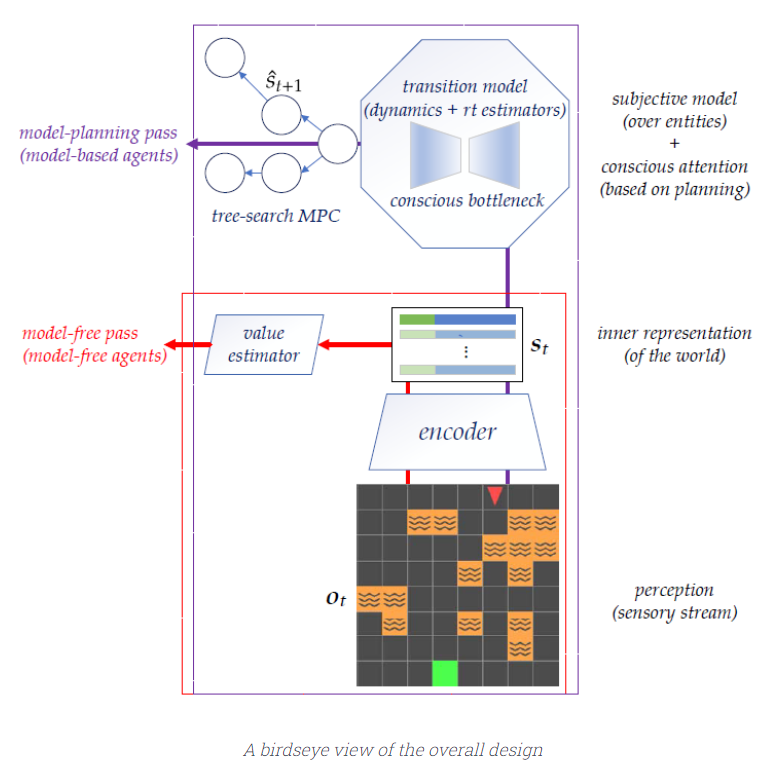
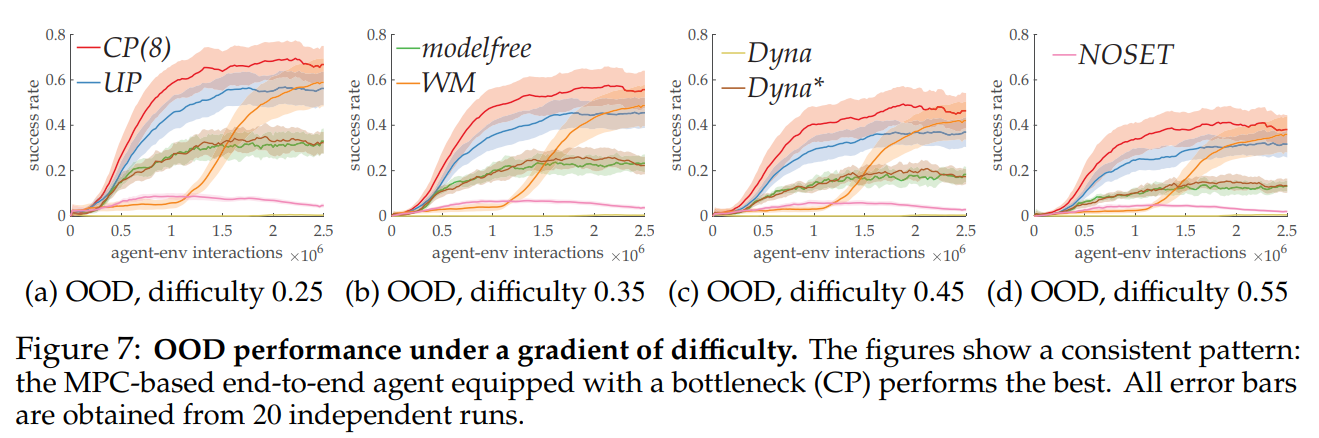
Author : Pedro A. Ortega, Markus Kunesch, Grégoire Delétang, Tim Genewein, Jordi Grau Moya, Joel Veness, Jonas Buchli, Jonas Degrave, Bilal Piot, Julien Perolat, Tom Everitt, Corentin Tallec, Emilio Parisotto, Tom Erez, Yutian Chen, Scott Reed, Marcus Hutter, Nando de Freitas, Shane Legg Paper Link : https://arxiv.org/abs/2110.10819
Sequential interaction에 대한 모델을 만들 땐, 단순 prediction loss만으론 self-delusion이 생기는 문제에 대한 DeepMind의 article.
Delusion 문제를 다루기 위해 sequential 모델의 observation 분포와 action분포는 분리하여 학습해야하며, action의 probability에 대해선 intervention을 모델링하는 'counterfactual teaching'을 해야 delusion을 해소할 수 있다고 설명.
이 sequential 모델은 $\mathrm{RL}^2$와 같은 memory-based meta learning으로 학습이 가능함.
하지만 중요한 점은 위 설명은 online interaction이 가능한 경우에 대한것이고, offline learning의 경우 아직 open problem임을 설명.
개인적인 생각
주 저자들이 Deepmind Safety Analysis이다.
익히 알려진'causal inference' 문제를 foundation model을 지향하는 관점에서 officially 정리해주었다.
Offline learning에선 unobserved confounder가 있을 땐, observation 또한 단순 'factual teaching'기반의 prediction 문제로 학습할 경우 selection bias에 의한 delusion이 생기므로 주의해야한다.
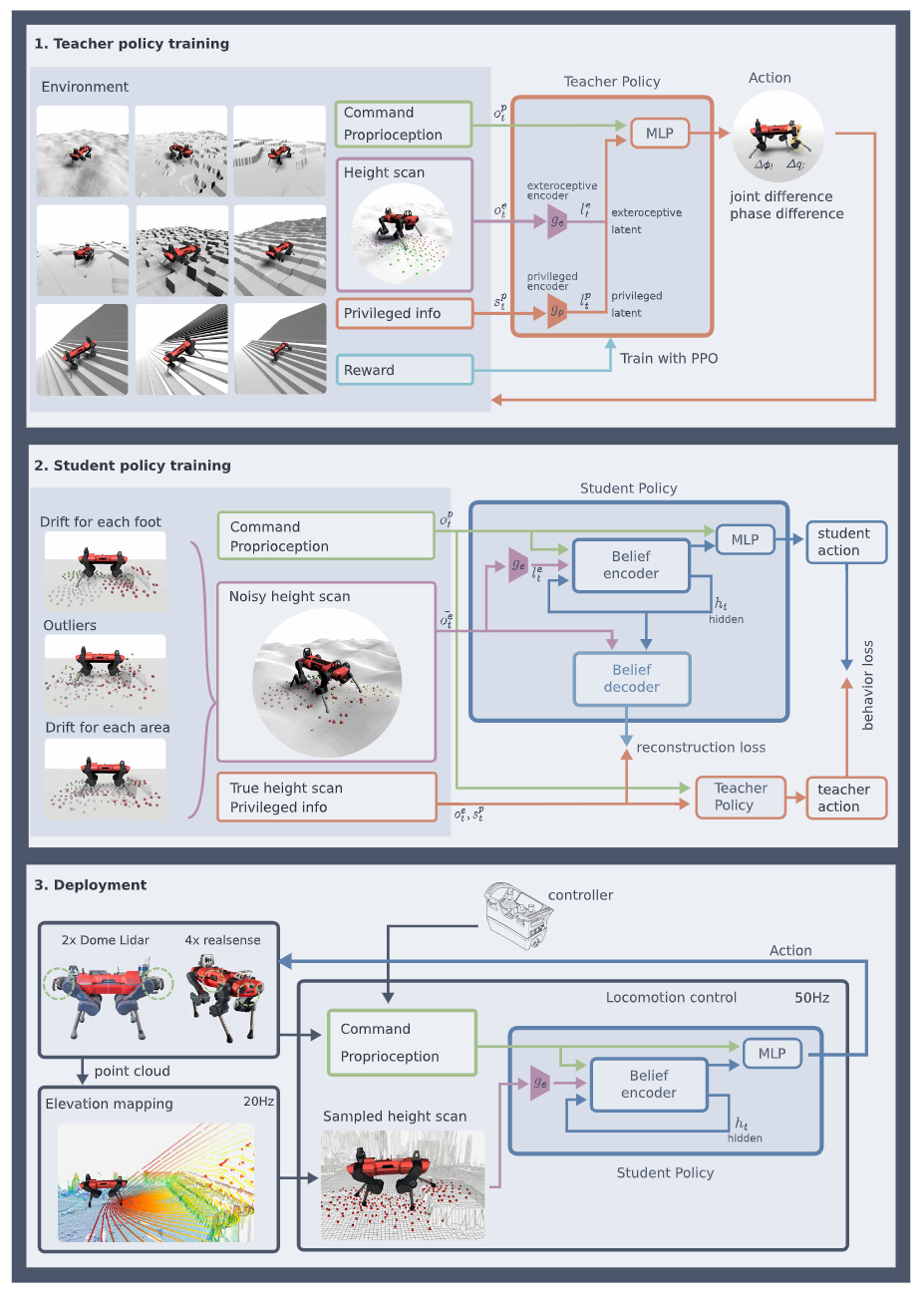
3 단계에 걸쳐 zero-shot sim-to-real transfer learning을 구성
Step1: Teacher policy training - 랜덤하게 생성된 지형에서 명령으로 준 랜덤 target velocity와의 차이를 reward로 PPO알고리즘에 주어 학습 - Teacher policy의 입력으로는 1. 속도 command, 2. proprioception센서 정보, 3. exteroception 센서 정보 4. previleged 정보 (ex. 마찰력과 같은 환경의 true dynamics) - 시뮬레이션을 활용하여 이상적인 정보를 줌으로써, RL알고리즘이 충분히 optimal에 가까운 policy를 학습하도록 유도
