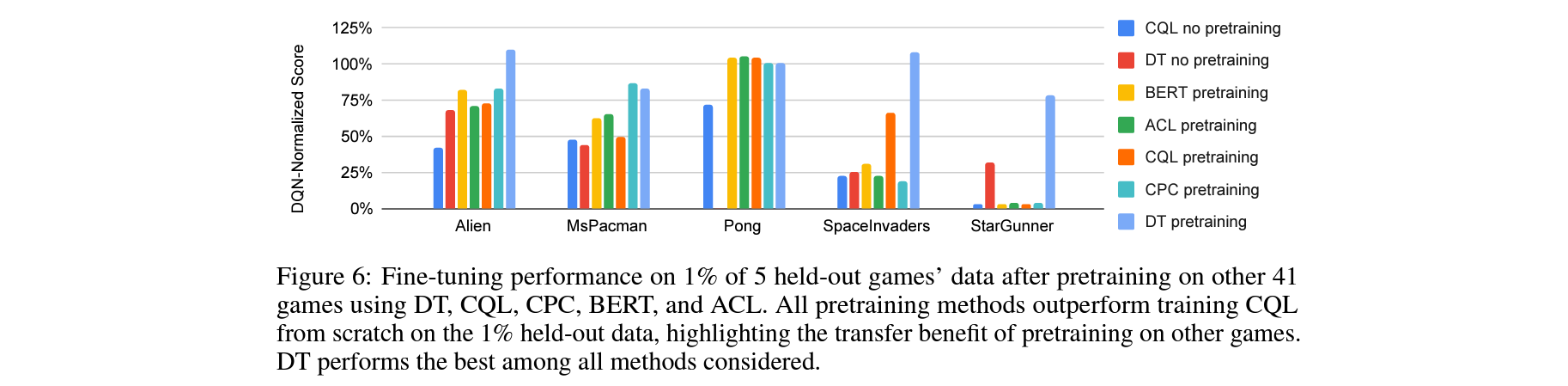
How effective are different methods at transfer to novel games?
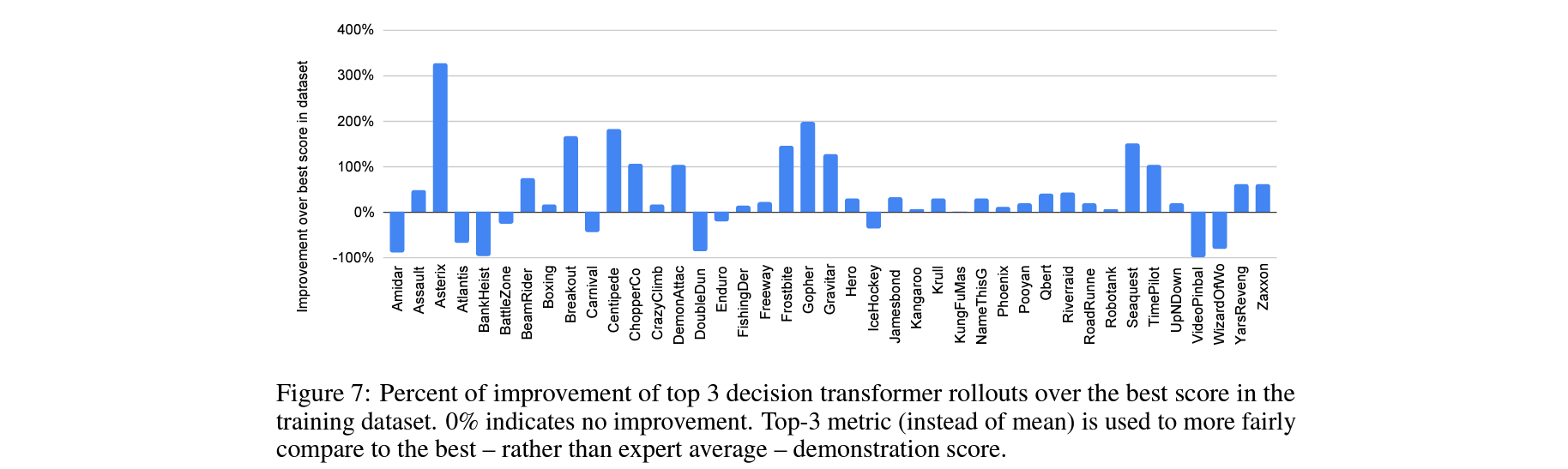
