
Author : Kate Rakelly*, Aurick Zhou*, Deirdre Quillen, Chelsea Finn, Sergey Levine
Paper Link : https://arxiv.org/abs/1903.08254
Talk in NeurIPS2020 Workshop: slideslive.com/38938215
0. Abstract
- 기존의 meta-RL (meta-Reinforcement Learning)은 on-policy 기반으로 샘플링이 비효율적이거나, task의 불활실성에 대한 구조적인 탐색이 불가능함
- 이에 policy와 별개로 task inference가 가능한 off-policy 기반의 meta-RL 알고리즘을 제안함
- 제안된 방법은 gradient step없이 task의 확률이 online으로 도출 가능하며, 기존의 meta-RL 알고리즘 대비 20~100배의 샘플 효율성을 보여줌
1. Introduction
- 현재 대부분의 meta-RL은 meta-training과 adaptation에서 모두 on-policy data를 필요로 함
- Adaptation은 새로운 task에대한 빠른 학습을 특징으로 하여 on-policy가 큰 문제는 아니나, meta-training에서의 on-policy training은 매우 낮은 샘플 효율성을 야기하므로 off-policy RL을 meta-training에 적용할 필요가 있음
- 하지만 meta-training과 meta-test의 adaptation 데이터 구조가 일치해야하는 근본적 제약으로인해 off-policy meta-RL은 근본적으로 어려움
- 이에 이 연구에서는 meta-RL을 context connoted blackbox 나 bi-level optimization의 adaptation과 policy가 결합된 구조로 보는 기존의 접근과 달리, inference problem으로 해석
- 즉, meta-training동안 데이터의 posterior를 먼저 inference하도록 probabilistic encoder를 학습하며 이를 토대로 policy가 task를 수행
- 마찬가지로 Meta-testing에선 학습된 encoder에 의해 새로운 task의 latent variable을 inference한 뒤 이를 바탕으로 policy의 구조적인 탐험 및 빠른 adaptation을 수행
- 이와같이 task inference가 policy로부터 분리된 구조는 meta-policy의 exploration 및 optimization 과정 없이도 online task inference를 가능하게 함
- 또한 분리된 학습으로 인해 meta-training의 데이터 구조와 meta-test 데이터 구조가 달라도 돼 off-policy meta-RL을 가능하게 함
- 즉, policy는 off-policy RL로 효율적으로 최적화 되는 반면, encoder는 on-policy data를 사용해 task inference를 학습하고 수행함으로써 meta-training과 meta-test사이의 불일치성을 최소화
- 저자 Kate Rakelly는 이 알고리즘을 probabilistic embedding for actor-critic RL (PEARL)이라 명명
(github도 이름을 oyster 로 지은걸 보면 재밌는 이름이긴 하나 사실 와닿진 않는듯 하다)
2. Related Work
a) Meta-learning:
- 새로운 task를 빠르게 학습하는것을 목표로 하는 meta-RL은 크게 context-based meta-RL과 gradient-based meta-RL로 나눌 수 있음
- Context-based 방법은 수집된 데이터로 부터 task의 latent representation을 학습하고 이를 policy의 condition으로 사용하는것으로, 주로 RNN을 사용
- Gradient-based 방법은 빠른 초기 학습을 학습하는 bi-level optimization으로, on-policy 데이터 기반의 policy gradient를 사용
- PEARL은 context-based 기법이나 RNN대신 encoder를 사용했으며, gradient-based 기법과 달리 off-policy 데이터를 사용하는 차이가 있음
b) Probabilistic meta-learning:
- Probabilistic model을 supervised learning혹은 reinforcement learning 에 적용하는 연구는 많이 있어옴
- PEARL은 특히 task의 uncertainty를 확률분포로 표현하는 probabilistic latent task variable을 활용
c) Posterior sampling:
- RL에서의 posterior sampling은 측정한 MDPs 데이터에 대한 posterior을 샘플링하고 시간적으로 과거의 경험과 겹치지 않는 최적의 행동을 새롭게 탐색하는것을 의미
- PEARL은 이 posterior samping을 meta-learning의 관점으로 해석하여, 과거 경험한 task의 uncertainty를 확인하고 새로운 task를 구조적으로 탐색하는데 활용
d) Partially observed MDPs:
- Task를 state에 포함된 개념으로 본다면, uncertanty가 높은 task를 기본 배경으로 하는 Meta-RL은 일종의 partially observed MDPs (POMDP)로 볼 수 있음
- PEARL은 새로운 task에 대한 probabilistic belief inference를 위해, POMDP 문제에 사용되는 variational 접근을 활용.
3. Problem Statement
- Meta-RL은 기존의 task들로 부터 meta-policy를 학습하는 meta-training과, 학습된 meta-policy로부터 빠르게 새로운 task에 적응하는 adaptation 의 두가지 반복 loop로 구성됨
- Adaptation의 샘플링 효율은 meta-RL의 본질과 부합하므로 큰 문제 없으나, meta-training에서의 샘플링 효율은 기존의 RNN, policy gradient 방식의 on-policy기반 알고리즘으론 매우 낮음
- 이는 Real world에 meta-RL을 적용하는데 있어서도 큰 장애물이 됨
- 이에 저자는 off-policy meta-training 알고리즘을 제안함
- Task의 정의는 다음과 같음