Step2: Student policy training - Student policy의 입력으로는 1. 속도 command, 2. proprioception센서 정보, 3. 노이즈가 들어간 exteroception 센서 정보 - 충분하지 못한 정보에서 scratch로 좋은 RL policy를 학습하기보다, 이미 학습한 좋은 tearch policy를 supervised learning으로 distill하여 효율적으로 학습; privileged learning - Prorioception정보와 extroception정보로부터 unobervable state에대한 belief를 추론하기위해 recurrent belief state encoder를 제안 - Belief encoder가 좋은 latent space를 학습하도록 하기위해, previleged 정보와 true exteoception정보에 대한 reconstruction loss를 사용
Step3: Deployment - 실제 로봇에 학습한 student policy를 decoder를 제외하고 deploy - Context based meta-RL인 만큼 fine tunning이나 optimization 없이 실시간으로 real-world에 adaptation가능
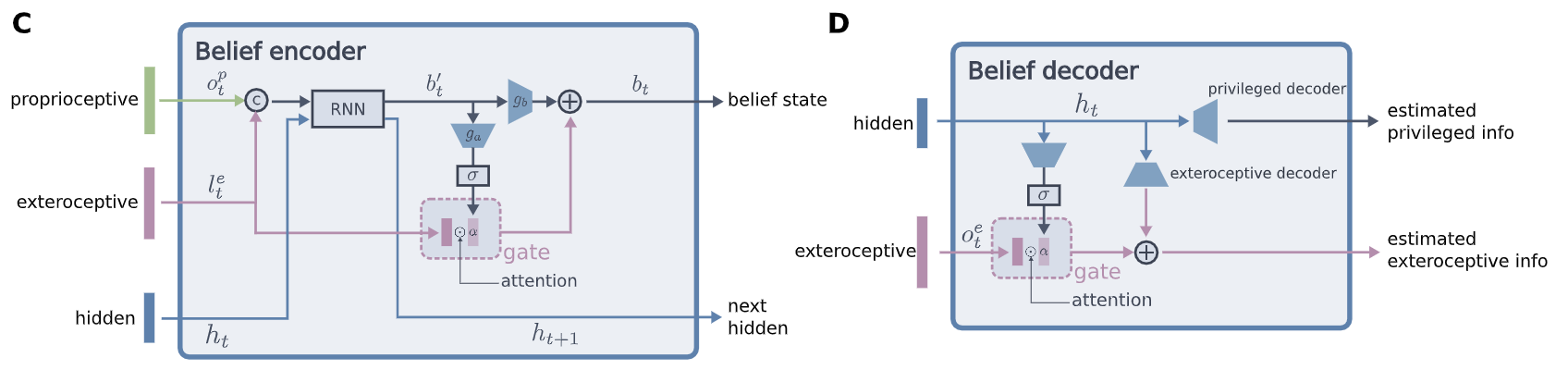
Exteroception정보는 경우에 따라 틀리거나 얻지못할 수 있으므로, 필요에 따라 exteroception정보에서 의미있는 정보를 선별하여 쓰기위하여 attention gate를 사용한 gated encoder 적용
Attention gate는 최종 belief state에 어느정도의 exteroception정보를 담을지를 조절
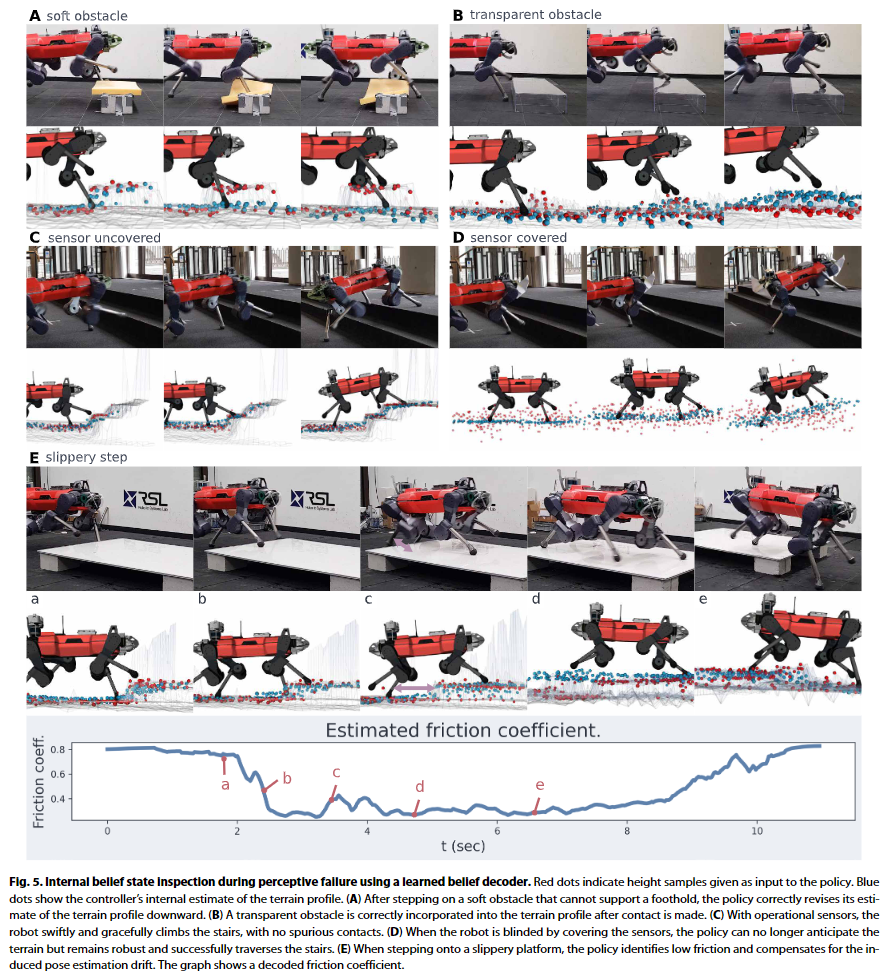
Autoencoder를 사용하여 representation learning을 한 만큼, decoder를 사용하여 internal belief를 시각화 가능
아래 그림에서 빨간 점은 policy에 입력으로 들어가는 실제 지면높이 정보 파란 점은 decoder에 의해 복원된 지면높이에대한 agent의 belief
A) 스펀지 장애물을 밟기전엔 지면 높이가 높다고 생각하고 있다가, 스펀지를 밟자으면서 들어오는 시계열의 푹신한 반응정보로부터 encoder는 실시간으로 평평한 지면 인것으로 belief가 변경
B) 투명한 장애물을 exteroception 센서가 인식못해 평평한 지면이라고 생각하다가, 상자를 밟는 순간 지면의 높이가 있는것으로 belief가 변경
D) 센서가 완전히 가려진 상태에서도 지면이 경사졌다고 판단다는 belief가 형성되며, 이는 사람이 걸으며 주변환경이 어두워질 경우 시각에서 체성감각으로 주의를 옮겨 지형지물을 판단하는것과 유사
E) 미끄러운 지면의 장애물을 걸을경우, 미끄러지는 만큼의 연장된 너비의 지면에 대한 belief가 형성하는 동시에 마찰의 변화 역시 추정
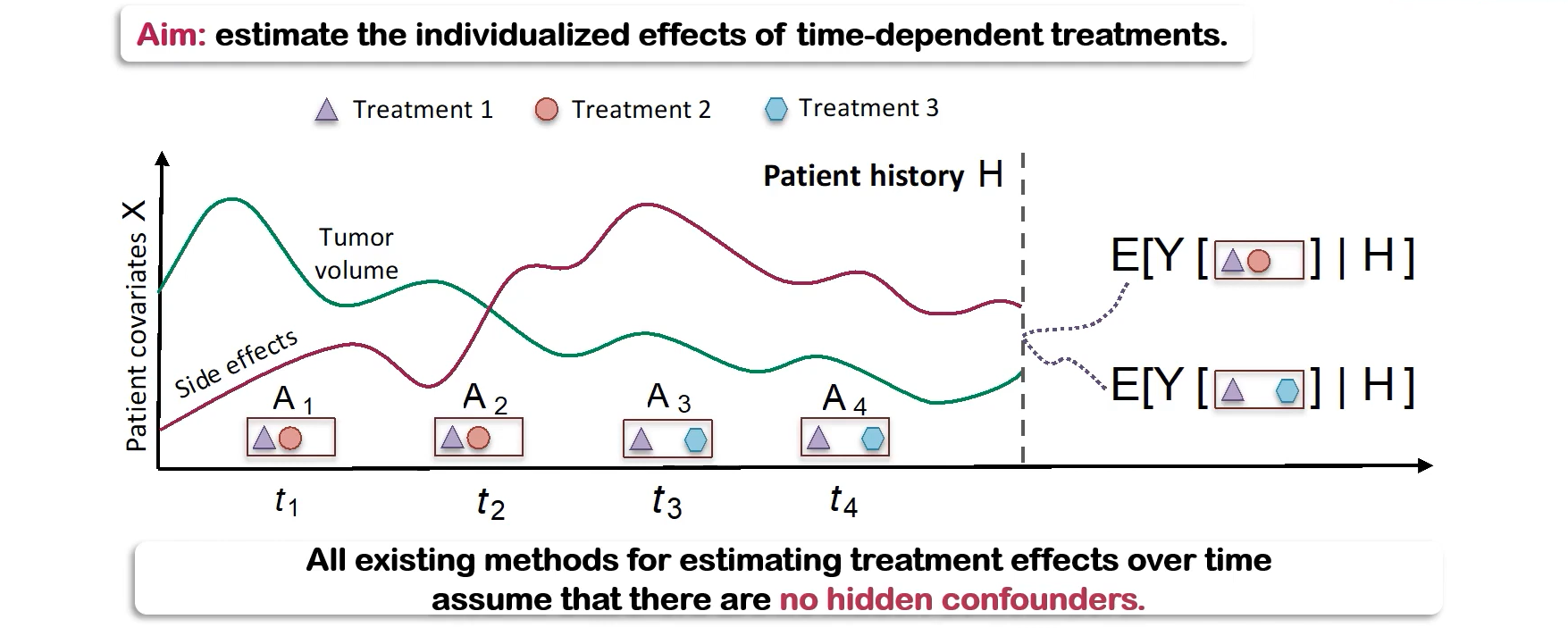
의료분야에서 treatment effect를 추론하는것은 중요하지만, 지금까지의 추론 방법들은 모두 'no hidden confounder'라는 비현실적이고 결과적으로 추론에 bias를 야기하는 가정을 전제로 함.