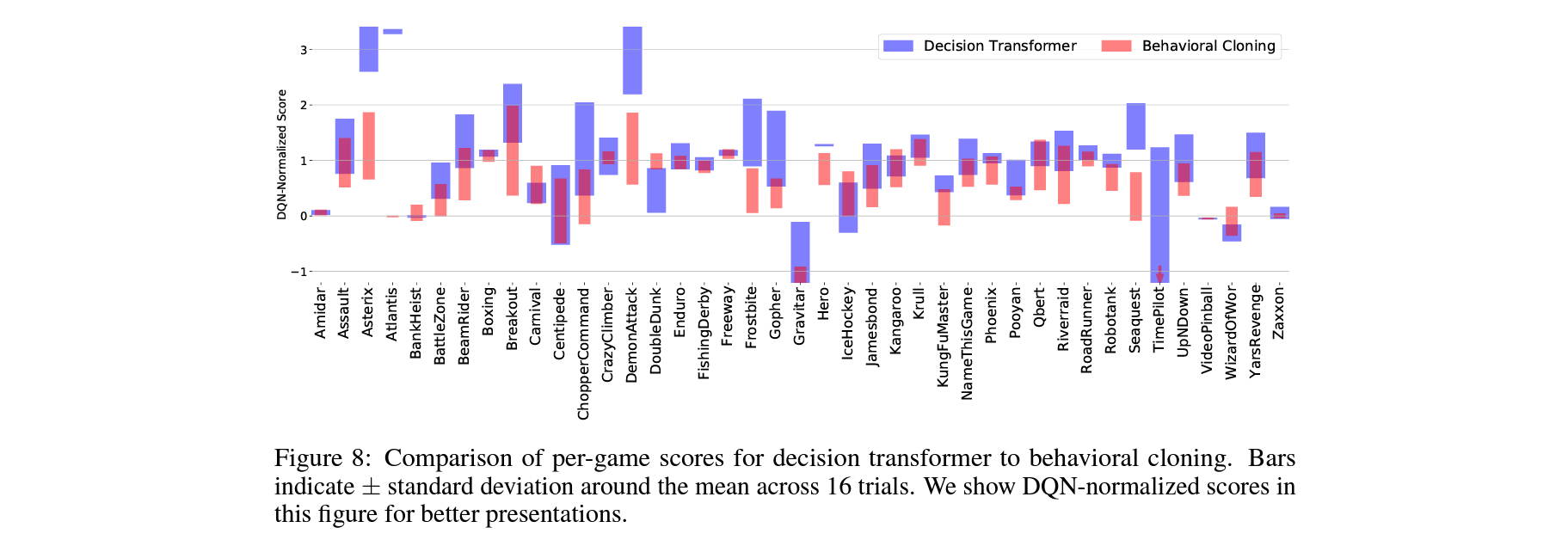
Does Multi-Game Decision Transformer improve upon training data?
Does expert action inference improve upon behavioral cloning?
