Author: Seunghyun Lee*, Jiwon Kim , Sung Woon Park , Sang-Man Jin, and Sung-Min Park
Paper Link: doi.org/10.1109/JBHI.2020.3002022 (Selected as a featured article)
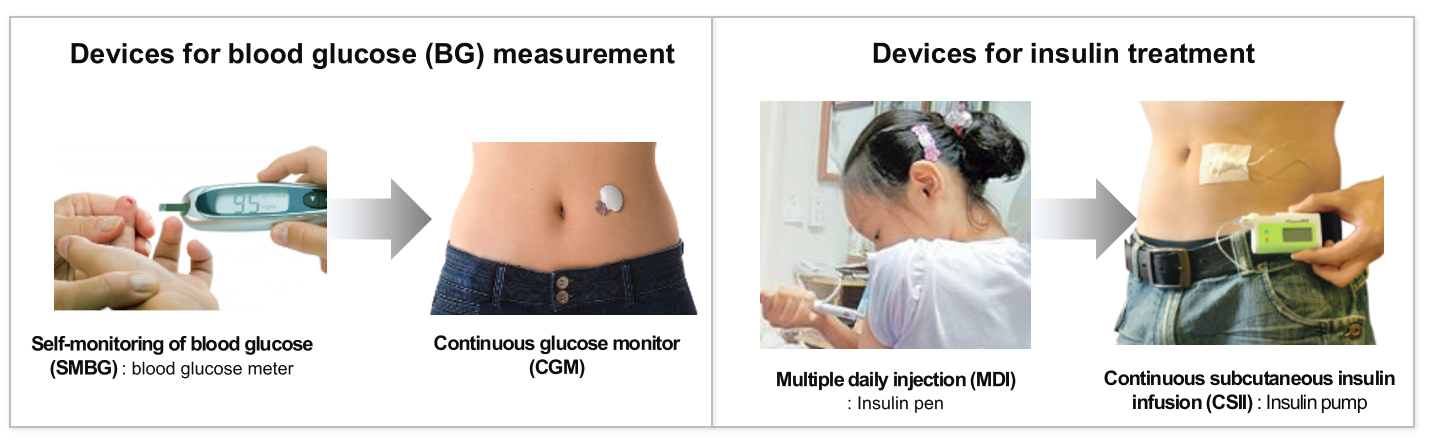
제 1형 당뇨병은 인슐린 분비능이 결핍된 만성질환으로, 외부의 인슐린 주입이 필수적이다. 1920년대 동물의 인슐린을 피하로 주사하는 인슐린 치료법이 등장한 이 후, 줄곧 주사를 통한 주입이 이루어지다 1980년부터 휴대형 인슐린 펌프가 개발되어 주사의 고통이 줄어들기 시작했다. 또한 혈당 측정 역시 채혈기반에서 반침습형 센서로 진화하면서 2000년대 들어서는 바늘로부터의 고통이 많이 줄어들었다.
이 때부터 더 나은 인슐린 주입을 위한 알고리즘이 주목받기 시작했으며, 사람의 췌장 기능을 모사하는 '인공췌장 (Artificial Pancreas)'의 개념이 등장했다. 인공췌장 알고리즘은 기본적으로 자율주행과 매우 비슷하다. 자율주행이 사람의 개입 없이도 운전을 잘하는것이 목표라면 인공췌장은 마찬가지로 사람의 개입없이 혈당조절을 잘 하는것을 목표로 한다. 자율주행이 단계가 있듯이 인공췌장 역시 단계별로 6단계가 정의되어 있으며, 최종적으로 사람의 췌장과 같이 식사량의 수동 입력이 없으며 혈당 상승호르몬 (글루카곤) 과 강하호르몬 (인슐린) 의 상호 조절되는것을 완성단계 (level6)로 본다.
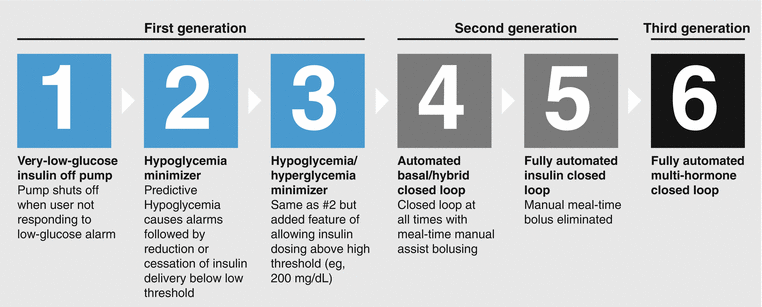
2020년 현재 상용화된 Medtronic사와 Tendom사의 인공췌장 시스템은 level 4 의 인슐린 단일 시스템으로 Hybrid closed loop 시스템이라 불린다. 인슐린은 공복시 분비되는 기저인슐린 (basal) 과 식사시 분비되는 식사인슐린 (bolus) 으로 목적에 따라 분류될 수 있는데, level4는 기저인슐린을 자동화하는 인공췌장 시스템을 말하며 식사량은 여전히 환자가 직접 입력을 해주어야한다. 이 점은 당뇨병 환자들에 있어 매우 불편한 점으로, 본인이 어느정도의 식사를 할지와 그 안에 탄수화물이 얼마나 있을지를 미리 예상하고 식사 전에 인슐린을 주입해야하여 식사 과정이 상당히 제한된다.
level4 이상의 인공췌장의 개발에는 근본적인 한계가 있다.