- 이 3가지 요소 중 어느 하나라도 다르면 다른 task로 간주
- 실직적으로 task를 바탕으로 수집된 데이터는 그 task를 상징하는 context $c$라는 추상적 개념을 가지고 있다고 보며 명시적으로는 하나의 MDP transition으로서 다음과 같이 표현
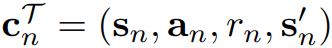
- 이때, Meta-RL은 transition distribution과 reward function을 모르는 상황에서 training task들을 학습하여 새로운 task를 마주했을때 빠르게 policy를 찾는 문제
4. Probabilistic Latent Context
- task의 최근 context로 task에 대한 latent probabilistic context variable $Z$를 추론 했을때, 이 latent variable을 조건으로한 policy $\pi_{\theta}(a\mid s,z)$ 를 최적화 하면서 얼마나 성능이 좋은지를 바탕으로 $z$가 적절히 추론되었는지를 판단
4.1. Modeling and Leanring Latent Contexts
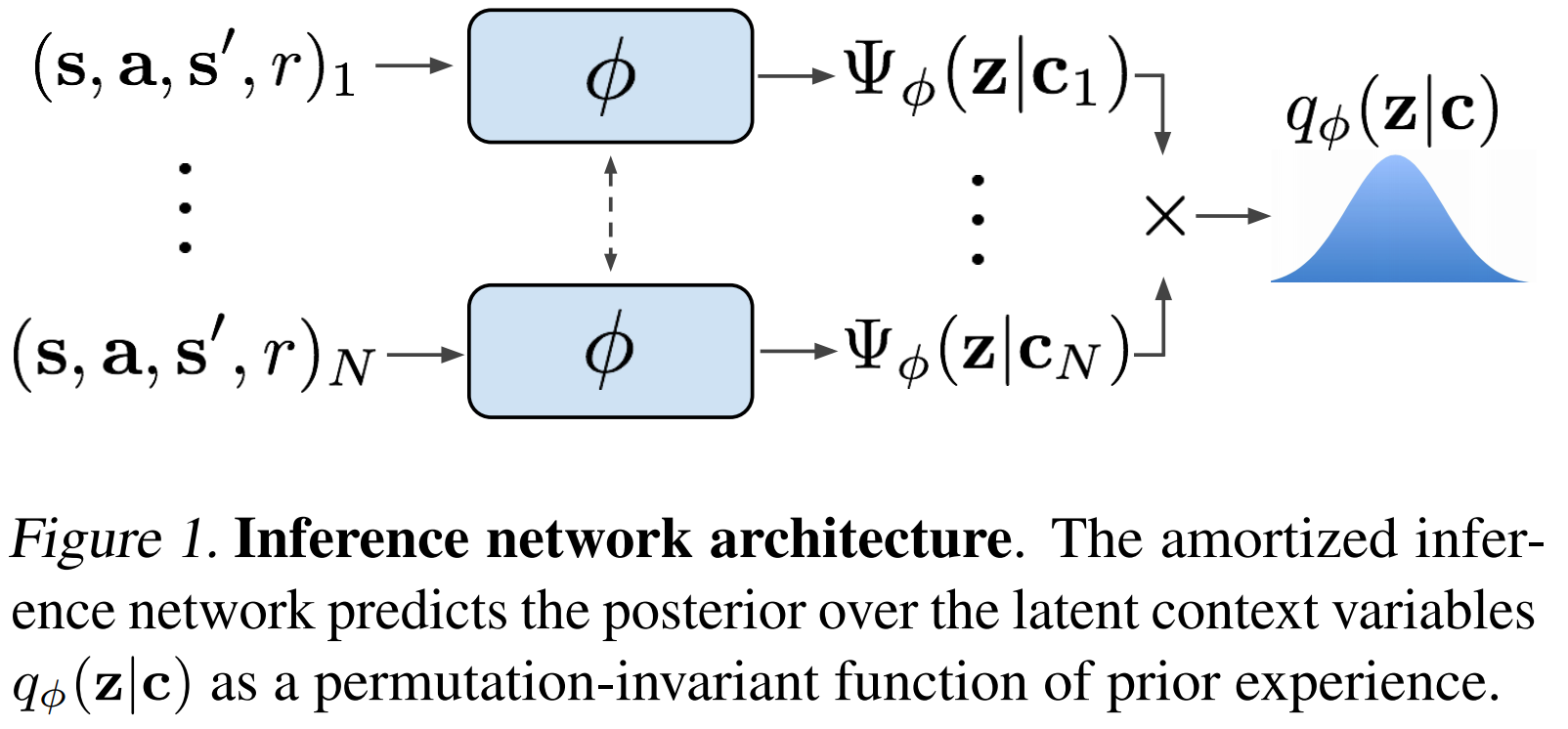
- Inference $Z$ 를 학습하기위해 variational auto encoder (VAE)의 구조를 사용
(VAE는 유재준 박사님의 포스팅이나, 이기창님의 포스팅 참고) - Context $c$가 주어졌을 때 poeterior $p(z \mid c)$를 추정하는 inference network $q_{\phi}(z \mid c)$ (encoder)를 학습
- Decoder의 generative 기능에 따라, $q_{\phi}(z \mid c)$는 $z$로부터 MDP의 복원을 목적으로 최적화할 수 있음