본 연구에서는 시간에 따른 다중 치료 환경에서 multi-cause hidden confounder가 존재할때의 treatment effect를 추론하기위한 Time Series Deconfounder를 제안함.
Time series Decounfounder는 multitask output의 RNN을 factor model로 사용하여 multi-cause unobserved confounder를 대체하는 latent variable을 추론하고 이를통해 casual inference를 수행함.
이론적 분석과 함께 시뮬레이션 및 실제 MIMIC III데이터를 사용하여 알고리즘의 효과성을 검증함.
1. Introduction
연속적으로 처방된 치료에 따른 환자 개인의 치료 효과를 예측하는것은 매우 중요한 문제임.
최근 이러한 정보를 담고있는 observational 데이터 역시 빠르게 증가하고 있음.
하지만 기존의 방법들은 모든 confounder가 관측가능하다는 대체로 비현실적인 상황을 가정하고있어 예측에 bias가 생김.
예를들어 암의 진행에대한 항암제의 효과를 예측할 때 환자의 약에대한 내성형성이나 누적되는 독성을 고려하지 않는것은 예측결과에 bias를 초래.
하지만 내성이나 독성은 관측이 어렵고 관측이 되더라고 후향적인 EHR과 같은 후향적인 관측데이터에는 기록되어있지 않은 경우가 대부분.
본 연구에선 Wang & Blei (2019a)의 연구에서 고안된 'static 셋팅에서의 multiple treatment를 활용하여 hidden confounder를 deconfounding하는 방법'을 개선하여 longitudinal 셋팅에서의 time-varying hidden confounder를 deconfounding하는 Time Series Deconfounder를 제안함.
시계열 환경에서 unobserved confounder의 대체재로서 letent variable을 학습하는 첫번째 시도.
2. Related Work
시간에 따라 변하는 치료에 대한 Potential outcomes - 지금까지 시계열 데이터에 대한 counterfacutal inference로는 G-formula, G-estimation, MSM, R-MSN, balaced representation 등이 있었지만 모두 hidden confounder가 없다고 가정. - 연속성 데이터에대한 treatment effect 연구들도 있어왔으나 여기선 이산 환경을 다룸. - Unmeasured confounder에 대한 potential impact를 평가하기위한 sensitivity anlysis방법들도 고안되어옴.
Hidden confounder 추론을 위한 latent variable 모델 - Multi-cause 환경에서 hidden confounder를 추론가능한 latent variable로 대체하고 추론된 latent variable로 causal inference를 수행하는식의 deconfounder 접근은 Wang & Blei (2019a, link)에서 제안된 바 있음. - 해당 논문은 static treatment 문제를 다루고 있으나, 본 논문은 이와 달리 time-varying treatment문제를 다루기 위해 RNN을 factor model로 사용하는 deconfounder 구조를 제안함.