첫째로, 피하에 주입된 인슐린은 실제 췌장에서 분비되는 인슐린과 달리 약 30~60분 뒤에 약효의 peak를 보여준다. 이러한 큰 delay는 PID 제어 알고리즘과 같은 보편적인 제어만으로는 빠른 대응이 어렵게한다. 특히 식후 혈당은 약 1시간 후까지 상승하므로 이러한 인슐린의 delay를 예측못하고 현재의 혈당 상태에만 의존하여 인슐린을 계속 주입했다가는 인슐린이 혈액에 과다하게 쌓이는 'Insulin stacking (Irl B. Hirsch, NEJM, 2005)' 의 위험이 있을 수 있다. 과다한 인슐린은 저혈당을 유발하며 쇼크사의 위험이 커진다. 이에 최근에는 Model predictive contol (MPC)의 모델기반 예측 알고리즘이 효용성을 보여주었고 사실상 최초의 인공췌장이라 할 수 있는 level4 인공췌장의 상용화를 가능하게 하였다.
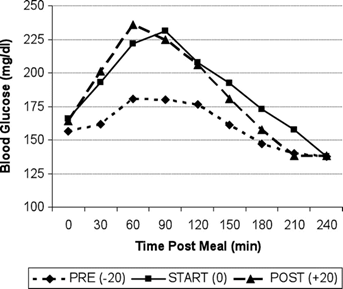
하지만, MPC의 model이 환자의 식사시간과 양을 예측하진 못한다. 그렇다고 식후 혈당상승을 disturbance로 보기에는 그 정도가 너무 크다. 때문에 vanilla MPC는 식사정보를 환자가 매번 직접 입력해야하는 level4 인공췌장의 한계를 가지며, MPC로 식사량 입력도 필요없는 level5를 구현하려면 추가적인 예측 알고리즘이 필요하다.
둘째로, 당뇨병의 배경인 혈당대사는 개인별 편차가 매우 심하다는 점이 문제다. 사람마다 같은 음식을 먹어도 혈당이 상승하는 속도와 정도가 다르며, 같은 인슐린을 넣어도 혈당을 낮추는 속도와 정도가 다르다. 더 큰 어려움은 동일한 사람 내에서도 인슐린의 약효과 시간에 따라, 스트레스에 따라, 운동에 따라, 컨디션에 따라 등등 여러 이유로 계속 바뀐다는 점이다. 때문에 고정된 알고리즘만으론 췌장과 같이 개인에 맞춰 혈당을 조절하는 기능을 갖는 진정한 인공췌장을 구현하기 어렵다.
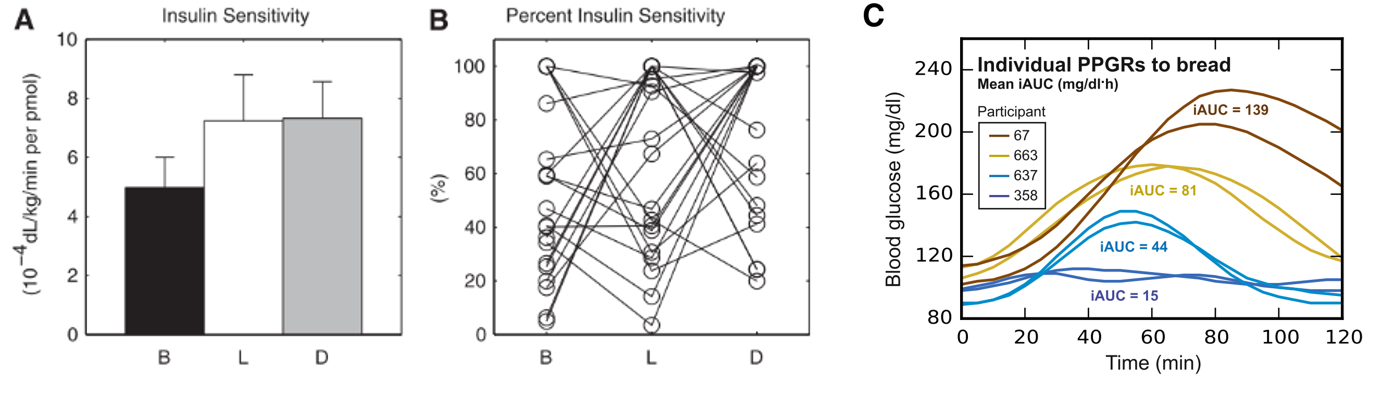
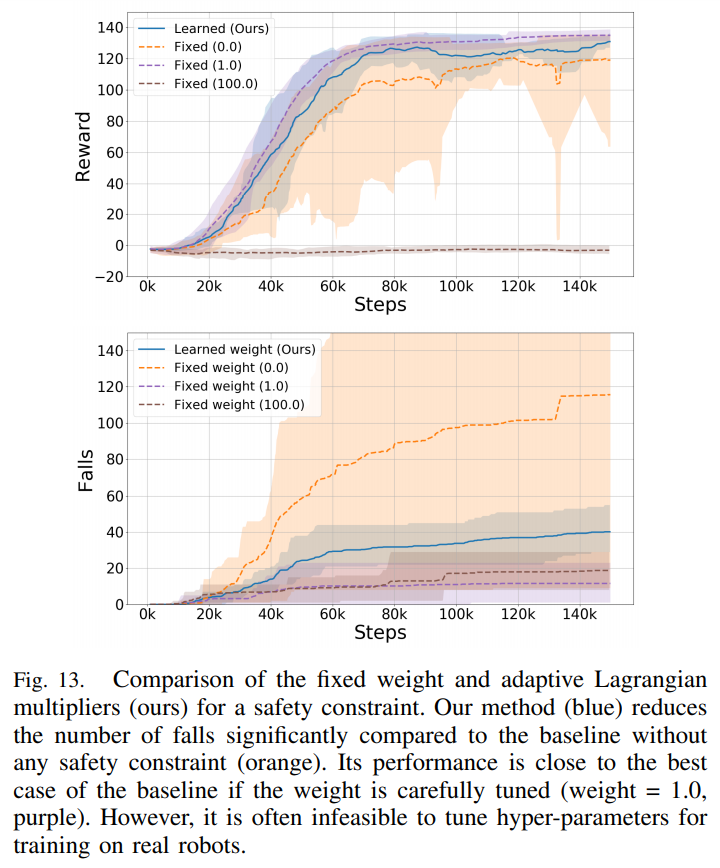