- 유사한 변형으로서, model-based RL개념의 MDP복원이 아니라 model-free RL의 개념을 차용하여 Q나 Return을 최대화 하도록 $q_{\phi}(z \mid c)$를 최적화 가능
- VAE의 개념을 가져왔으므로, PEARL의 목적함수 역시 VAE의 목적함수(ELBO)와 유사하며 다음과 같음
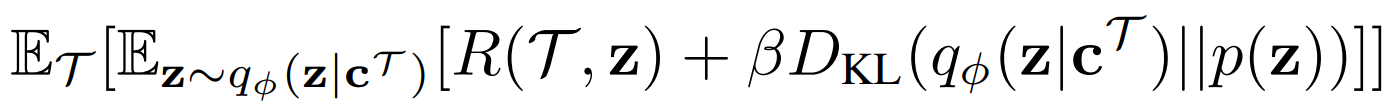
- ELBO의 형태에 따라 첫번째 항은 reconstruction term이며, 두번째 항은 variational prior에 대한 regularization term
- $R(\tau, z)$는 위에 언급한 대로 model-based 혹은 model-free 접근에 따라 다양한 reconstruction objective를 선택 가능
- PEARL에서는 $p(z)$를 z에대한 unit Gaussian 형태의 prior로 가정하며, regularization term에 따라 information bottleneck의 역할을 하여 현재 task에 대한 meta-overfitting을 완화함
- Meta-test에서는 추가적인 gradient step 없이 encoder를 사용한 새로운 task에 대한 latent context의 단순한 online inference만 필요함
- 만약 task가 fully observed MDP라면 단일 transition만으로도 context를 충분히 내포하고 있으며 따라서 transition sample간의 순서는 관계 없는 permuation invariant 성질을 만족함
- 이에, posterior는 각각의 단일 transiton을 inference한 posterior의 distribution multiplication으로 modeling됨