3. Problem Formulation
$\mathbf{X}_{t}^{(i)} \in \mathcal{X}_{t}$: random variable, (환자 $i$에 대한; 이후 생략) time-dependent covariates
$\mathbf{A}_{t}^{(i)}=\left[A_{t1}^{(i)}{\cdots}A_{tk}^{(i)}\right]\in\mathcal{A}_{t}$: 시간 $t$에서의 가능한 $k$가지 treatments
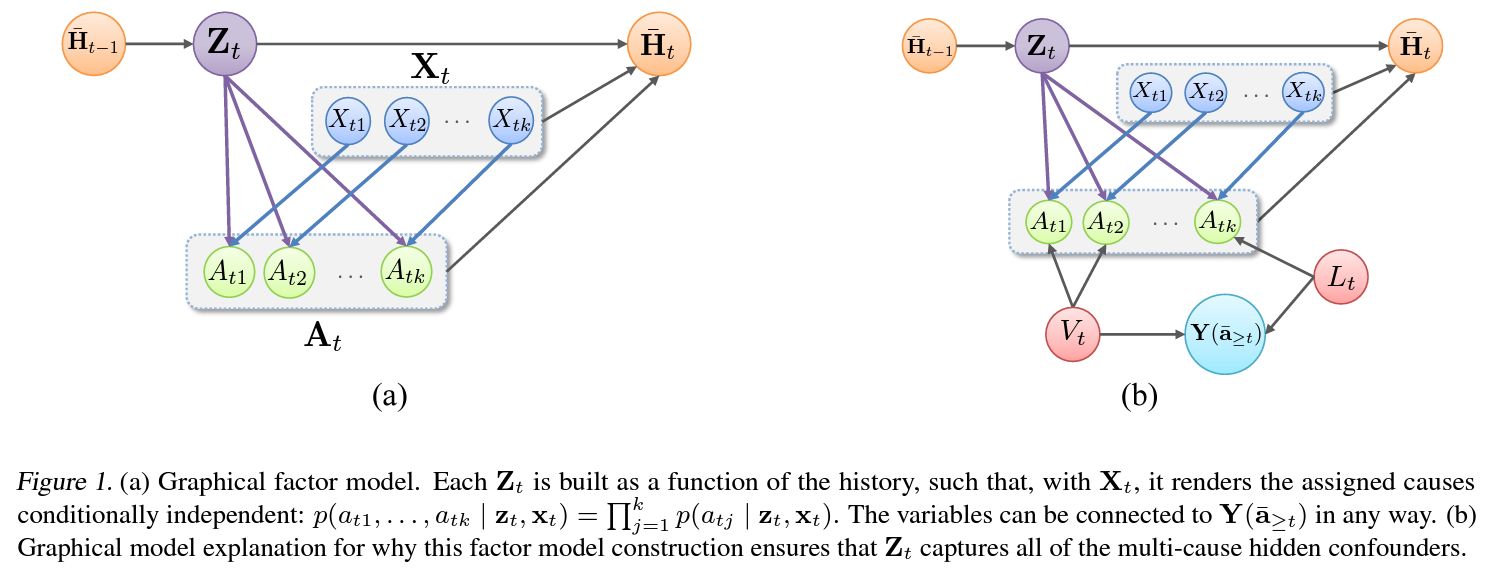
대신 Wang & Blei (2019a)의 접근을 확장하여 시간에 따른 다중 treatments를 활용한 sequencial latent variable $\overline{\mathbf{Z}}_t=(\mathbf{Z}_1,\cdots,\mathbf{Z}_t)\in\overline{\mathcal{Z}}_t$ 을 추론하고 관측되지 않은 confounders로서 대체하고자 함.
4. Time Serise Deconfounder
본 연구에서 제안하는 Time Series Deconfounder의 본질적인 아이디어는 multi-cause confounder로 인한 treatment들 사이의 종속성이 있다는것.
이 종속성을 활용하여 시간에 따라 바뀌는 treatment로 부터 hidden confounder를 추론함.
4.1. Factor Model
Time Series Deconfounder는 시간 $t$이전까지의 history $\overline{\mathbf{h}}_{t-1}$로부터 시간 $t$에서의 unobserved confounder를 대체할 letent variable $z_t$을 추론하는 factor model $g$을 가짐.
물론 이 가정 역시 여전히 테스트가 불가능하지만, 관측가능한 treatment의 갯수가 증가함에 따라 hidden confounder가 하나의 treatment에만 영향을 줄 가능성은 급격히 줄어듬.
Wang & Blei (2019a)에 따르면 $\mathbf{Z}_t$의 차원이 treatments의 갯수보다 작을경우 가정2. Positivity또한 실질적으로 만족가능.
Fitting된 factor model이 얼마나 정확하게 validation set 환자의 treatment분포를 예측하는지를 평가하기위해 predictive check로서 각 시간 $t$에서 $M$개의 예측 샘플과 실제treatment 사이의 $p$-value를 아래와 같이 계산.
Time Series Deconfounder의 uncertainty는 factor model에서 시간에 따라 샘플된 sequential latent variable $\hat{\bar{\mathbf{Z}}}_t=(\hat{\mathbf{Z}}_1,\cdots,\hat{\mathbf{Z}}_t)$ 을 다시 반복 샘플하여 구한 각각의 outcome들의 variance로 판단함.
만약 treatment effect가 부정확하여 non-identifiable할 경우엔 이 variance가 커짐.
또한 본 연구에서 제안하는 hidden confounder문제를 다루기 위해 latent variable를 추론하는 접근은 treatment effect의 bias를 명백히 낮추지만, Wang & Blei (2019a)에 따르면 hidden confounder가 없는 상황에선 기존 방법 대비 variance가 상대적으로 커져 free lunch는 아님.
5. Factor Model over Time in Practice
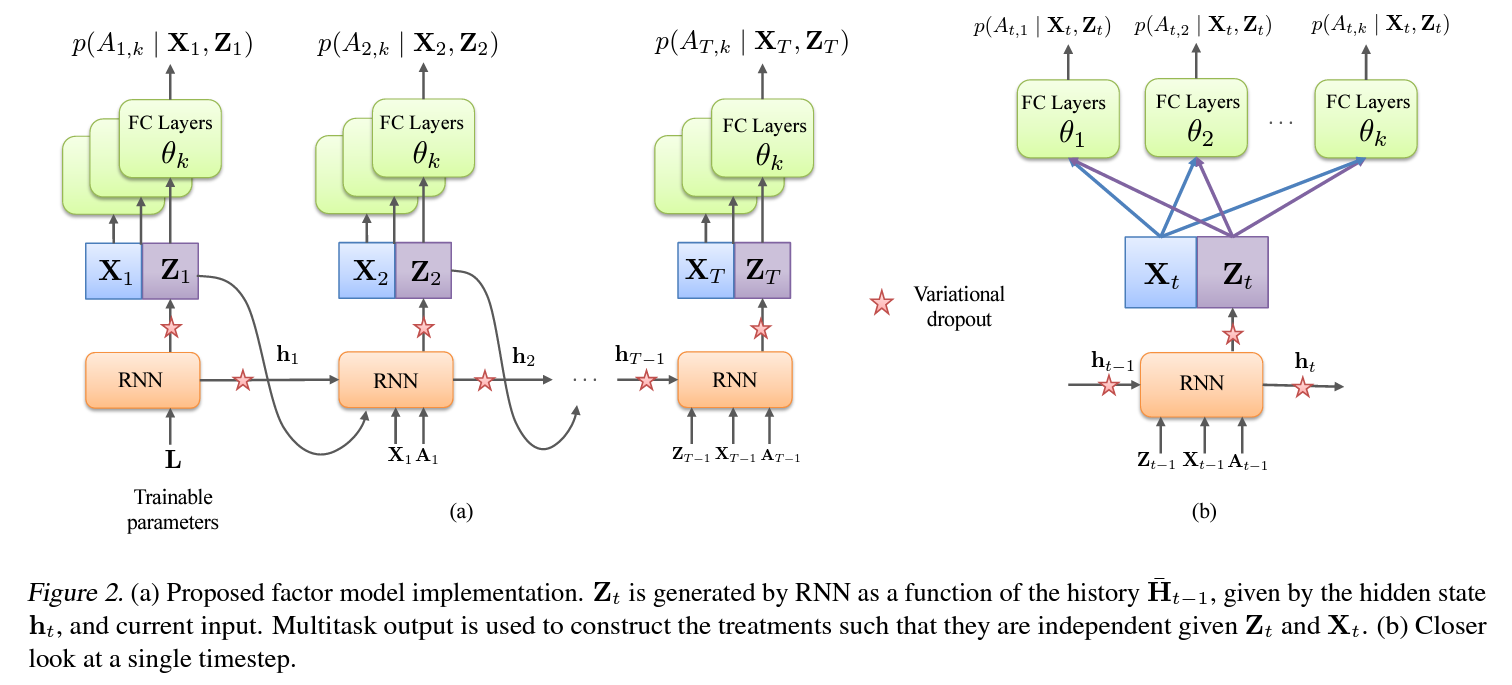
시계열 문제를 다루고 있으므로 기존의 PCA나 Deep Exponential Families을 사용하는 대신 아래 그림과 같이 RNN, 여기서는 특히 LSTM을 factor model로서 사용함.
즉, RNN을 사용하여 환자의 시간 $t$까지의 history로 부터 시간 $t$에서의 latent variable을 추론.
Factor model의 확률적인 특징을 구현하기위해서 위 그림의 별이 그려진 부분에 $variational\,dropout$(GAL & Ghahramani, 2016a)을 사용하였고, 이에 따른 latent variable의 샘플링이 가능해짐.
위와 같은 구현으로 RNN으로 하여금 $\overline{\mathbf{X}}_t$, $\overline{\mathbf{Z}}_t$ 및 $\overline{\mathbf{A}}_t$사이의 복잡환 관계를 학습도록 할 수 있지만, 이 과정에서 predictive check가 반드시 필요하다는것에 주의.