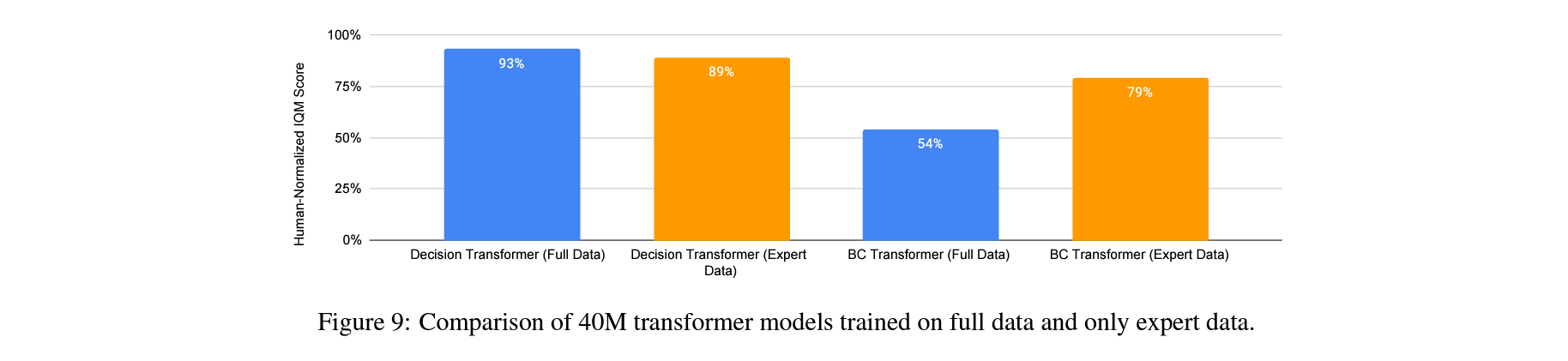
Does training on expert and non-expert data bring benefits over expert-only training?
Are there benefits to specifically using transformer architecture?
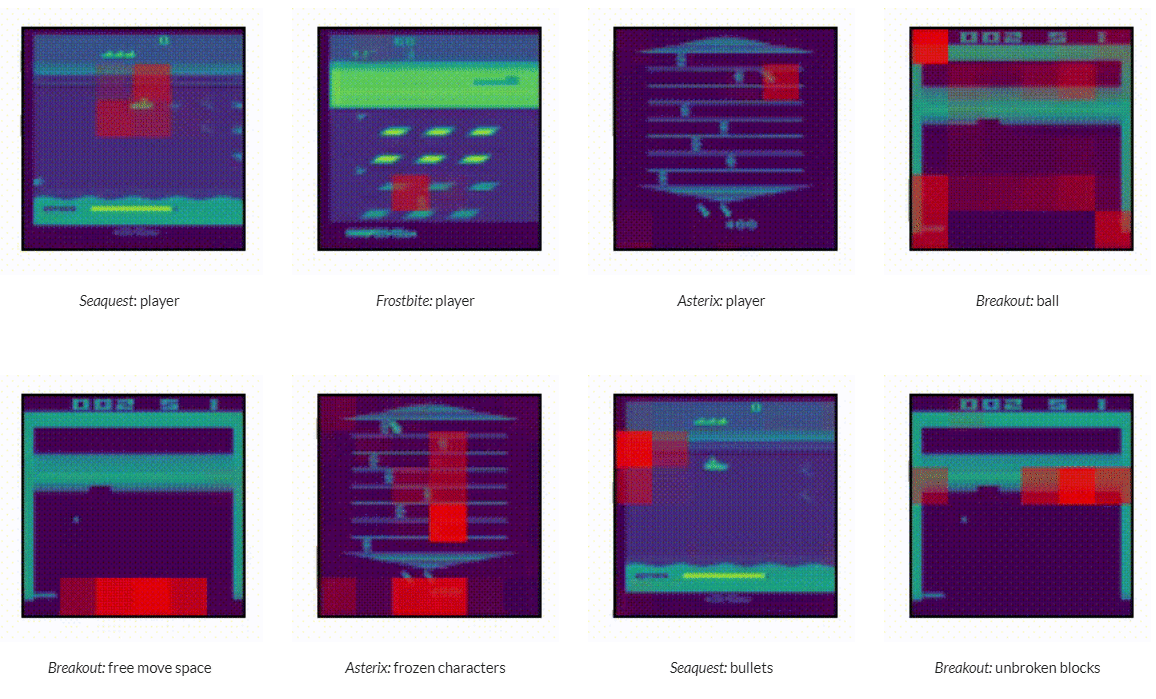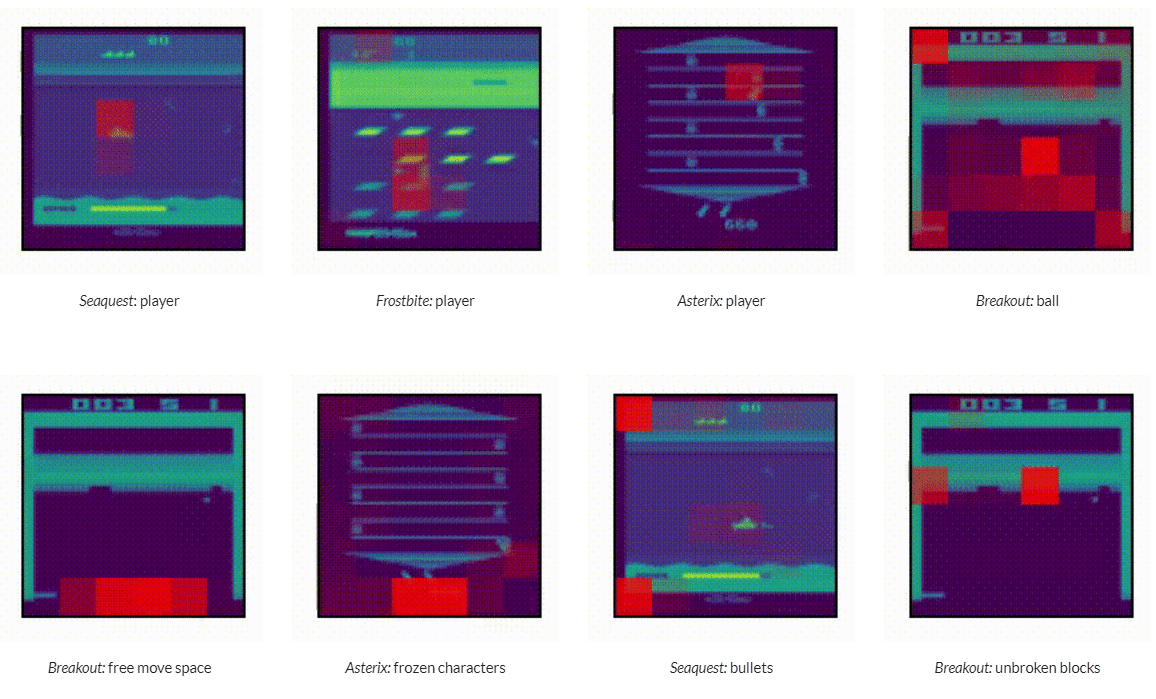