- 실제 구현에서는 encoder의 output으로 mean과 standard deviation을 inference한 후, 이를 파라메터로 갖는 normal distribution을 posterior로서 도출함

- 지금까지의 inference network 구조를 그림으로 표현하면 다음과 같음
4.2. Posterior Sampling and Exploration via Latent Contexts
- Posterior sampling, 즉 현재 task에 대한 belief에 따른 optimal acting은 동일한 분포의 랜덤한 행동을 반복해서 하는것이 아니므로 시간적으로 구조화된 탐색을 하는 장점을 가짐
- 단, 기존의 RL에서의 posterior sampling과 달리 PEARL에서는 VAE를 썼기때문에 MDP/Return/value 등 다양한 최적화를 위한 poterior를 직접inference 가능
- 새로운 task에 대해서는 prior에서 $z$를 샘플링 한 후 이에 대한 acting을 하며, 그 결과로 얻어진 context에 따라 현재 task의 posterior를 다시금 inference함
- 이 과정을 반복하면 현재 task 에 대한 belief가 범위가 좁혀지고, 따라서 더 적절한 optimal action을 취할 수 있음
- 이러한 posterior sampling을 통한 acting 구조는 그림으로 다음과 같이 표현 됨

5. Off-Policy Meta-Reinforcement Learning
- 현대 meta-RL에선 adaptation에 사용되는 데이터의 구조가 meta-training과 meta-test 둘 사이에 일치(in distribution) 해야한다고 가정함
- 때문에 RL의 특성상 meta-test의 adaptation이 on-policy 로 이루어짐에 있어, meta-training도 샘플 효율이 낮은 on-policy를 사용해야하는 제약이 생김
- 또한 경험을 바탕으로 task distribution을 추론하는 stochastic 탐색을 배우는것은 meta-RL을 더욱 효율적으로 만드는데, 이는 policy가 stochastic distribution을 바탕으로 행동을 조작할 수 있어야 가능함
- 따라서 이는 단순히 true value function을 근사하는 off-policy RL은 불가능한 반면, policy 자체를 근사하는 on-policy RL은 가능함
- 이러한 두가지 종합적 이유로, off-policy RL을 meta-RL에 접목하는것은 필요하지만 쉽지 않음
- 논문의 contribution으로서, PEARL 알고리즘은 위 한계점을 해결하기위해 task distribution inference 구조는 encoder가 하도록 분리하고 poilicy의 학습과 encoder의 학습이 다른 데이터를 사용해도 되도록 설계
- 이로서 encoder가 on-policy data로 학습을 하여도, policy는 off-policy RL loop의 일부로서 $z$를 다룰 수 있게 됨
- 또한 탐색을 위해 필요한 stochasticity 역시 encoder $q(z \mid c)$ 로 추가할 수 있음
- 구체적으로, Actor와 Critic은 replay buffer $B$로부터 off-policy 데이터를 샘플링하여 학습을 진행
- Encoder는 샘플러 $S_{c}$에 의해 샘플링된 context batch를 학습
- 이때 $S_{c}$가 전체 버퍼에서 샘플링을 할 경우 off-poicy 가 되어 on-policy meta-test와의 너무 큰 차이가 생김
- 하지만 encoder를 사용할 경우 strict on-policy를 지키지 않아도 된다는 장점이 있는데, on-policy와 off-policy 중간 정도 되는 접근으로서 최근 수집된 데이터를 통해 inference를 하는것은 on-policy 데이터를 사용하는것과 성능의 차이가 없다는 것을 저자는 확인함
- 지금까지의 PEARL을 알고리즘으로 정리하면, meta-training 및 meta-test는 각각 다음과 같음