6. Experiments on Synthetic Data
제안한 Time Series Deconfounder를 검증하고자 합성데이터를 사용함.
실제 데이터를 사용한 검증은 hidden confounder를 알 수 없으므로 불가능.
6.1. Simulated Dataset
5000명의 환자에 대한 20~30 스텝의 가상데이터를 treatments, covariates, hidden confounders가 서로 영향을 미치는 $p$-order autoregressive 과정으로 생성함 (자세한 수식은 논문 참조).
그리고 outcome은 covariates와 hidden confounder의 함수가 되도록 생성.
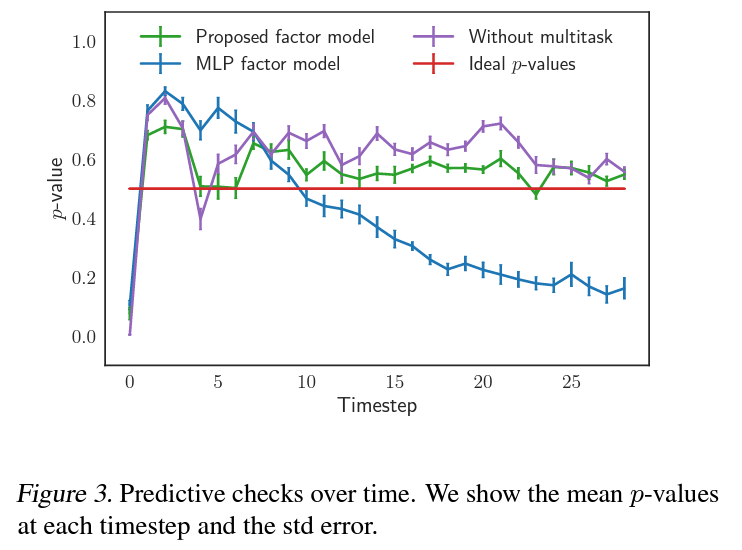
6.2. Evaluating Factor Model using Predictive Checks
제안한 factor model 아키텍처가 treatment의 분포를 잘 학습하는지 확인하고자 합성데이터에 대해 아래 세 가지 모델의 predictive check를 수행함. 1. 제안한 factor model; RNN + Multitask FC output (초록) 2. RNN대신 MLP를 사용한 factor model (파랑) 3. Multitask FC layer대신 단일 FC layer를 사용한 factor model (보라)
실험 결과 RNN대신 MLP를 사용할 경우 시간이 지남에 따라 지속적인 distribution mismatch가 생김.
Multitask output은 treatment distribution을 파악하는데 도움은 되나 큰 영향을 주는것은 아님을 확인.
즉, factor model에 RNN아키텍처를 사용하는것이 hidden confounder의 시간 의존적인 특성을 캡쳐하는데 있어 중요하며, 현재 스텝의 covariates와 confounders가 잘 명시될 경우 treatment distribution을 학습할 수 있다고 결론.
6.3. Deconfounding the Estimation of Treatment Responses over Time
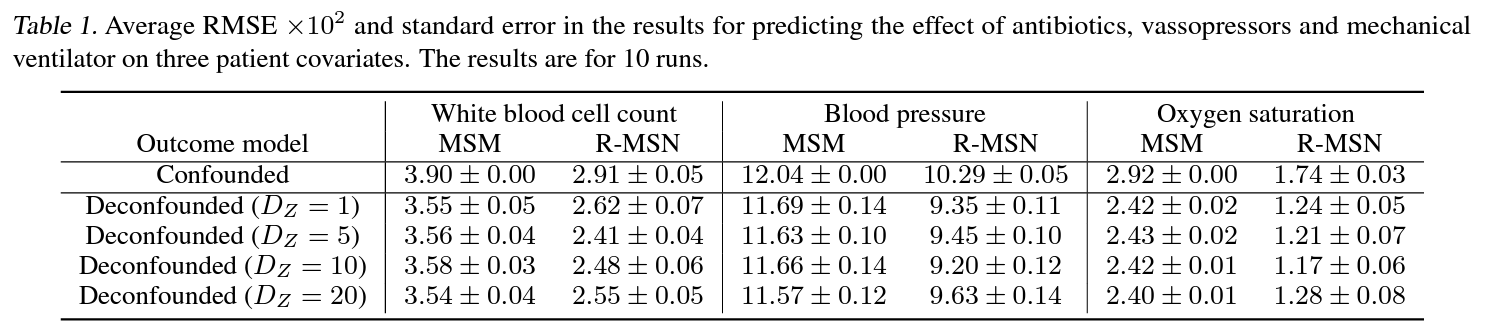
Time Series Deconfounder가 confounder에 의한 bias를 잘 deconfounding하는지를 다음의 두 outcome model을 사용하여 검증함.
Standard Marginal Structural Models (MSMs) - Logistic regression으로 구한 inverse probability of treatment weighting(IPTW)을 사용하여 confounder가 balance된 pseudo-population을 생성하는 단계와, 이렇게 생성된 pseudo-population으로부터 treatment reponse를 linear regression하는 단계의 두 가지 스텝으로 구성된 selection bias 대응방법. - 이름에서 'marginal'은 counfounder control의 의미이며, 'structural'은 potential outcome framework를 의미함. - MSMs에 대한 자세한 내용은 다음 두 강의를 참고 (https://www.youtube.com/watch?v=7NjIQTzADgQ) (https://www.coursera.org/lecture/crash-course-in-causality/marginal-structural-models-EUpei)
Recurrent Marginal Structural Networks (R-MSNs; Lim et al., 2018) - MSMs와 접근은 같지만 RNN을 사용하여 propensity score를 추론하고 treatment response 역시 RNN을 사용하여 추론하는것이 차이. - $\mathrm{RNN}(\overline{\mathbf{X}}_t,\overline{\mathbf{Z}}_t,\overline{\mathbf{A}}_t)$ 와 같이 구현하며, RNN을 사용하여 추정한 propensity weights에 따라 weight를 각 환자에 주어 loss함수를 계산.
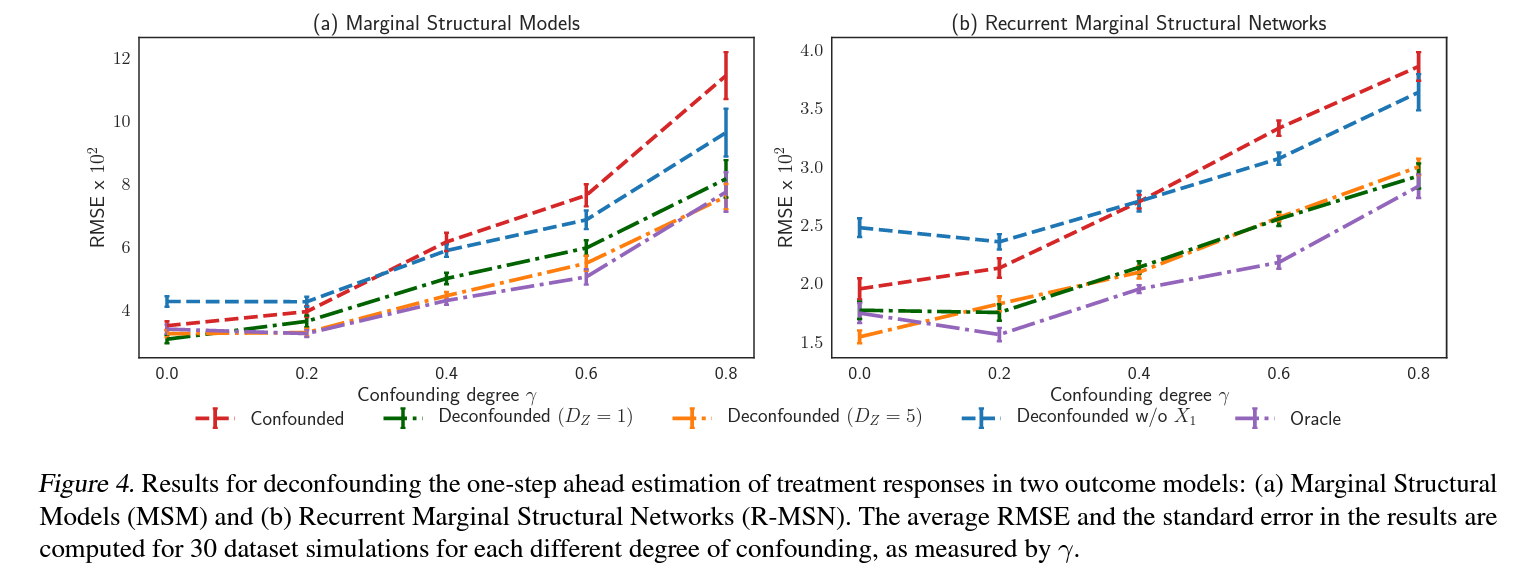
평가를 위해 한 스텝 다음의 treatment response를 예측하는 테스크를 사용하였으며, 두 outcome model에 대한 자세한 분석을 위해 아래 5가지 경우를 비교 1) Confounded: hidden confounder를 고려하지 않고 관측데이터를 그대로 사용한 경우. 2) Deconfounded ($D_z=1$): 실제 hidden confounder의 크기인 1과 동일한 크기의 latent variable $\hat{\overline{\mathbf{Z}}}_t$를 사용한 경우. 3) Deconfounded ($D_z=5$): 실제 hidden confounder의 크기인 1과 다른, 크기 5의 latent variable $\hat{\overline{\mathbf{Z}}}_t$를 사용한 경우. 4) Deconfounded w/o $X_1$: Assumption 3를 위반한 경우로 single cause confounder $X_1$를 covariate에서 제거하여 hidden confounder로 가정한 경우. 5) Oracle: 합성데이터에서의 실제 ground truth hidden confounder $\overline{\mathbf{Z}}_t$를 outcome 모델에 넣어준 경우.