이 논문에서 우리는 이러한 본질적인 두가지 문제를 생체모사형 강화학습 설계 (Bio-Inspired Reinforcement Learning Desing; BIRLD) 방법으로 해결하였으며, BIRLD로 학습된 AI agent는 아무런 식사 정보 없이도 자동화된 인슐린 주입을 보여주는 동시에 저혈당의 발생빈도가 낮았다. 또한 환자의 인슐린 반응성을 바꿔가며 실험을 해도 모두 유사한 혈당 조절을 보여주어 강화학습 알고리즘이 학습을 통해 자동화 및 개인화된 치료가 가능한것을 확인할 수 있었다.
개인적으로 재밌는 부분은, 저혈당이 오기 전에 AI가 알아서 인슐린 주입량을 낮추는 것을 배운다는 것이다. 이러한 판단의 근거를 분석하기위해 Explainable AI 기법인 Layer-wised Relevance Propagation (LRP) anlysis 를 적용한 결과, AI가 체내 인슐린 축적량을 가장 중요한 인자로 보고 인슐린 주입속도를 낮추는것을 확인할 수 있었다.
Comment:
- 이번 연구는 미국 FDA의 동물실험 대체 승인을 받은 가상환자 시뮬레이션 benchmark에서 알고리즘의 검증을 수행한 것으로, 지금은 스마트폰에서 Pytorch Mobile을 사용하여 policy network를 inference하고 실제 동물에 대해 알고리즘이 얼마나 잘 동작하는지를 후속 연구로 진행 중이다.
- IEEE JBHI 2021 2월호에 Featured article로 선정되었다.
당뇨병 관리, 이제는 인공지능으로 한다
강화학습에 약리학 개념을 추가해 완전 자동으로 인슐린이 주입...
news.imaeil.com
- 기사가 난 후 어떤 분이 감사하게도 나무위키에 써주셨다 (https://namu.wiki/w/%EA%B0%95%ED%99%94%ED%95%99%EC%8A%B5)
- 당뇨병 환우회 환자분들의 기대가 크시다. 더 힘내야겠다.
'PERSONAL PROJECTS > Research Publications' 카테고리의 다른 글
| Clinical Decision Transformer: Intended Treatment Recommendation through Goal Prompting (0) | 2023.05.24 |
|---|---|
| IEEE JBHI 논문 featured article 선정 (0) | 2021.07.02 |
| (DMJ, 2019) Computerized Intravenous Insulin Infusion Protocol (0) | 2020.06.29 |