5.1. Implementation
- PEARL은 model-free off-policy RL알고리즘인 soft actor-critic (SAC)기반으로 구현 (SAC의 자세한 설명은 이전 포스팅 Soft Actor-Critic (Haarnoja, 2018) 정리 참고)
- SAC는 off-policy 알고리즘으로서 효율적인 데이터 샘플링 및 안정성을 보여주며 poilicy자체가 probabilistic하게 표현돼 probilistic latent context와의 결합이 용이
- PEARL의 구현에선 inference network $q(z \mid c)$의 파라메터를 actor $\pi_{theta}(a \mid s, z)$와 critic $Q_{theta}(s,a,z)$의 파라메터와 결합하여 한번에 backprobagation으로 학습하기위해 reparameterization trick을 사용
- 이는 샘플링을 포함하는 연산그래프에서 랜덤노드를 분리해주는 것으로, 자세한것은 유재준 박사님의 블로그를 참조
- 이 같은 학습구조로 crtic의 학습으로서 $Q$의 복원값을 Bellman update와 LMS로 학습면서 한번에 gradient가 inference network까지 전달되어 학습 가능 (Chapter4에서 reconstruction은 여러가지가 가능하다고 했으나 MDP 의 복원보다 $Q$의 복원이 더 나은 성능을 보여주는것을 저자는 확인)
- 따라서 critic의 loss fuction은 다음과 같음

- Actor의 loss function은 SAC 원 알고리즘과 거의 동일하며 $\overline{z}$만 input에 추가되어 다음과 같음

- $\overline{V}$은 target value network. $\overline{z}$는 reparameterization trick으로 gradient가 encoder의 파라메터로 전달 되지 않음을 의미
- 여기서 주의할 점은 critic loss에 사용되는 data와 latent variable를 추론하는 $q_{\phi}(z \mid c)$ context가 다르다는 것
- Context 샘플러 $S_{c}$는 완화된 on-policy로서 최근 수집된 데이터에서 uniformly 샘플링 하며, meta-training 을 n번 진행할때마다 한번 context를 inference함
- 한편, actor-critic은 off-policy 샘플링을 위해 전체 replay buffer에서 uniformly 샘플링
6. Experiments
6.1. Sample Efficiency and Performance
- 실험은 총 6개의 Mujoco continuous control 환경에서 수행

- 이 중 5개는 제어 목적이 다른(=reward가 다른) task
- 각각 전진/후진을 목표로 하는 Half-Cheetah
- 각각 전진/후진을 목표로 하는 Ant
- 걷는 방향이 서로 다른 Humanoid
- 서로 다른 속도를 목표로 하는 Half-Cheetah
- 목표 도착 지점이 서로 다른 Ant
- 나머지 1개는 dynamic가 다른 (=transition probability가 다른) task
- 랜덤하게 dynamics 파라메터가 정해지는 2D-Walker

- 비교를 위한 meta-RL 알고리즘은 총 3개 수행
- 이 중 2개는 Policy gradient 기반 (optimization기반)의 알고리즘
- ProMP (Rothfuss et al., 2018)
- MAML-TRPO (Finn et al., 2017)
- 나머지 1개는 Recurrent 기반 (black-box 기반)의 알고리즘
- RL$^2$ (Duan et al., 2016) with PPO (Schulman et al., 2017)
- 실험결과 PEARL이 기존 meta-RL알고리즘보다 20~100배 더 향상된 meta-traning 샘플링 효율을 보여줌
- 또한 기존 알고리즘 보다 50~100% 향상된 성능을 점근선으로 확인 가능 함
6.2. Posterior Sampling For Exploration
- Posterior sampling이 얼마나 효과적으로 task 탐색을 진행하는지를 검증하는 실험을 함
- 이를 위한 환경으로는 reward가 sparse하게 주어지는게 보통 사용되며, 여기서도 마찬가지로 타원을따라 나타나는 파란 원에 도달시에만 reward를 받는 2D navigation 실험을 함
- 비교 알고리즘으로는 기존의 meta-RL 알고리즘 중 PEARL과 같이 구조적인 탐색이 가능한 MAESN (Gupta et al.m, 2018)을 사용