위 결과 그래프를 보면 Deconfounded에서 Confounded보다 Oracle과 유사한 결과를 보여주어 Time Series Deconfounder가 treatment response에 대해 unbiased estimation을 하는것을 확인함.
Deconfounded 두가지 경우, 서로 크게 차이나지 않는데서 hidden counfounder 크기에 대한 model misspecification과 관계없이 robust한 결과를 확인함.
Single hidden confounder가 있을 경우엔 bias를 해결하지 못하는데서 Assumption3가 중요하단것을 확인함.
5가지 경우 모두 RNN기반의 R-MSNs가 MSMs보다 뛰어난 정확성을 보여줌.
7. Experiments on MIMIC III
Time Series Deconfounder를 실제 데이터에 대한 검증을 위해 EHR 오픈데이터인 MIMIC III의 6256명의 환자 데이터에 적용함.
특히 폐혈증 환자에서 항생제, 혈압상승제, 기계식 호흡장치의 총 3 가지의 treatment가 백혈구 개수, 혈압, 산소포화도의 각 3 가지 response에 어떻게 영향을 미치는지를 실험.
실제 데이터인만큼 폐혈증 외의 질병에 대한 cormorbidity나 몇 lab test가 기록에 없다던지의 hidden confounder가 존재하며, Oracle 경우를 확인 불가능함.
3 가지 response실험 모두에서 Confounded보다 Time Series Deconfounder를 적용할 경우 정확도가 상승하는것을 확임함.
합성데이터에서와 마찬가지로 RNN기반의 R-MSNs가 MSMs보다 뛰어난 정확성을 보여줌.
추후 의료진의 의견을 참고한 심층된 검증 필요.
8. Conclusion
관측된 시계열 환자 데이터에서 individualized treatment effect를 추론하는 기존 방법들에선 모두 hidden confounder가 없다는 가정을 했으나, 시계열 데이터에선 시간에 따라 환자의 상태가 계속 바뀌는데가 treatment를 결정하는 복잡도가 올라가 특히나 더 비현실적인 가정임.
이에 본 연구에선 hidden confounder를 대체가능한 latent variable을 추론하는 Time Series Deconfounder를 제안하고 RNN, multitask output, variational dropout을 사용하여 구현함.
합성데이터와 실제데이터를 사용하여 multi-cause hidden confounder가 있을때의 Time Series Deconfounder의 bias 제거 효과를 보여줌.
9. Appendix
(Table 3.) Hidden confounder가 treatment와 outcome에 미치는 영향이 커질수록, 더 큰 capacity의 모델이 필요.
(D.2) RNN기반의 treatment effect estimation이 시간에 따라 변화하는 treatment policy에 보다 robust.
(Figure 6.) 실제 hidden confounder의 갯수와 같게 $D_Z$를 설정하거나 overestimate할 때 treatment response에 대한 예측도가 향상함.
박지용 교수님께서 기획하신 2021년 인과추론 써머세션에서 김예진 교수님께서 강의해주신 Heterogenous Treatment Effect Estimation using ML 세션을 정말 재밌게 들었는데, 이에 대한 튜토리얼 및 벤치마크 논문이 워킹페이퍼로 공개되었다. 논문을 보면 필요한 용어에 대해 상세히 정의해두었고 특히 예시를 정말 잘 활용하고 있어서 처음 causal inference를 접하는 사람들에게 너무 좋은 내용이다.
아래는 줌으로 실강을 듣고나서도 여러번 반복해서 더 들은 김예진 교수님의 강의. 이런 좋은 강의를 한국어로 들을 수 있다니 두 교수님께 감사하다.
PEARL, VariBAD와 같은 inference based meta-RL의 structured (graphical) representation 버전
World-model의 multi-task/meta RL 버전
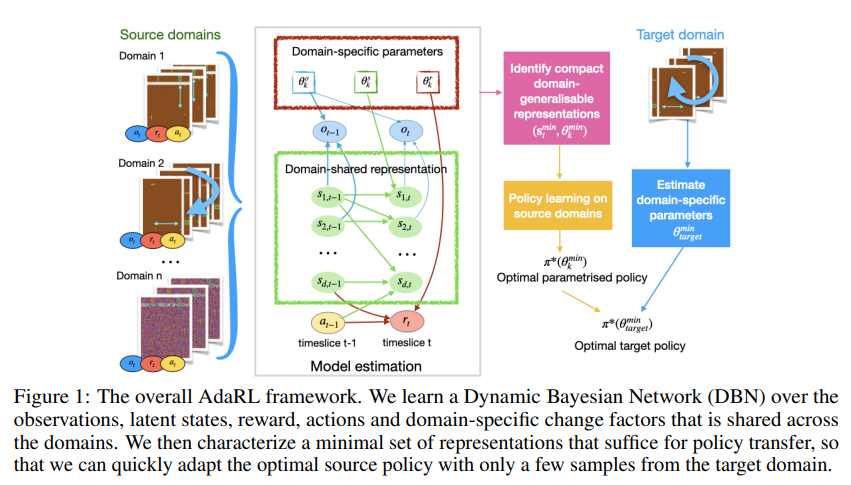
기존의 방법들이 implicit latent task varible을 inference하는 구조였다면, AdaRL은 이를 task간의 domain-shared latent state $s_t$와 domain-specific change factor $\theta_k$ 로 나누어 explicit한 inference를 함
이를 가능하도록 학습하기 위해 두 time step동안의 state dimension, action, reward 그리고 이들에 영향을 주는 domain specific parameters $\theta_k$사이의 상호관계 graph를 아래와 같이 가정
여기서 $c$는 그래프에서 각 요소 사이의 edge에 대한 mask parameter이며 이로 인해 최소한의 필요한 representation만 남음
이러한 latent variable를 inference하는 encoder와 각각의 edge들을 end-to-end 학습하기위해 VAE (MiSS-VAE; Multi-model Structured Sequential Variational Auto-Encoder)구조를 제안하여 사용
이렇게 구한 explicit한 compact latent variable만 있으면 policy를 학습하기에 충분하다는것을 appendix에서 증명
알고리즘의 검증은 Cartpole과 Atari Pong에서 진행
explicit한 task representation덕분에 다양한 task의 variation에서 in/out of distribution 모두에서 기존 알고리즘들보다 비슷하거나 효율적인것을 확인
개인적인 생각
explicit하게 task representation을 나누어 학습하는것이 좋다. graph를 사용하여 이를 학습가능하게 하는부분이 기발하다. 다만 리뷰어도 언급한 부분으로 이걸 저자가 interpretable이라고 부르기엔 이에대한 검증이 부족해 보인다.