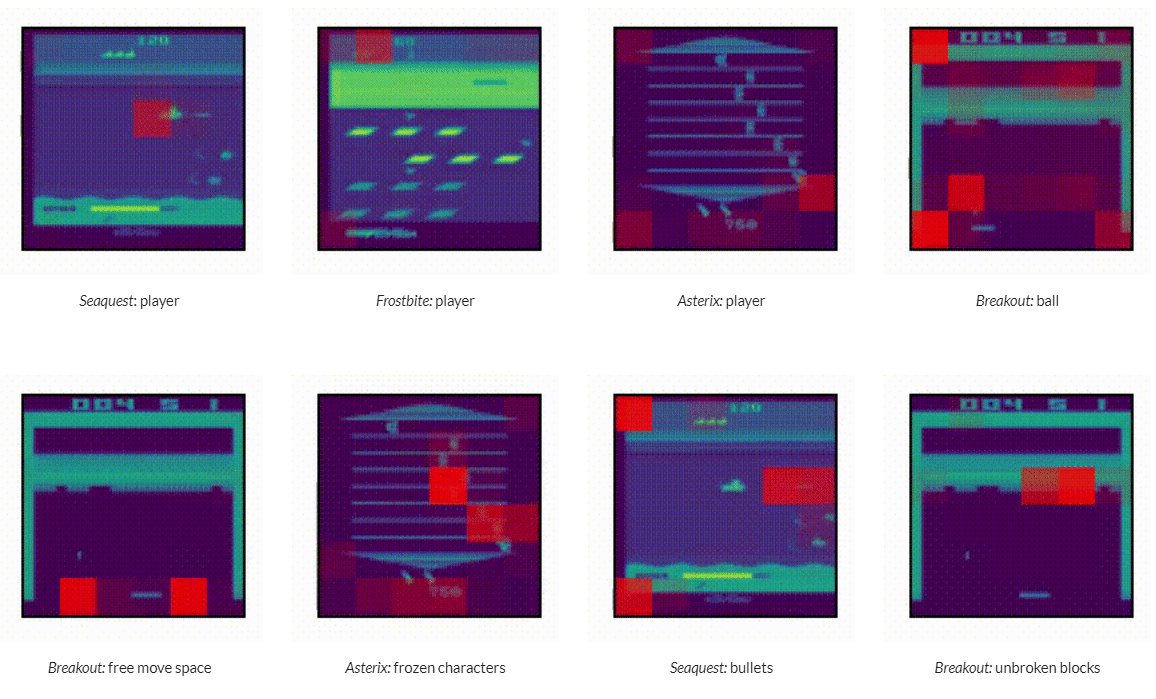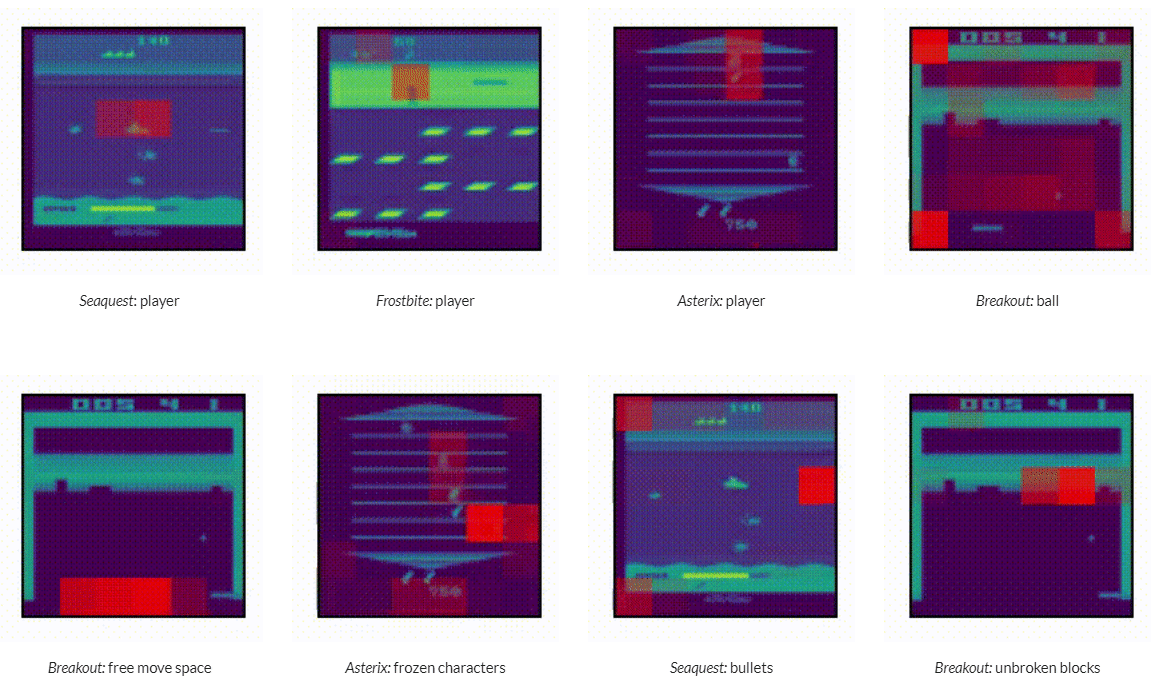
What does Multi-Game Decision Transformer attend to?

Author: Michael Janner, Yilun Du, Joshua B. Tenenbaum, Sergey Levine
Paper Link: https://arxiv.org/abs/2205.09991

Author: Tsung-Yen Yang, Tingnan Zhang, Linda Luu, Sehoon Ha, Jie Tan, Wenhao Yu
Paper Link: https://arxiv.org/abs/2203.02638
Site: https://sites.google.com/view/saferlleggedlocomotion/
Google AI Blog: https://ai.googleblog.com/2022/05/learning-locomotion-skills-safely-in.html