- 실험 결과, optimazation 기반 meta-RL알고리즘과 달리 sparse reward 문제도 해결 가능함을 보여줌
- 또한 같은 구조적 탐색이 가능한 MAESN에 비해 meta-training에서 약 100배 빠른 샘플링 효율성을 보여줌
- (6.3 Ablations는 알고리즘의 구현에 대한 추가적인 검증으로 생략)
8. Limits of Posterior Sampling
- Posterior sampling으로 sparse reward 환경에서도 구조적인 탐색이 가능하지만, 이게 optimal exploration을 의미하는것은 아님
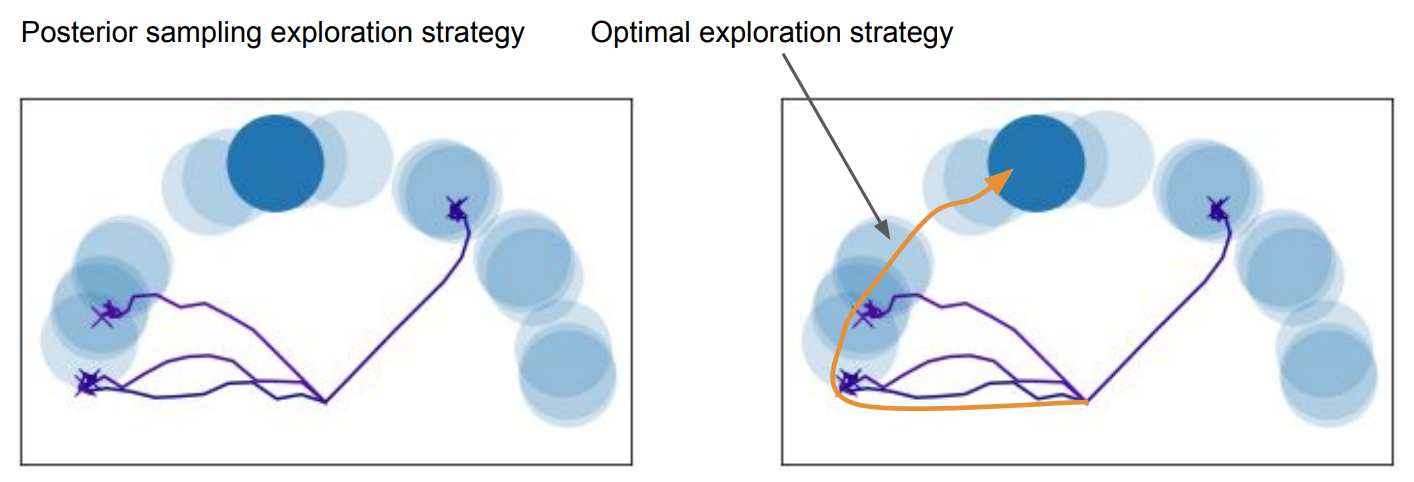
- 실제로 반원을 따라 target이 생긴다면, optimal은 반원을 따라 탐색을 하는것이 가장 효율적인 전략
- 이는 task에 대한 adaptation과 postrior regularization의 순서에 따라 생기는 문제로, task inference를 통해 $z$를 도출 한 후 Normal distribution prior로 posterior를 regularize하면 task의 latent space가 normal distibution으로 제한 됨

- 즉, adaptation은 task간에 그 평균에 해당하는 공통점이 존재하는 경우에 한하여 성능이 좋을것을 예상 가능
- 이러한 문제는 실제로 meta-RL에 대한 벤치마크인 Meta-world (Finn et al., 2019)에서 10개의 task만으로 meta-RL을 진행했을땐 meta-policy의 학습이 실패했으나, 45개의 task를 사용하여 공통점이 충분해 졌을땐 다른 알고리즘 보다 나은 성능을 보여준것에서 확인됨

- 하지만, 전반적으로 meta-RL 알고리즘들의 성능이 나쁨. 이는 탐색이 부족한 문제도 데이터가 부족한 문제도 모델의 capacity가 부족한 문제도 아닌 최적화 기법의 문제인것으로 추측 됨 (스탠포드 Fall19 CS330 lecture10)
- 즉, 다양한 out of distribution인 task familly들에 대해 더 나은 최적화를 가능하게 하는 meta-RL 알고리즘으로의 여지가 아직 많이 남아 있음






















 은 Target Soft Q-function
은 Target Soft Q-function