지금까지 많은 Meta-RL 논문들이 reward 기반 multiple task에 좀더 집중을 하여 검증을 해왔기에, state dynamics(혹은 transition)이 달라지는 multiple task에 대한 접근은 상대적으로 실험이 부족한감이 없지않아 있었다. 반면 이 연구에선 기존 연구들과 달리 이러한 state dynamics의 변화에 따른 adaptation을 reward보다 더 중점적으로 다룬단 차별점이 있다. 다만 이는 저자의 말에 따르면 reward가 달라지는 task에선 20~50 step의 적은 sample만으론 adaptation이 어려워서가 이유이기도하다.
같은 맥락에서 리뷰어도 이야기를 한 부분인데, state dynamics에 잘 adaptation하는 알고리즘이라면 그 장점을 더 잘 보여줄 수 있게 locomotion과 같은 task에서도 검증을 했다면 어떨까 싶다.
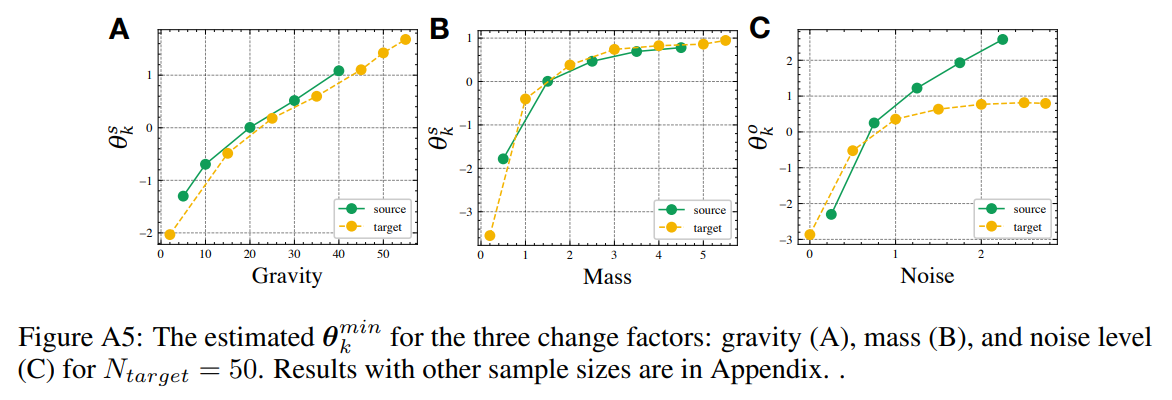
실제로 이렇게 structured latent estimation을 할 경우 단순히 baseline대비 성능이 좋다는 내용만 본문에 써둔게 아쉽다. 실제 추론된 $\theta_k$의 검증은 appendix에 있는데, 환경의 물리적 변화와의 연관성이 충분히 보이고 있어서 제안하는 structured self-supervised approach의 유효성을 어느정도 입증하고 있다.
Cartpole에서 실제 물리적 변화에 따른 추론된 latent variable의 경향성
policy optimization이 필요없는 meta-adaptation을 강조하고 있는데, 이는 VariBAD나 PEARL과 같은 inference based meta-RL들에서 이미 보여준 부분이긴하다. 리뷰어도 언급한 부분인데 이 inference에 대한 설명이 본문에 안보여 Appendix를 읽기 전엔 이해가 다소 어렵다.
domain index $k$를 input으로 사용하는 부분이 multi-task RL의 색깔이 있기때문에, meta-RL관점에서 이 알고리즘이 generalization이 잘 될지도 궁금하다.
알고리즘이 좀 복잡하다. 상당히 많은 notation이 본 paper와 appendix에 섞여 있어서 어렵긴 하나, 이론적 증명이 탄탄한것이 큰 장점이어서 높은 rating을 받은듯하다.
저자들이 causal reinforcement learning을 연구한 사람들이라 structural causal model의 개념을 도입한것 같다.
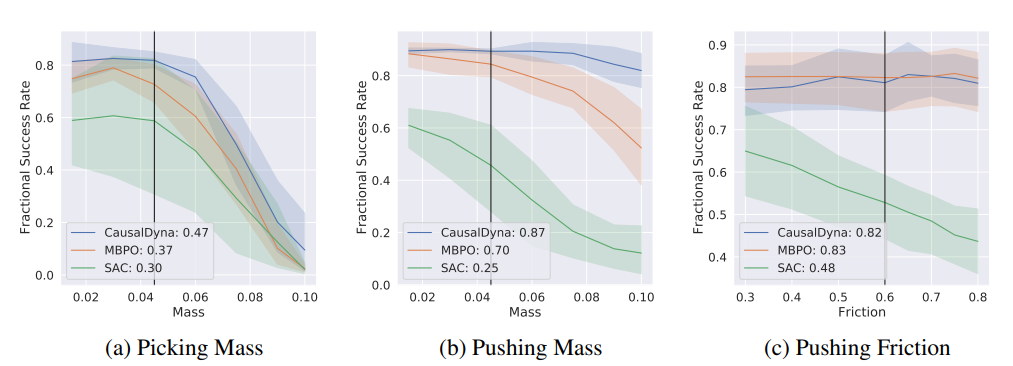
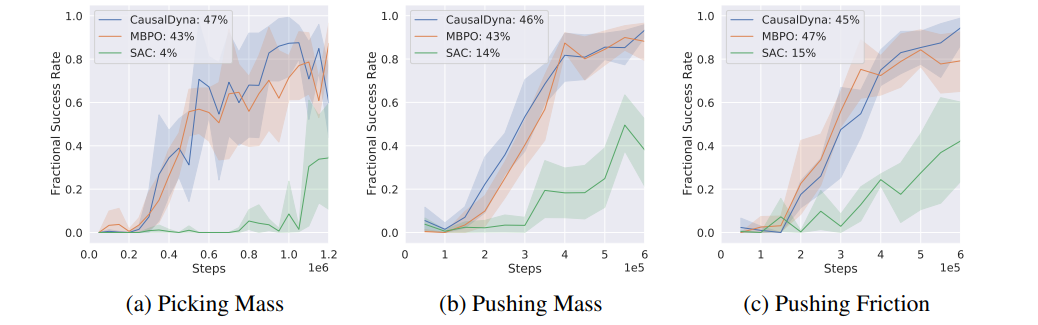
질량과 마찰력에 대한 OOD 조건에서 실험결과 기존 model-based RL 및 model-free RL 알고리즘 (MBPO & SAC)보다 더 나은 task generalization 및 sample efficeincy를 보여줌
또한 학습조건의 질량과 마찰력이 한쪽으로 쏠린 unbalanced distribution (90:5:5)에서도 다른 알고리즘 대비 더 나은 generalization 및 sample efficient한 성능을 보여줌
개인적인 생각
model-based RL이 real world에서 쓰이기위해 꼭 필요하다고 생각했던, 그리고 causal inferece의 인기를 생각하면 조만간 나올거라 생각했던 counterfactual performance를 다룬 연구라 반가웠다.
다만 다른 몇몇 casual inference연구의 결과에서도 그랬지만, 이 연구도 모델에 counterfactual property에 대한 loss가 따로 들어가지 않는 경우라 생성된 counterfactual data에 대한 신뢰성이 사실상 없다. (21.11.09 코멘트: 그래서인가 오늘 공개된 openrewiew에서 5353점을 받았다.)
Structured casual graph를 쓰는만큼 앞으로는 더욱 inductive bias를 잘 활용할 수 있는 방향으로, 그래서 학습된 world model이 실제 환경의 dynamics에 대한 근본적인 이해를 바탕으로 만든 causal inference가 접목되지 않을까 싶다.
이 논문은 multi-task RL과 그 연장선으로 볼 수 있는데, meta-learning에도 causal inference를 접목하는 연구가 general intelligence를 최종 목표로하는 분야의 특성상 곧 나올것 같다.
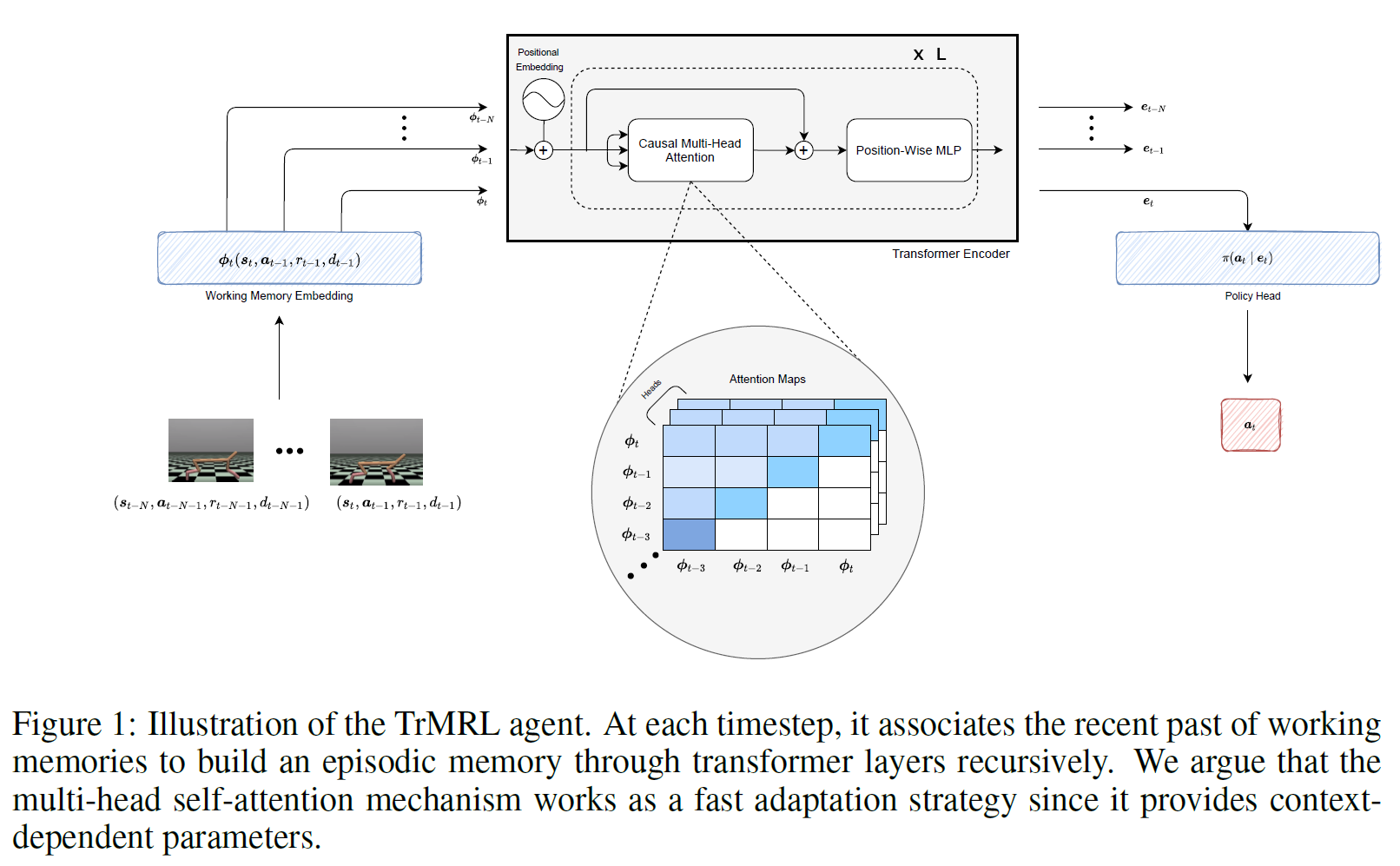
기존 memory based meta-RL의 대표 알고리즘인 RL2에서 RNN을 Transformer로 대체한 버전의 알고리즘
Transformer의 구조가 왜 meta-learning에 부합하는지 신경과학적으로 해석함
한 transition의 embedding은 감각에서 들어오는 신경과학에서의 working memory로 보고, 이 들에 attention mechanism을 적용한 것을 신경과학에서의 reinstatement mechanism와 같다고 하며 Transformer 각 step의 output이 episodic memory에 해당한다고 해석
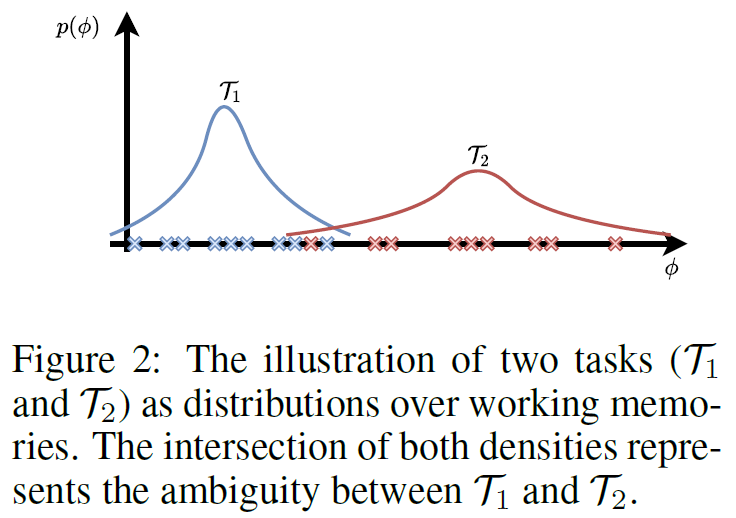
즉, 이러한 working memory들이 episodic memory로 합쳐지고 무엇보다 이게 task 분포를 proxy한다고 가설
RNN보다 Transformer의 sequential representation 능력이 좋기 때문에, MetaWorld에서 RL2의 상위호완 성능을 보여줌
새 step이 들어올때마다 Transformer의 input을 queue처럼 사용하기때문에, 사실상 RNN과 같이 쓸 수 있어 RL2, VariBAD와 같은 online adaptation이 가능한 알고리즘
Episodic adaptation인 MAML이나 PEARL에 비하면 매우 빠른것이 장점
OOD에서는 PEARL이나 MAML보다 TrMRL 및 RL2가 높은 성능을 보여주어 보다 효과적인 representation을 생성함
Working memory가 각 Task에 대해 잘 분리 된다는것을 latent visualization으로 보여줌
개인적인 생각
RL2에서 RNN을 Transformer로 바꾼것이 사실 이 연구의 알고리즘적인 contribution이다. 하지만 RNN을 Transformer로 대체하는건 사실 다른 분야에선 더 이상 contribution이 되지 못한다. (21.11.09 코멘트: 오늘 공개된 openreview 점수가 역시나 5533이다) 그래서 그런지 Transformer의 평범한 구조들에 대한 meta-learning측면의 신경과학적인 해석에 공을 상당히 들였다.
Reward signal만으로 capacity가 큰 Transformer까지 end-to-end로 학습하는구조라 학습이 매우 어렵다. 특히 episodic memory중에서 1개로만 policy loss가 back prop 들어가는 구조라 충분히 학습이 되려나 싶었는데 나름 성능이 좋다고해서 신기하다. 하지만 역시나 학습이 불안정하다는걸 강조하며 Ad hoc으로 network initializaton이 쓰인다.
알고리즘과 환경의 특성상 "Metaworld가 아닌 Mujoco에선 PEARL이 더 performance가 좋을것 같은데 figure가 안보이네"라고 생각하며 읽었는데, 역시나 Appendix로 빼둔것이었고 PEARL이 압도적으로 잘된다. 논문을 쓰는 전략적인 측면에선 나름 알고리즘을 돋보일 수 있는 실험들 위주로 잘 배치한 것 같긴하지만 리뷰어들의 의견이 궁금하다. (21.11.09 코멘트: 오늘 공개된 openreview 점수가 역시나 5533이다)
이 논문에선 episodic memory가 task를 proxy한다고 가설을 세웠다. 하지만 정작 task를 구분하는 loss가 없어서 어찌될지 궁금한데, episodic memory의 latent space를 visualized한 결과를 안보여줬다. Reward기반의 task들이라 linear한 구분이 당연히 잘 될 수 밖에 없는 working memory의 latent space만 visualization해서 task구분이 되는듯하다고 써둔것이 아쉽다.
OOD에 대한 해석에서 memory based 알고리즘이 optimization based나 context based 알고리즘보다 더 representation이 효과적이라고 했으나, 개인적으론 memory based 알고리즘 역시 (혹은, 특히나) generalization에 대한 loss가 딱히 없기 때문에 잘못된 해석인것 같다. 실제로 MAML, PEARL보다 높다 뿐이지 해당 halfcheetah에서의 score를 보면 제대로 동작한다고 보긴 어려워, RL2 및 TrMRL에 의해 형성되는 task latent space의 명확함이 오히려 떨어져서 생기는 현상이라고 생각된다.